本文章旨在帮助读者了解并掌握大模型多模态技术的实际应用,特别是如何构建基于多模态的实用场景。文档通过几个具体的多模态应用场景,如拍立淘、探一下和诗歌相机,展示了这些技术在日常生活中的应用潜力。
在阿里云平台上,您只需十分钟,无需任何编码,即可在企业微信上为您的组织集成一个具备大模型能力的AI助手。此助手可24小时响应用户咨询,解答各类问题,尤其擅长处理私域问题,从而成为您企业的专属助手,有效提升用户体验及业务竞争力。
本文详细阐述了Prompt的设计要素,包括引导语、上下文信息等,还介绍了多种Prompt编写策略,如复杂规则拆分、关键信息冗余、使用分隔符等,旨在提高模型输出的质量和准确性。通过不断尝试、调整和优化,可逐步实现更优的Prompt设计。

本章我们将介绍如何利用大模型开发一个文档比对小工具,我们将用这个工具来给互联网上两篇内容相近但版本不同的文档找找茬,并且我们提供了一种批处理文档比对的方案
本文介绍了MCP(Model Context Protocol)与Qwen3模型的结合应用。MCP通过统一协议让AI模型连接各种工具和数据源,类似AI世界的“USB-C”接口。文中详细解析了MCP架构,包括Host、Client和Server三个核心组件,并说明了模型如何智能选择工具及工具执行反馈机制。Qwen3作为新一代通义千问模型,采用混合专家架构,具备235B参数但仅需激活22B,支持快速与深度思考模式,多语言处理能力覆盖119种语言。文章还展示了Qwen3的本地部署流程,以及开发和调试MCP Server与Client的具体步骤。

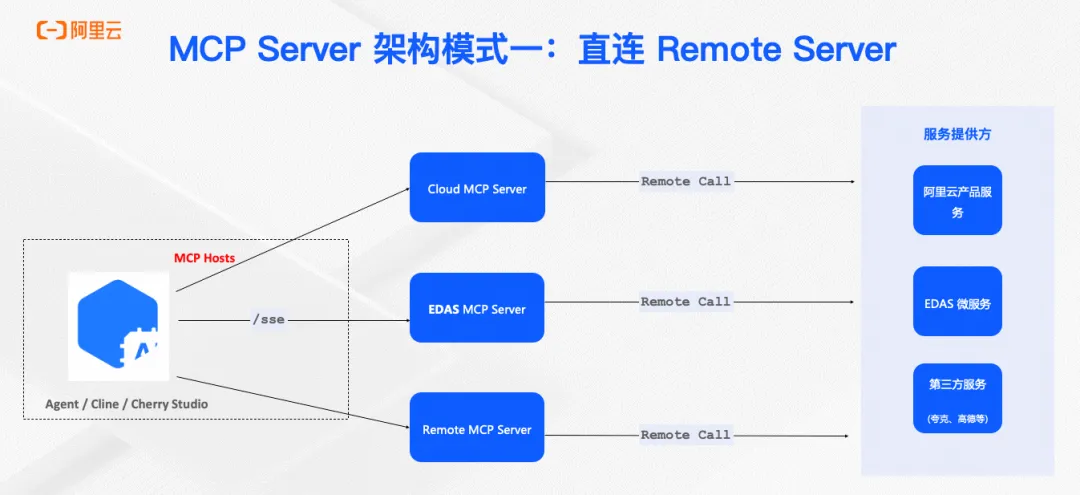
本文深入探讨了Model Context Protocol (MCP) 在企业级环境中的部署与管理挑战,详细解析了五种主流MCP架构模式(直连远程、代理连接远程、直连本地、本地代理连接本地、混合模式)的优缺点及适用场景,并结合Nacos服务治理框架,提供了实用的企业级MCP部署指南。通过Nacos MCP Router,实现MCP服务的统一管理和智能路由,助力金融、互联网、制造等行业根据数据安全、性能需求和扩展性要求选择合适架构。文章还展望了MCP在企业落地的关键方向,包括中心化注册、软件供应链控制和安全访问等完整解决方案。
本文围绕某线上客户部署DeepSeek-R1满血版模型时进行多次压测后,发现显存占用一直上升,从未下降的现象,记录了排查过程。

