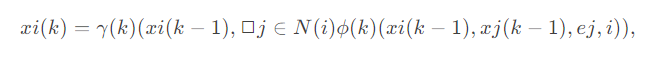开发者学堂课程【高校精品课-北京理工大学-数据仓库与数据挖掘(上):Data-Basic Statistical Descriptions of Data】学习笔记,与课程紧密联系,让用户快速学习知识。
课程地址:https://developer.aliyun.com/learning/course/921/detail/15627
Data-Basic Statistical Descriptions of Data
内容介绍
一、数据集中趋势的测量
二、数据离散程度的测度
对于数据基本的统计描述,我们主要是从数据的集中趋势,离散程度和分布形状三个方面来理解数据。对于我们数据的集中趋势,我们的测量测度主要包含平均值中位数和众数。对于我们数据的离散程度。

我们的测度主要包含极差,4分位差,方差和标准差以及离散系数。对于我们数据的分布形状,我们主要是从峰态和偏态两个角度描述。数据的集中趋势主要指的是这一组数据,它大概的分布位置。数据的离散程度主要指的是数据值的变化趋势。

对于我们 PPT 就主要指的是这个数据下面的开口的大小。数据的分布形状主要指的是数据的峰态和偏态。
一、数据集中趋势的测量
1、平均值测量
首先我们来看一下对数据集中趋势的测量。对数据集中趋势的第一个测量,就是我们的平均值。在我们的 ppt 上,这个是平均值的计算公式。

也就是各个数据值累积起来,然后求平均。除了最基本的平均值的计算,我们还有两种特殊的平均值的计算。第一种就指的是带权重的平均值。在计算带权重的平均值的时候,我们不仅考虑各个属性值的大小。还要考虑属性值的权重。
第二种计算数据平均值特殊的方法就是叫做切尾平均。切尾平均中,我们首先要对数据进行排序。去掉它的最大的部分和最小的部分。对中间的部分取平均。这一点大家在体操比赛中经常容易看到。比如说我们去掉一个最高分,去掉一个最低分。这位运动员最终得分的平均值是多少。
2、中位数测量
好我们再来学习一下中位数。中位数呢就指的是我们对数据排序后。处于中间位置的这个数值的大小。如果我们的数据的个数是奇数。我们就直接可以取中间位置这个数据的值,如果我们的数据的个数是偶数,我们就要取中间两位数据的值,然后取平均。
此外对于分组数据,我们要用插值法用这样的公式去计算我们数据的中位数。我们分别来看一下三个例子。比如,这是9个家庭的收入,我们要求这个家庭收入的中位数。那首先对这九个家庭的收入进行排序,然后取它中间的位置,也就是排序第5个位置上面的值。就是我们的1080就是我们的中位数。

那如果我们对10个家庭取中位数呢?因为处于中间位置的是排名第五和第六的两个家庭。这个时候呢,我们求中位数的时候,就要把排名第五和第六的这两个数字累计起来,然后取平均。再来看一下分组数据的中位数计算。我们 ppt 中这里展示的是我们的分组数据。对于我们分组数据中位数的计算,我们首先要找到我们中位数的区间。因为我们的数据的个数是3194。我们的中位数大概的排序应该是在1597左右。对于1597来说。前三组数据加起来,它的出现的次数是950。前4组加起来是2450。1597刚好落在前3和前4之间。那么也就是说我们的中位数应该是落在21~50这个区间。在找到中位数所对应的区间之后。我们就可以利用插值法来计算。其中这个 L1 代表的是我们中位数区间前面一个区间的最大值,也就是我们的20。 N 指的是我们数据的个数是3194。这样的一个频率指的是我们中位数区间之前的所有分组数据的频率。那么也就是200+450+300等于950。

下面这个频率就指的是我们中位数所在区间的频率。那么也就是我们的1500。最后的这样的一个宽度,指的是我们中位数所在区间的宽度,也就是50-21+1就是30。把数据代入这个公式之后,我们最后求得我们这组分组数据的中位数为33。
3、众数测量
对集中区是第三个测度就是我们的众数。所谓的众数就指的是在我们这一组数据中出现次数最多的数据。对于众数来说它具有不唯一性。比如说像对于这样的一组数据。
那么每个数据出现的频率都是一样的。所以,它不存在众数。对于我们第二组数据。在这一组数据中,我们出现频率最高的这个数字是7。所以对对于这样的一组数据,它的众数就为7。对于我们第三组数据,大家可以看到在这组数据中。我们的28和36都分别出现了两次。

所以说对这组数据,它的众数是有两个28和36。对于我们的平均值,众数,和中位数而言。不同数据分布,他们这三者之间的关系是不一样的。

如果我们的数据他是正态分布的,那么我们的众数等于中位数等于平均值。如果我们的数据分布是这样的,一个正偏态分布。那么我们可以看到众数是小于我们的中位数小于我们的平均值的。如果我们的数据是这样的负偏态分布,我们从图中可以看到我们的平均值是小于中位数,然后是小于众数。
二、数据离散程度的测度
数据离散程度最普遍的一个测度就是我们的极差。极差就指的是最大值和最小值的差。除此之外我们还可以用4分位差来代表。
在了解了我们数据集中趋势的测度之后,了解一下数据离散程度的测度。极差是最常见的用来描述数据离散程度的测度。他指的是最大值和最小值之差。此外呢,我把我们还可以用4分位差来描述。我们首先来看一下4分位数的 de 。

4分位数,包含我们的上4分位数和下4分位数。也就是对数据排序后,位于我们数据25%左右的位置的数据。以及位于我们数据75%左右的数据。那么 q 3和 q 1的差值就指的是我们的4分位差称之为叫做 IQR 。在了解了4分位数之后,我们可以用5数概括法,对我们的数据进行描述。5数概括分别指的是数据的最小值,最大值,上4分位差下4分位差以及中位数。在统计学中认为离我们数据上下4分位差左右各1.5倍 IQR 所处的数据是正常数据。超过这个范围以外的数据就是异常数据。
在了解了最大值,最小值,4分位数之后,我们就可以去用箱线图表示我们的数据。怎么样画箱线图。
箱线图是一种重要的数据可视化方法。在箱线图中,我们数据主要是通过我们的四分位来表示。我们首先用一个盒子把我们的4分位画出来。然后在中间把我们的中位数标出来。除此之外我们分别向上和向下延伸,至我们的极大值和极小值。这里需要注意一点的是。如果我们的极大值和极小值是位于我们4分位数1.5倍, IQR 的范围以内。那他是正常的,我们直接把它标成用一个黑线标成。但是如果我们的极大值和极小值超过了我们的4分位数的1.5倍的 IQR,这个范围之外。我们就需要。用这样的一个横线,把我们的上4分位和下4分位1.5倍 IQR 的距离1.5倍 IQR 的这个地方把它标记出来。然后在这个。

范围之外的数据,用黑色的点把它表示出来,代表的是异常点。好我们再来看一下,用方差和标准差描述数据的离散程度。这个就是方差的计算公式。那么我们的方差,开根号之后就可以得到我们的标准差。对于我们的正态分布,他的方差是有一些规律的,我们向大家介绍一下。也就是如果一个数据,它的分布是正态分布。那么。在离它的这个均值左右各一个标准差范围内的数据。
会占到他全体数据的68%左右。那么离它均值左右两个标准差的数据。会占到他的数据整体的95%左右。而离他均值左右三个标准差范围的数据。会占到它整个数据总量的99.7%以上。这个就是我们的正态分布,它所具备的特点。利用这样的一个特点,我们可以用来判断异常值。
也就是说如果一个数据它是满足正态分布的,那么超出我均值左右三倍标准差以外的数据就认为是异常值。