HelloTech技术派

已加入开发者社区2361天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖




粉丝



技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
公众号:程序员叶同学,(原名:HelloTech)文章导航:https://yezhwi.github.io/
暂无精选文章
暂无更多信息
2023年04月
-
04.27 19:33:26
 发表了文章
2023-04-27 19:33:26
发表了文章
2023-04-27 19:33:26
微服务为什么要使用网关服务
不同的微服务一般会有不同的网络地址,但 web 端或 APP 端需要调用多个服务的接口才能完成一个业务需求。在这种客户端直接与各个服务通信的架构时,会有以下问题: • 客户端需要维护很多服务的请求地址; • 客户端会多次请求不同的微服务,增加了客户端的复杂性; • 存在跨域请求,处理相对复杂; • 认证复杂,每个服务都需要独立认证; • 随着项目的迭代,可能需要重新划分微服务(多个微服务合并成一个或将一个服务拆分成多个),在客户端直接与微服务通信时,重构将会难以实施; -
04.27 19:32:27发表了文章
2023-04-27 19:32:27
微服务简介
• 一个 war 包含所有功能的应用程序,通常称为单体应用。尽管在程序中进行了模块化,但若干业务模块被打包在一个 war 包中,这样的应用系统称为单体应用。 • 优点:容易部署、测试。可以快速实现需求。 • 缺点:随着需求的不断增加,开发团队的状大,代码库也在迅速增长, 此时单体应用变得越来越臃肿,可维护性、灵活性逐渐下降,维护成本高: a. 模块非常多、模块的边界模糊、依赖关系不清晰、每次修改代码心惊胆战,甚至增加一个简单功能或修改一个 bug 都会带来隐含的缺陷。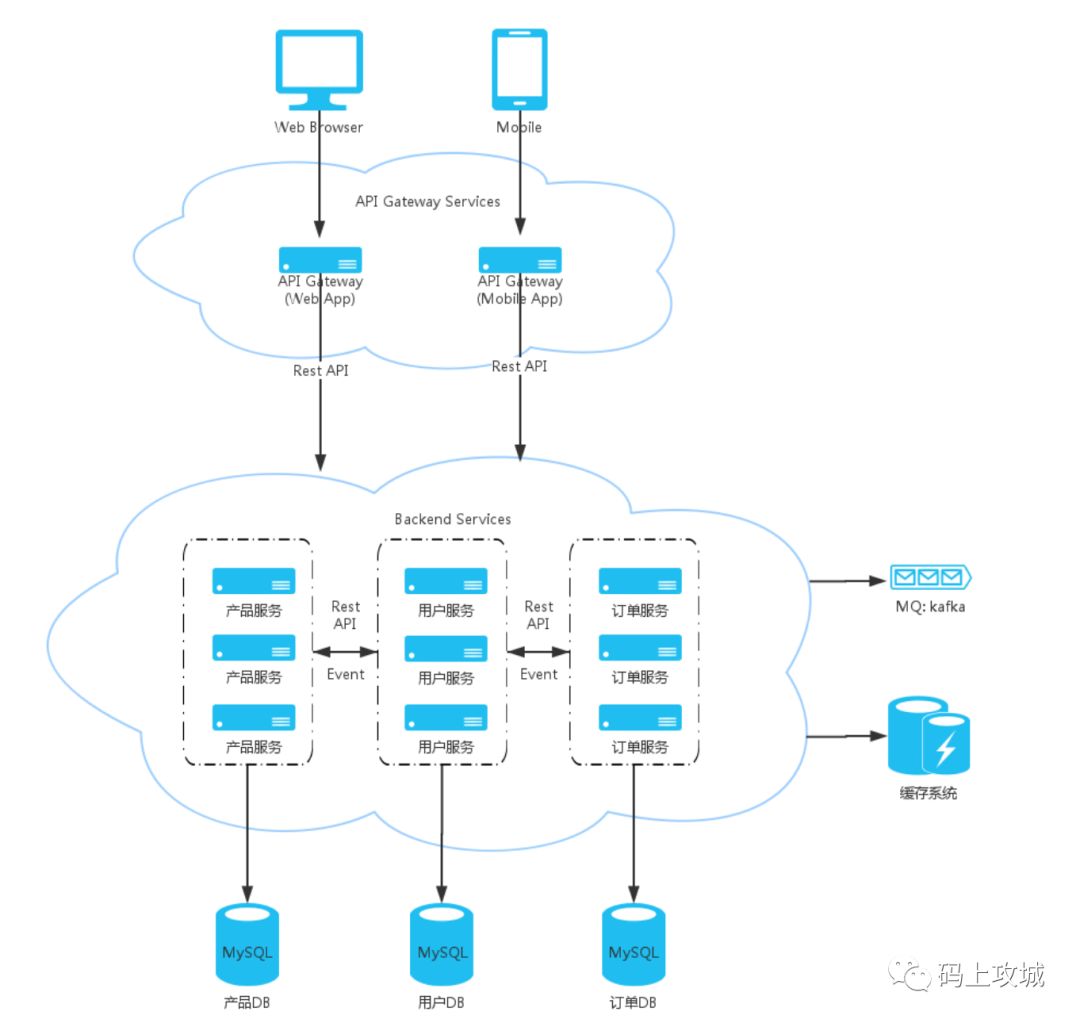
-
04.27 19:31:03发表了文章
2023-04-27 19:31:03
Scrapy 的初步认识
Scrapy 是一个高级的 Python 爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫获取的数据保存到 csv、json 等文件中。 Scrapy 使用了 Twisted 作为框架,Twisted 是事件驱动的,对于会阻塞线程的操作(访问文件、数据库等),比较适合异步的代码。 -
04.27 19:29:54发表了文章
2023-04-27 19:29:54
Kafka常见问题总结
会不会丢消息? Offset 怎么保存? Consumer 重复消费问题怎么处理? 如何保证消息的顺序? 数据倾斜怎么处理? 一个 Topic 分配多少个 Partiton 合适以及修改 Partiton有哪些限制? -
04.27 19:27:57发表了文章
2023-04-27 19:27:57
Flume案例——日志分析采集系统
大数据平台每天处理业务系统产生的大量日志数据,一般而言,这些系统需要具有以下特征: 1. 构建业务系统和日志分析系统的桥梁,并将它们之间的关联解耦; 2. 支持近实时的在线分析系统和类似于 Hadoop 之类的离线分析系统; 3. 具有高可扩展性。即:当数据量增加时,可以通过增加节点进行水平扩展。 -
04.27 19:25:50发表了文章
2023-04-27 19:25:50
Flume安装及配置
Flume 提供了大量内置的 Source、Channel 和 Sink 类型。而且不同类型的 Source、Channel 和 Sink 可以自由组合—–组合方式基于配置文件的设置,非常灵活。比如:Channel 可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink 可以把日志写入 HDFS、HBase,甚至是另外一个 Source 等。 -
04.27 19:22:59发表了文章
2023-04-27 19:22:59
Flume核心概念
Flume 是一个分布式、可靠、高可用的服务,它能够将不同数据源的海量日志数据进行高效收集、汇聚、移动,最后存储到一个中心化数据存储系统(HDFS、 HBase等)中,它是一个轻量级的工具,简单、灵活、容易部署,适应各种方式日志收集并支持 failover 和负载均衡。 -
04.27 19:20:26发表了文章
2023-04-27 19:20:26
Kafka进阶
第一,Spark和Storm都是流式处理框架,而Kafka Stream提供的是一个基于Kafka的流式处理类库。框架要求开发者按照特定的方式去开发逻辑部分,供框架调用。开发者很难了解框架的具体运行方式。而Kafka Stream作为流式处理类库,直接提供具体的类给开发者调用,整个应用的运行方式主要由开发者控制,方便使用和调试。 -
04.27 19:18:10发表了文章
2023-04-27 19:18:10
Spark快速入门-3-Spark的算子总结
Transformation 变换/转换算子:这类算子操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。这种变换并不触发提交作业,完成作业中间过程处理。 Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业,并将数据输出 Spark 系统。 -
04.27 19:11:24发表了文章
2023-04-27 19:11:24
Spark快速入门-2-Spark的编程模型
Spark快速入门-2-Spark的编程模型 -
04.27 19:10:06发表了文章
2023-04-27 19:10:06
Spark on Yarn Job的执行流程简介
2017-12-19-Hadoop2.0架构及HA集群配置(1) 2017-12-24-Hadoop2.0架构及HA集群配置(2) 2017-12-25-Spark集群搭建 2017-12-29-Hadoop和Spark的异同 2017-12-28-Spark-HelloWorld(Spark开发环境搭建) -
04.27 19:08:11发表了文章
2023-04-27 19:08:11
Scala快速入门-11-常用集合操作
所有的集合都扩展自Iterable特质 集合有三大类,分别为序列、集和映射 几乎所有集合类,Scala都同时提供了可变和不可变的版本 Scala列表要么是空的,要么拥有一头一尾,其中尾部本身又是一个表列 集是无先后次序的集合 用LinkedHashSet来保留插入顺序,或用SortedSet来按顺序进行迭代 +将元素添加到无先后次序的集合中;+:和:+向前或向后追加到序列;++将两个集合串接在一起;-和--移除元素 映射、折叠和拉链操作是很有用的技巧,用来将函数和操作应用到集合中的元素 -
04.27 19:04:47发表了文章
2023-04-27 19:04:47
Scala快速入门-10-模式匹配与样例类
mathch表达式是一个更好的switch,不会有穿透到下一个分支的问题 如果没有模式能够匹配,会抛出MatchError,可以用case _ 模式来避免,相当于Java中的default 模式可以包含一个随意定义的条件,称做守卫 可以匹配数组、列表、元组等模式,然后将匹配到不同部分绑定到变量 样例类及密封类的模式匹配 用Option来存放可能存在也可能不存在的值,比null更安全 -
04.27 18:58:52发表了文章
2023-04-27 18:58:52
Scala快速入门-9-高阶函数
作为值的函数 创建匿名函数 带函数参数的函数 闭包 柯里化 -
04.27 18:56:00发表了文章
2023-04-27 18:56:00
Scala快速入门-8-特质
Scala和Java一样不允许类继承多个超类,特质解决这一局限性 类可以实现任意数量的特质 当将多个特质叠加在一起时,顺序很重要,其方法先被执行的特质排在更后面 Scala特质可以提供方法和字段的实现 特质要求实现它们的类具备特定的字段、方法或超类 特质可以同时拥有抽象方法和具体方法,而类可以实现多个特质 -
04.27 18:53:59发表了文章
2023-04-27 18:53:59
Scala快速入门-7-继承
继承类 extends 重写方法时必须用override 只有主构造器可以调用超类的主构造器 重写字段 抽象类、字段 -
04.27 18:52:12发表了文章
2023-04-27 18:52:12
Scala快速入门-6-单例对象及伴生对象
• 用对象作为单例或存放工具方法,Scala没有静态方法或字段 • 类可以有一个同名的伴生对象 • 对象的apply方法通常用来构造伴生类的新实例 • Scala的main函数定义 单例对象 -
04.27 18:50:21发表了文章
2023-04-27 18:50:21
Scala快速入门-5-类定义
每个类都有一个主构造器,这个构造器和类的定义“交织”在一起,它的参数直接成为类的字段,主构造器执行类体中所有的语句 类中的字段自动带getter和setter方法 用@BeanProperty注解生成JavaBean的getXxx/setXxx方法 辅助构造器是可选的,它们都叫做this -
04.27 18:48:08发表了文章
2023-04-27 18:48:08
Scala快速入门-4-常用映射和元组操作
映射是键值对的集合 n个对象(并不一定要相同类型的对象)的集合,元组 -
04.27 18:46:24发表了文章
2023-04-27 18:46:24
Scala快速入门-3-常用数组操作
长度固定使用Array,长度有变化使用ArrayBuffer 提供初始值时不要使用new 用()来访问元素 for(elem <- arr)遍历元素 for(elem <- arr if ...) yield ...将原数组转为新数组 -
04.27 18:43:48发表了文章
2023-04-27 18:43:48
Scala快速入门-2-控制结构与函数
表达式有值,语句执行动作。 Scala中,几乎所有构造出来的语法结构都有值,不像Java中把表达式和语句(if语句)分为两类。 在这里if表示式有值。 代码块也有值,最后一个表达式就是值。 语句中,分号不是必需的。 函数式中不使用return。 -
04.27 18:40:49发表了文章
2023-04-27 18:40:49
Scala快速入门-1-声明变量
因为Spark是由Scala开发的,所以在开发Spark应用程序之前要对Scala语言学习。虽然Spark也支持Java、Python语言,但是作为一名Java程序猿,还是决定要学习Scala哈。 Scala是运行在JVM上一门语言。开发效率非常高、语法丰富简洁,三两行Scala代码能搞定Java要写的一大坨代码。 Scala的语法糖太甜~~ -
04.27 18:38:46发表了文章
2023-04-27 18:38:46
Hadoop和Spark的异同
Hadoop实质上是解决大数据大到无法在一台计算机上进行存储、无法在要求的时间内进行处理的问题,是一个分布式数据基础设施。 HDFS,它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,通过将块保存到多个副本上,提供高可靠的文件存储。 MapReduce,通过简单的Mapper和Reducer的抽象提供一个编程模型,可以在一个由几十台上百台的机器上并发地分布式处理大量数据集,而把并发、分布式和故障恢复等细节隐藏。 -
04.27 18:36:44发表了文章
2023-04-27 18:36:44
IntelliJ-IDEA-Mavne-Scala-Spark开发环境搭建
IntelliJ-IDEA-Mavne-Scala-Spark开发环境搭建 -
04.27 18:33:58发表了文章
2023-04-27 18:33:58
Spark集群搭建
Spark集群搭建 -
04.27 18:30:35发表了文章
2023-04-27 18:30:35
Hadoop2.0架构及HA集群配置(2)
在Hadoop2.0中通常由两个NameNode组成,一个处于Active状态,另一个处于Standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,以便能够在它失败时快速进行切换。 Hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置大于或等于3奇数个JournalNode。 需要配置一 -
04.27 18:28:39发表了文章
2023-04-27 18:28:39
Spring-Data-REST修改默认配置
在上一篇中除去配置类和实体类,写了两行代码,就实现了RESTful风格的接口,但在实际使用时,还需要一些额外的处理,比如在返回的数据中,password这类敏感字段是不应该返回的;删除操作,实际需求不是硬删除只是更新一个删除状态;保存对象操作之前需要做相应的数据校验和数据格式的转换等等,自动转换成REST服务,是否支持自定义功能?在上一篇中除去配置类和实体类,写了两行代码,就实现了RESTful风格的接口,但在实际使用时,还需要一些额外的处理,比如在返回的数据中,password这类敏感字段是不应该返回的;删除操作,实际需求不是硬删除只是更新一个删除状态;保存对象操作之前需要做相应的数据校验 -
04.27 18:25:31发表了文章
2023-04-27 18:25:31
微信支付退款异常处理过程
微信支付退款异常处理过程 -
04.27 18:23:41发表了文章
2023-04-27 18:23:41
Hadoop2.0架构及HA集群配置(1)
NameNode HA NameNode Federation HDFS快照 HDFS缓存 HDFS ACL -
04.27 18:21:32发表了文章
2023-04-27 18:21:32
Yarn的基本概念与资源调度
Hadoop是Apache的一个开源分布式计算平台,以分布式文件系统HDFS,和MapReduce为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。HDFS的高容错性、高伸缩性等优点形成分布式系统;MapReduce分布式编程模型让我们开发并行应用程序。 -
04.27 13:22:40发表了文章
2023-04-27 13:22:40
Spring-Data-REST轻松搞定RESTfulAPI
昨天同事问我有没有研究过 spring-boot-starter-data-rest,没有~但是看名字就大概知道是做什么的(命名的重要性),因为之前有了解过 spring-boot-starter-data-jpa ,过一会发过两个截图过来。真的很强大,感觉这个在使用RESTful风格接口协议的微服务时都不用写Controller了。 -
04.27 13:20:52发表了文章
2023-04-27 13:20:52
实践bug总结-Feign使用Hystrix配置
实践bug总结-Feign使用Hystrix配置 -
04.27 13:19:31发表了文章
2023-04-27 13:19:31
GitAndGitLab介绍
Git是一种非常流行的分布式版本控制系统,它和其他版本控制系统的主要差别在于Git只关心文件数据的整体是否发生变化,而大多数版本其他系统只关心文件内容的具体差异,这类系统(CVS、Subversion 等等)每次记录有哪些文件作了更新,以及都更新了哪些行的什么内容。Git另一个比较好的地方在于绝大多数操作都可以在本地执行,而每个本地都可以从服务器获取一份完整的仓库代码,而且在没网的时候仍然可以修改和使用大部分命令,在方便的时候再跟服务器进行同步,这样可以更好的实现多人联合编程。 -
04.27 13:16:52发表了文章
2023-04-27 13:16:52
SpringCloud智能网关Zuul-核心功能过滤器
在上一篇我们通过使用Spring Cloud Zuul构建了一个基础的API网关服务,同时也演示了Spring Cloud Zuul基于服务的自动路由功能。然而,目前的服务路由并没有限制权限这样的功能,所有请求都会被毫无保留地转发到具体的应用并返回结果,为了实现对客户端请求的安全校验和权限控制,需要为微服务实现一套用于校验签名和鉴别权限的过滤器或拦截器。由于网关服务的加入,外部客户端访问有统一入口,Zuul允许开发者在API网关服务通过定义过滤器来实现对请求的拦截与过滤,实现的方法非常简单,只需要继承ZuulFilter抽象类并实现它定义的四个抽象函数就可以完成对请求的拦截和过滤了。 -
04.27 13:13:59发表了文章
2023-04-27 13:13:59
SpringCloud智能网关入门介绍
通过之前几篇Spring Cloud中几个核心组件的介绍:Eureka用于服务的注册与发现,Ribbon或Feign支持服务的调用以及均衡负载,Hystrix处理服务的熔断防止故障扩散,似乎一个微服务框架已经完成了。 但是,为了保证对外服务的安全性,我们需要实现对服务访问的权限控制,如果这些功能实现在微服务中,导致在工作中除了要考虑实际的业务逻辑之外,还需要额外为每个微服务增加对外接口访问的控制处理,或增加一个代理调用来实现权限控制。 服务网关就是解决这类问题的方案。 -
04.27 13:11:54发表了文章
2023-04-27 13:11:54
SpringBoot集成FastDFS
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。 FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。 -
04.27 13:10:27发表了文章
2023-04-27 13:10:27
Hystrix数据进行聚合展示-Turbine(HTTP方式)
Hystrix数据进行聚合展示-Turbine(HTTP方式) -
04.27 13:08:31发表了文章
2023-04-27 13:08:31
实践bug总结--SpringBoot项目只能存在一个main函数
实践bug总结--SpringBoot项目只能存在一个main函数 -
04.27 13:07:41发表了文章
2023-04-27 13:07:41
SpringCloud @RestController返回值问题
SpringCloud @RestController返回值问题 -
04.27 13:05:56发表了文章
2023-04-27 13:05:56
SpringCloud Feign遇到的问题
SpringCloud Feign遇到的问题 -
04.27 13:03:55发表了文章
2023-04-27 13:03:55
Hystrix Dashboard 让你更了解系统的运行情况
断路器的打开和关闭状态的变化是由系统收集一些重要参数,当达到条件时才触发的。而这些请求情况的指标信息都是 HystrixCommand和 HystrixObservableCommand实例在执行过程中记录的重要信息,为了帮助我们系统运维或性能优化做出判断, HystrixDashboard实现Hystrix指标数据的可视化。 接口实现使用了 @HystrixCommand注解后,这个接口的调用情况会被Hystrix记录下来,并用来给断路器和 HystrixDashboard使用。 Hystrix-dashboard是一款针对Hystrix进行实时监控的工具,通过Hystrix Dashboa -
04.27 13:02:23发表了文章
2023-04-27 13:02:23
SpringCloud-Hystrix——让你的系统稳一点儿
在微服务架构中,我们将系统拆分成了一个个的服务单元,各单元应用间通过服务注册与订阅的方式互相依赖。由于每个单元都在不同的进程中运行,依赖通过远程调用的方式执行,这样就有可能因为网络原因或是依赖服务自身问题出现调用故障或延迟,而这些问题会直接导致调用方的对外服务也出现延迟,若此时调用方的请求不断增加,最后就会出现因等待出现故障的依赖方响应而形成任务积压,线程资源无法释放,最终导致自身服务的瘫痪,进一步甚至出现故障的蔓延最终导致整个系统的瘫痪,导致服务雪崩效应。为了解决这样的问题,产生了断路器等一系列的服务保护机制。 -
04.27 13:00:55发表了文章
2023-04-27 13:00:55
SpringBoot访问MongoDB数据库
MongoDB是一个基于分布式文件存储的数据库,它是一个介于关系数据库和非关系数据库之间的产品,其主要目标是在键/值存储方式(提供了高性能和高度伸缩性)和传统的RDBMS系统(具有丰富的功能)之间架起一座桥梁,它集两者的优势于一身。 传统的关系数据库一般由数据库(database)、表(table)、记录(record)三个层次概念组成,MongoDB是由数据库(database)、集合(collection)、文档对象(document)三个层次组成。 -
04.27 12:59:13发表了文章
2023-04-27 12:59:13
Feign对服务的声明式定义和调用
在此之前,各个微服务都是以HTTP接口的形式暴露自身服务的,因此在调用远程服务时就必须使用HTTP客户端,使用起来很不方便,需要了解URL,有时还需要拼装真正请求的URL。有没有一种用起来更方便、更优雅的方式吗?答案是肯定的,Spring Cloud想到了这些————Feign。Spring Cloud Feign是一套基于Netflix Feign实现的声明式服务调用客户端。它使得编写Web服务客户端变得更加简单。在Spring Cloud中使用Feign, 我们只需要通过创建接口并用注解来配置既可完成对Web服务接口的绑定,可以做到使用HTTP请求远程服务时能与调用本地方法一样的编码体验, -
04.27 12:57:36发表了文章
2023-04-27 12:57:36
Ribbon简化负载均衡调用服务端实战
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。它是一个基于HTTP和TCP的客户端负载均衡器。它可以通过在客户端中配置ribbonServerList来设置服务端列表去轮询访问以达到均衡负载的作用。 -
04.27 12:56:31发表了文章
2023-04-27 12:56:31
Ribbon简化负载均衡调用服务端实战
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。它是一个基于HTTP和TCP的客户端负载均衡器。它可以通过在客户端中配置ribbonServerList来设置服务端列表去轮询访问以达到均衡负载的作用。 -
04.27 12:55:06发表了文章
2023-04-27 12:55:06
SpringCloud基础服务注册中心Eureka
由于Spring Cloud为服务治理做了一层抽象接口,所以在Spring Cloud应用中可以支持多种不同的服务治理框架,比如:Netflix Eureka、Consul、Zookeeper。在Spring Cloud服务治理抽象层的作用下,我们可以无缝地切换服务治理实现,并且不影响任何其他的服务注册、服务发现、服务调用等逻辑。(有过面向接口编程的同学应该能体会到这一层抽象接口带来的好处。) -
04.27 12:53:50发表了文章
2023-04-27 12:53:50
SpringCloud基础服务注册中心Eureka
由于Spring Cloud为服务治理做了一层抽象接口,所以在Spring Cloud应用中可以支持多种不同的服务治理框架,比如:Netflix Eureka、Consul、Zookeeper。在Spring Cloud服务治理抽象层的作用下,我们可以无缝地切换服务治理实现,并且不影响任何其他的服务注册、服务发现、服务调用等逻辑。(有过面向接口编程的同学应该能体会到这一层抽象接口带来的好处。) -
04.27 12:52:11发表了文章
2023-04-27 12:52:11
SpringCloud初探
Spring Cloud是一系列框架的有序集合,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架(服务发现注册、配置中心、消息总线、负载均衡、断路器、智能路由、数据监控、分布式会话和集群状态管理等)组合起来,通过Spring Boot进行再封装屏蔽掉了复杂的配置,巧妙地简化了分布式系统基础设施的开发,最终给我们一套简单易懂、易部署和易维护的分布式系统开发利器,做到一键启动和部署。 Spring Cloud包含了多个子项目(针对分布式系统中涉及的多个不同开源产品),比如:Spring Cloud Config、Spring Cloud Netflix、Spring Cloud Clo -
04.27 12:50:03发表了文章
2023-04-27 12:50:03
Spring Boot 快速入门(HelloWorld)
开箱即用,提供各种默认配置 内嵌式容器简化Web项目 没有冗余代码和XML配置的要求
-
发表了文章
2023-07-24
Python 的数据类型
-
发表了文章
2023-07-24
Python 基础语法和规范,初学者少踩坑
-
发表了文章
2023-05-04
使用Gradio快速搭建一个聊天机器人
-
发表了文章
2023-04-28
ChatGPT 数据仓库实战:Kaggle 酒店入住数据分析与维度建模
-
发表了文章
2023-04-28
情人节酒店数据分析:ChatGPT 揭示的爱情商机
-
发表了文章
2023-04-27
利用 OpenAI 接口,一个人就能完成聊天机器人
-
发表了文章
2023-04-27
Gradio快速入门
-
发表了文章
2023-04-27
安装 Python 开发环境,准备体验 OpenAI 的 API
-
发表了文章
2023-04-27
附PDF|ChatGPT 是怎么变得这么强的?——ChatGPT 的前世今生
-
发表了文章
2023-04-27
附 PPT|ChatGPT 的技术发展路径和带来的影响
-
发表了文章
2023-04-27
"让科技温暖世界:智能眼镜帮助盲人走向自由"——你是我的眼
-
发表了文章
2023-04-27
如何将最新的数据集成到 ChatGPT 智能对话中?
-
发表了文章
2023-04-27
怎么写好一个 Prompt?
-
发表了文章
2023-04-27
使用 ChatGPT 基于领域文档构建聊天机器人指南
-
发表了文章
2023-04-27
一步步学Python:准备开发环境
-
发表了文章
2023-04-27
开启AI时代,ChatGPT和Whisper API隆重登场!
-
发表了文章
2023-04-27
玩转Python编程:打造自己的编程王国
-
发表了文章
2023-04-27
不需要编写代码,也能成为Hive SQL面试高手?ChatGPT告诉你...
-
发表了文章
2023-04-27
ChatGPT 数据仓库实战:Kaggle 酒店入住数据分析与维度建模
-
发表了文章
2023-04-27
OpenAI 快速入门(附代码)
滑动查看更多
暂无更多信息
暂无更多信息