本课程是阿里云百炼平台的第二天课程内容,旨在帮助用户了解如何通过阿里云百炼构建和发布自己的AI应用。介绍了如何利用大模型和智能体应用来创建具备强大语言理解和生成能力的AI助手,并通过不同的渠道(如网站、钉钉、微信公众号等)发布这些应用。
本文主要以一个Java工程师视角,阐述如何从零(无任何二三方依赖)构建一个极简(麻雀虽小五脏俱全)现代深度学习框架(类比AI的操作系统)。
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama 3 研究论文。

推理性能的提升涉及底层硬件、模型层,以及其他各个软件中间件层的相互协同,因此了解大模型技术架构的全局视角,有助于我们对推理性能的优化方案进行评估和选型。
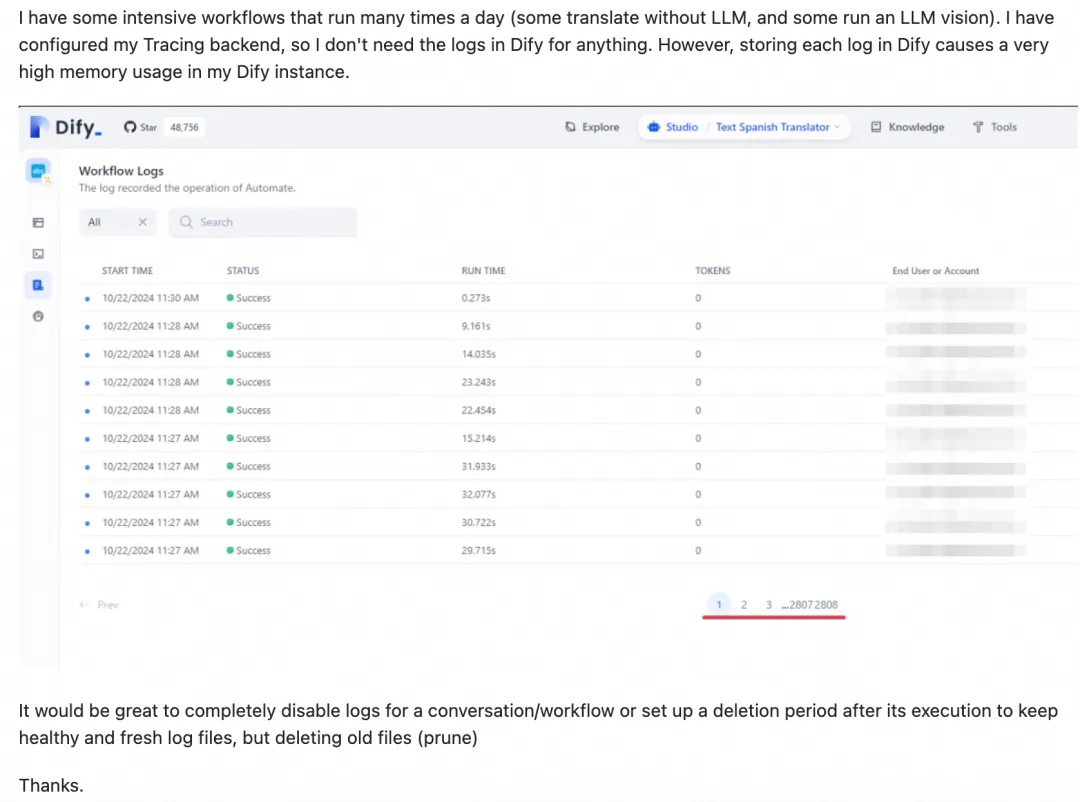
Dify是一款开源的大模型应用开发平台,支持通过可视化界面快速构建AI Agent和工作流。然而,Dify本身缺乏定时调度与监控报警功能,且执行记录过多可能影响性能。为解决这些问题,可采用Dify Schedule或XXL-JOB集成Dify工作流。Dify Schedule基于GitHub Actions实现定时调度,但仅支持公网部署、调度延时较大且配置复杂。相比之下,XXL-JOB提供秒级调度、内网安全防护、限流控制及企业级报警等优势,更适合大规模、高精度的调度需求。两者对比显示,XXL-JOB在功能性和易用性上更具竞争力。
通过遵循以上最佳实践,可以构建一个高效、可靠的 RAG 系统,为用户提供准确和专业的回答。这些实践涵盖了从文档处理到系统配置的各个方面,能够帮助开发者构建更好的 RAG 应用。
在本文中,我们将详细介绍两种在业务中实践的优化策略:多轮对话间的 KV cache 复用技术和投机采样方法。我们会细致探讨这些策略的应用场景、框架实现,并分享一些实现时的关键技巧。
