类目筛选
大模型推理优化实践:KV cache复用与投机采样
在本文中,我们将详细介绍两种在业务中实践的优化策略:多轮对话间的 KV cache 复用技术和投机采样方法。我们会细致探讨这些策略的应用场景、框架实现,并分享一些实现时的关键技巧。
用软硬协同设计下的飞天盘古降低存储系统开销
历经 15 载,如今的飞天盘古系统已迭代至第三代,数千万行代码和 1,000 余项专利,从大规模、到高性能、到高效能的分布式存储系统的演进,更高效地让数据中心成为一台计算机。

Paimon 与 Spark 的集成(二):查询优化
通过一系列优化,我们将 Paimon x Spark 在 TpcDS 上的性能提高了37+%,已基本和 Parquet x Spark 持平,本文对其中的关键优化点进行了详细介绍。
深入浅出LangChain与智能Agent:构建下一代AI助手
LangChain为大型语言模型提供了一种全新的搭建和集成方式,通过这个强大的框架,我们可以将复杂的技术任务简化,让创意和创新更加易于实现。本文从LangChain是什么到LangChain的实际案例到智能体的快速发展做了全面的讲解。

【算法精讲系列】MGTE系列模型,RAG实施中的重要模型
检索增强生成(RAG)结合检索与生成技术,利用外部知识库提升大模型的回答准确性与丰富性。RAG的关键组件包括文本表示模型和排序模型,前者计算文本向量表示,后者进行精细排序。阿里巴巴通义实验室推出的GTE-Multilingual系列模型,具备高性能、长文档支持、多语言处理及弹性向量表示等特性,显著提升了RAG系统的检索与排序效果。该系列模型已在多个数据集上展示出优越性能,并支持多语言和长文本处理,适用于各种复杂应用场景。
AI开源框架:让分布式系统调试不再"黑盒"
Ray是一个开源分布式计算框架,专为支持可扩展的人工智能(AI)和Python应用程序而设计。它通过提供简单直观的API简化分布式计算,使得开发者能够高效编写并行和分布式应用程序 。Ray广泛应用于深度学习训练、大规模推理服务、强化学习以及AI数据处理等场景,并构建了丰富而成熟的技术生态。

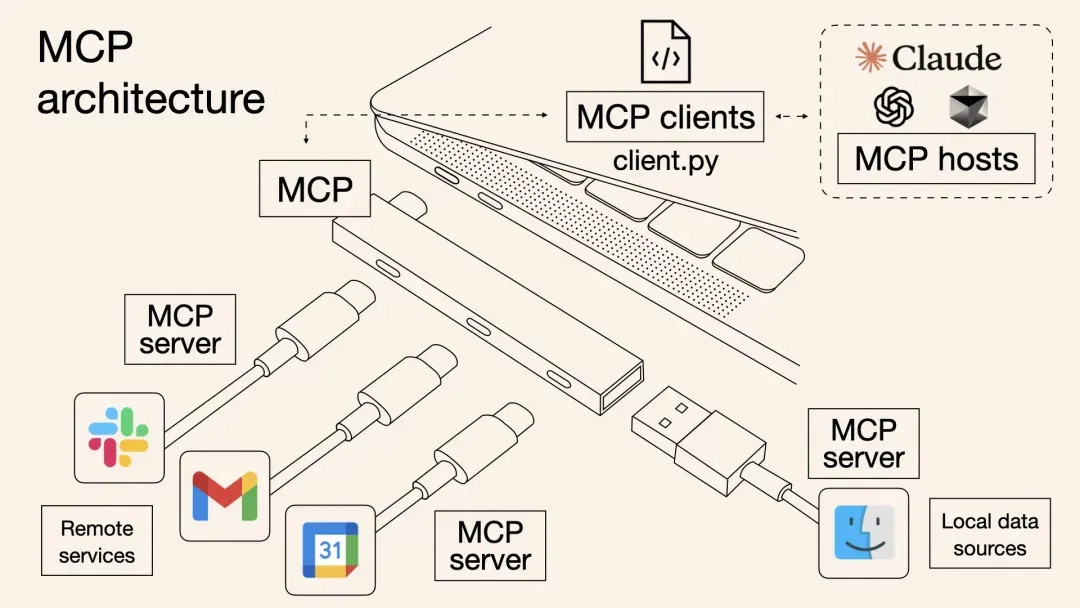
MCP进阶:一键批量搞定MCP工具部署
本文介绍了一种基于阿里云计算巢的一站式MCP工具解决方案,解决了传统MCP工具集成中的效率低下、调用方式割裂和动态管理困难等问题。方案通过标准化协议实现多MCP工具批量部署,提高云资源利用率,并支持OpenAPI与MCP双通道调用,使主流AI助手如Dify、Cherry Studio等无缝接入。内容涵盖背景、原理剖析、部署使用实战及问题排查,最后强调MCP协议作为“通用语言”连接数字与物理世界的重要性。