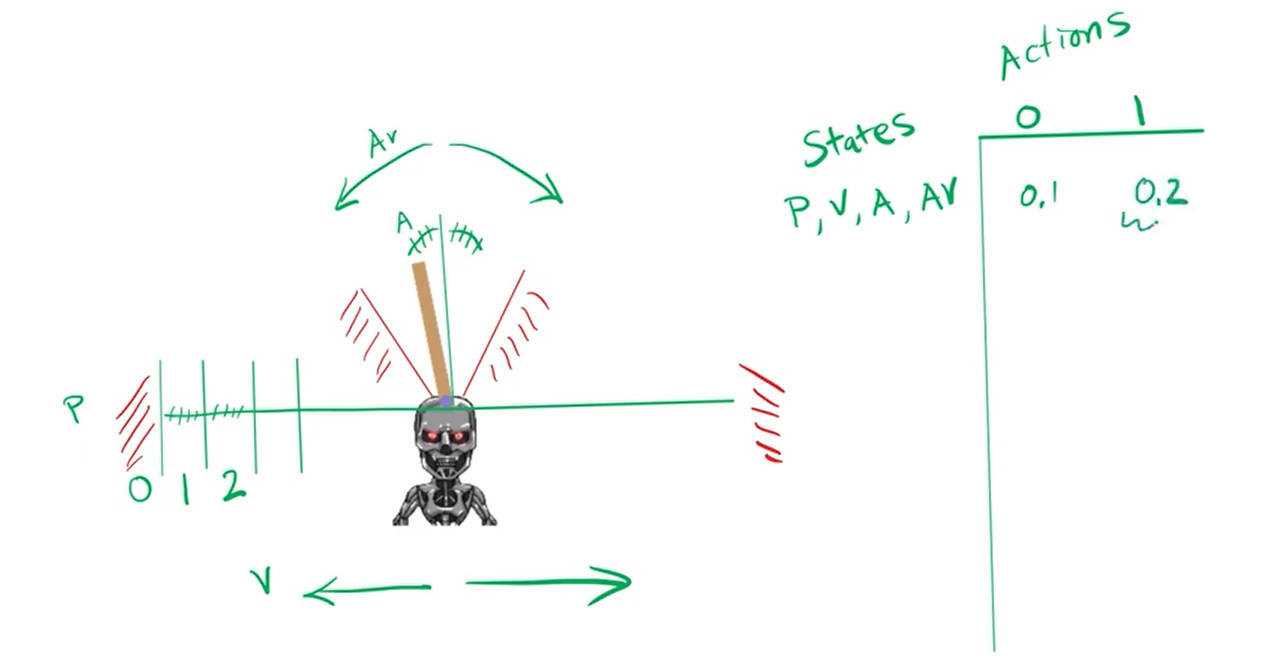
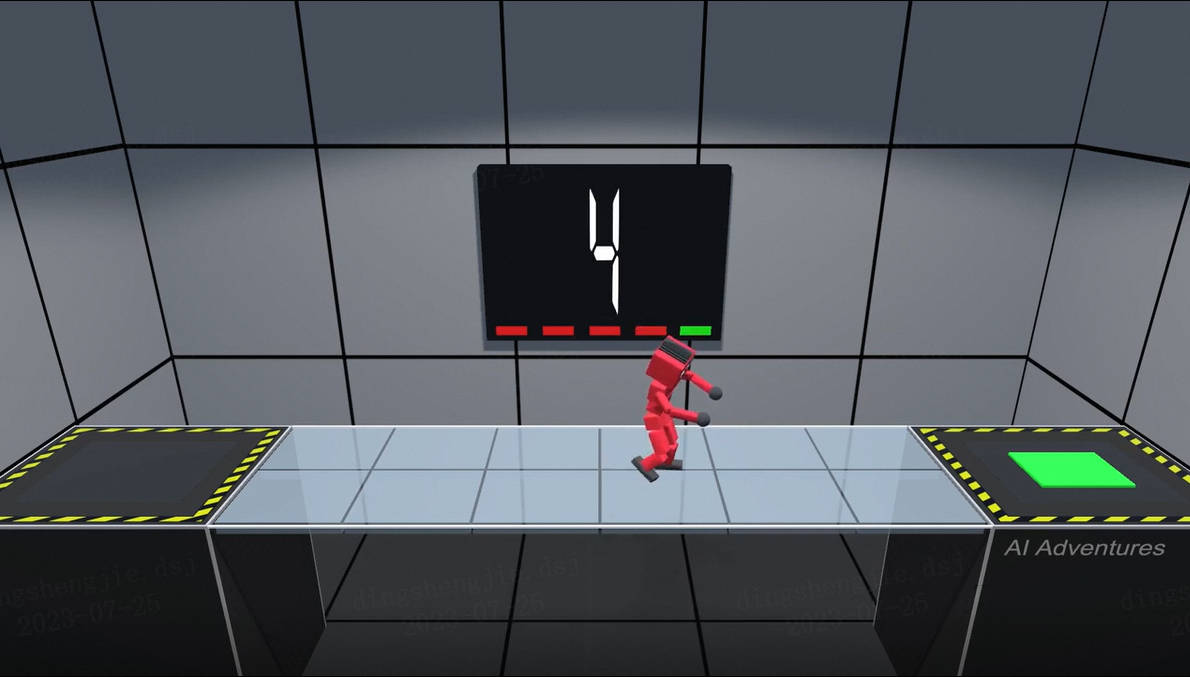
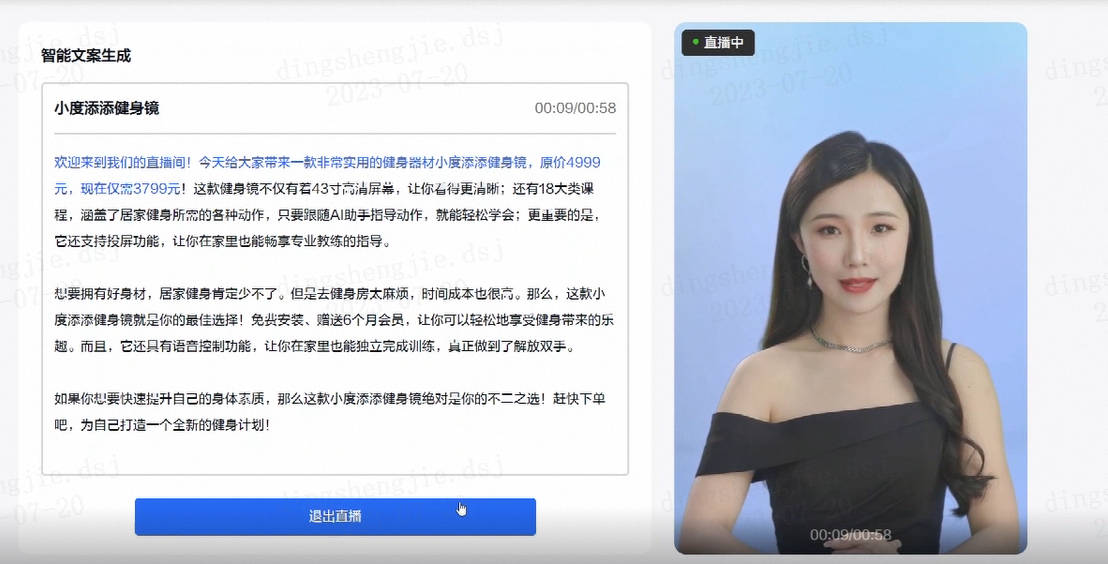
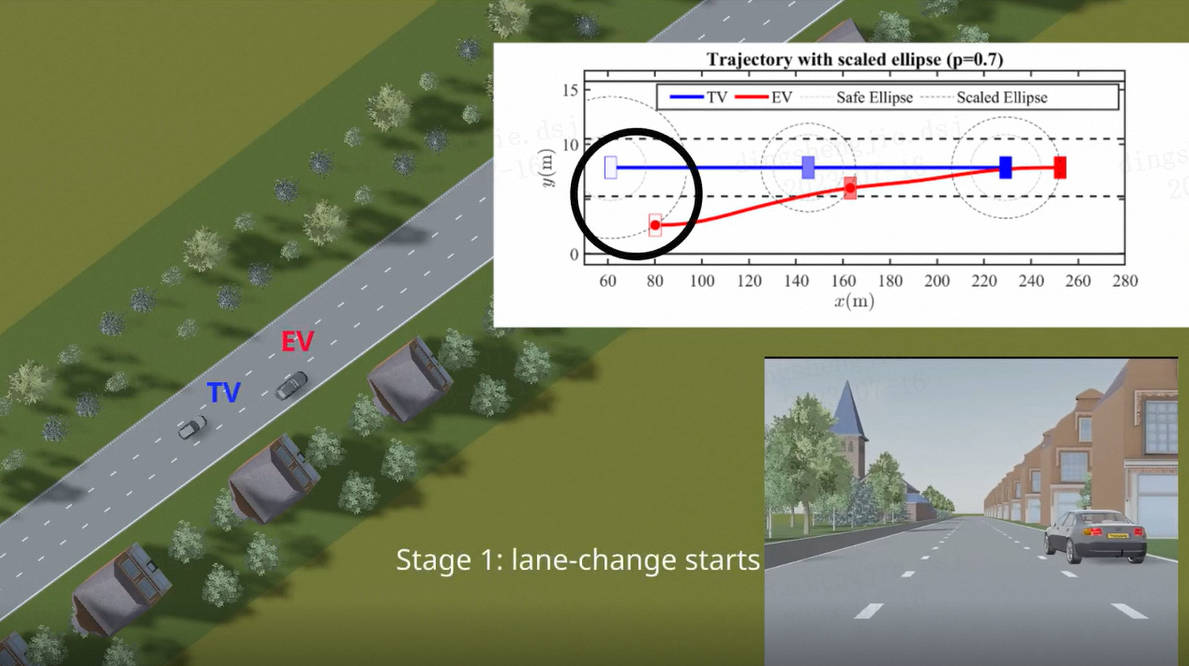
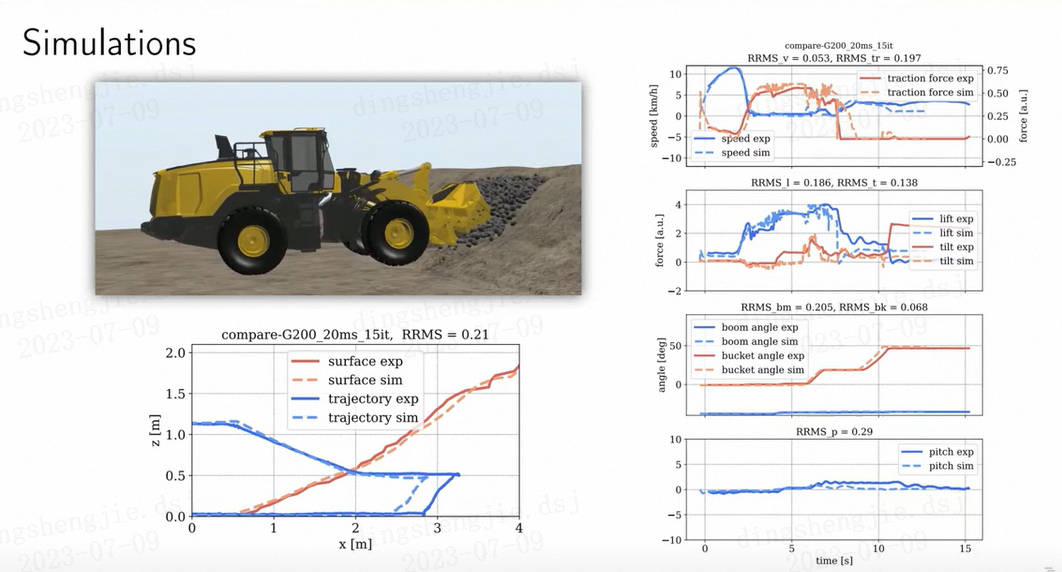
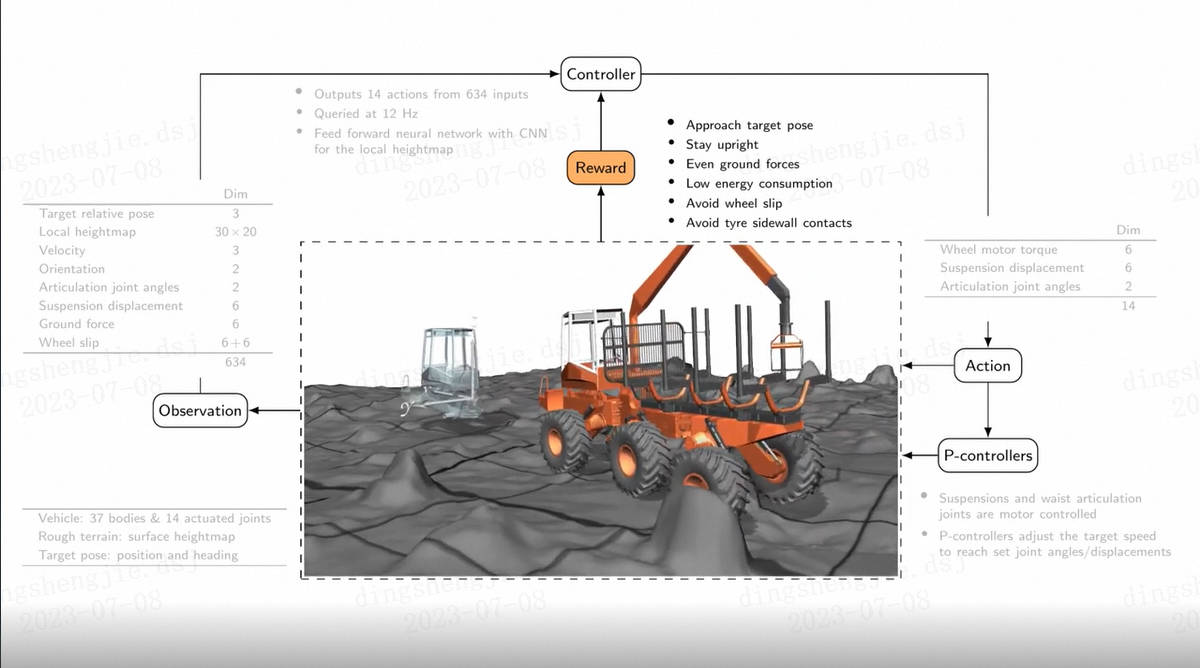
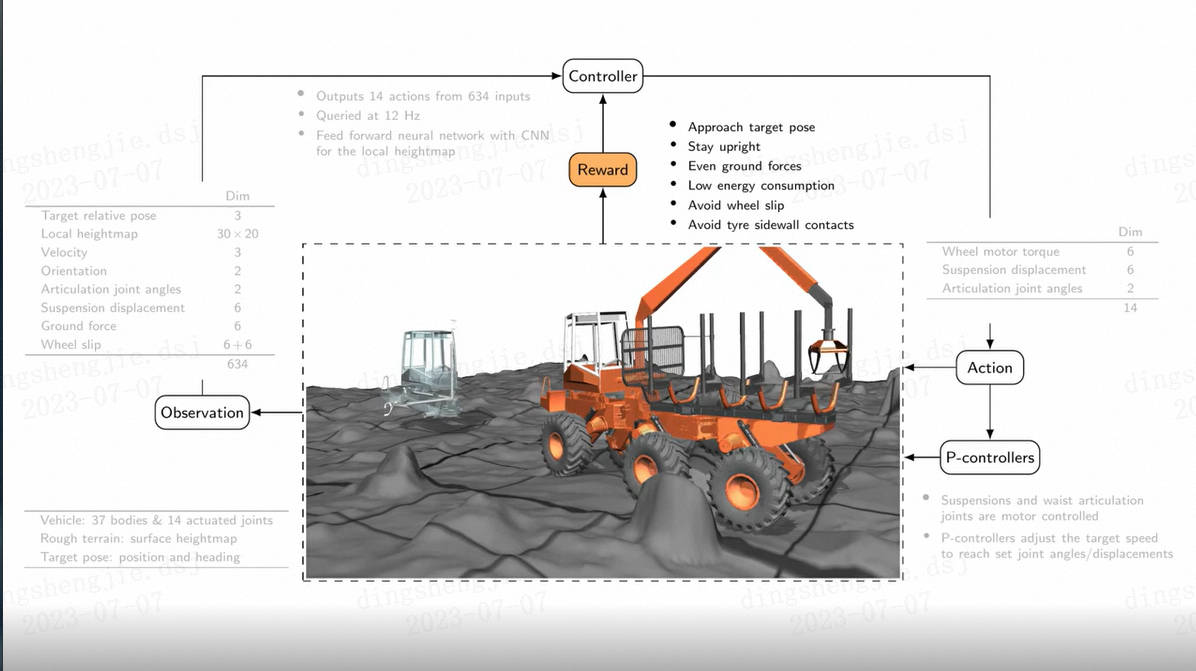
能力说明:
了解Python语言的基本特性、编程环境的搭建、语法基础、算法基础等,了解Python的基本数据结构,对Python的网络编程与Web开发技术具备初步的知识,了解常用开发框架的基本特性,以及Python爬虫的基础知识。
 Apsara Clouder云计算专项技能认证:云服务器ECS入门
Apsara Clouder云计算专项技能认证:云服务器ECS入门
将不定期更新关于机器学习、强化学习、数据挖掘以及NLP等领域相关知识
需求跨领域跨任务:领域之间知识迁移难度高,如通用领域知识很难迁移到垂类领域,垂类领域之间的知识很难相互迁移;存在实体、关系、事件等不同的信息抽取任务需求。 - 定制化程度高:针对实体、关系、事件等不同的信息抽取任务,需要开发不同的模型,开发成本和机器资源消耗都很大。 - 训练数据无或很少:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高。
需求跨领域跨任务:领域之间知识迁移难度高,如通用领域知识很难迁移到垂类领域,垂类领域之间的知识很难相互迁移;存在实体、关系、事件等不同的信息抽取任务需求。 - 定制化程度高:针对实体、关系、事件等不同的信息抽取任务,需要开发不同的模型,开发成本和机器资源消耗都很大。 - 训练数据无或很少:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高。
可以看出在样本量还算大的情况下,预训练方式更有优势(准确率略高一点且训练更快一些),通过AITrust可信分析:稀疏数据筛选、脏数据清洗、数据增强等方案看到模型性能都有提升; 这里提升不显著的原因是,这边没有对筛选出来数据集进行标注:因为没有特定背景知识就不花时间操作了,会导致仍会有噪声存在。相信标注完后能提升3-5%点 1. 对于大多数任务,我们使用预训练模型微调作为首选的文本分类方案:准确率较高,训练较快 2. 提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。对于标注样本充足、标
 发表了文章
2025-12-11
发表了文章
2025-11-19
发表了文章
2025-11-07
发表了文章
2025-10-22
发表了文章
2025-09-26
发表了文章
2025-09-23
发表了文章
2025-09-18
发表了文章
2025-09-17
发表了文章
2025-09-08
发表了文章
2025-09-02
发表了文章
2025-08-28
发表了文章
2025-08-22
发表了文章
2025-08-07
发表了文章
2025-08-06
发表了文章
2025-07-25
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-12-11
发表了文章
2025-11-19
发表了文章
2025-11-07
发表了文章
2025-10-22
发表了文章
2025-09-26
发表了文章
2025-09-23
发表了文章
2025-09-18
发表了文章
2025-09-17
发表了文章
2025-09-08
发表了文章
2025-09-02
发表了文章
2025-08-28
发表了文章
2025-08-22
发表了文章
2025-08-07
发表了文章
2025-08-06
发表了文章
2025-07-25
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20

 回答了问题
2023-03-03
回答了问题
2023-03-03
回答了问题
2023-03-03
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-16
回答了问题
2023-03-03
回答了问题
2023-03-03
回答了问题
2023-03-03
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-16