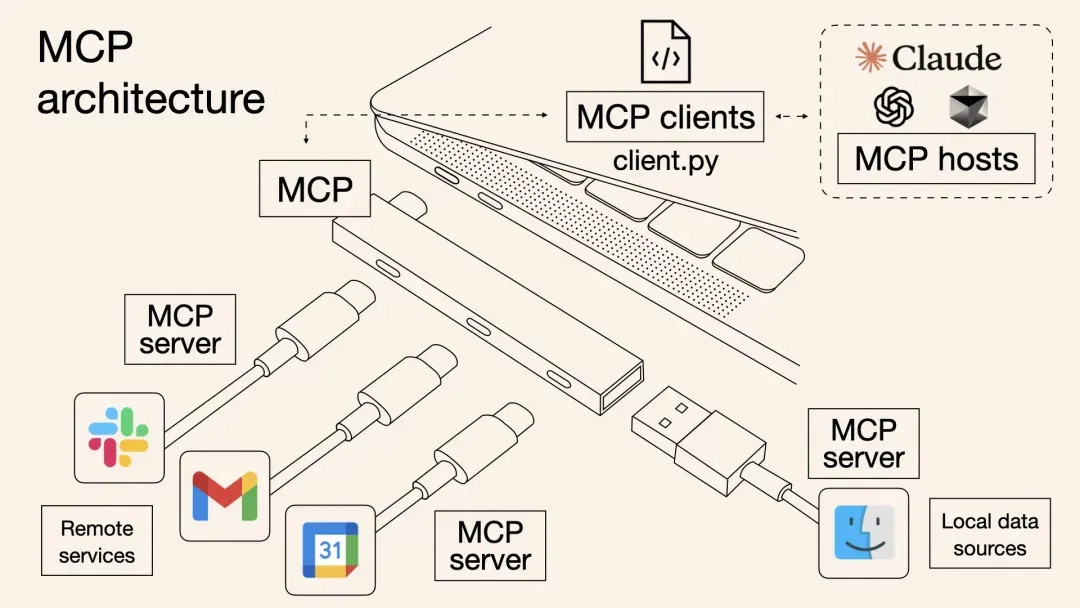
本文介绍了一种基于阿里云计算巢的一站式MCP工具解决方案,解决了传统MCP工具集成中的效率低下、调用方式割裂和动态管理困难等问题。方案通过标准化协议实现多MCP工具批量部署,提高云资源利用率,并支持OpenAPI与MCP双通道调用,使主流AI助手如Dify、Cherry Studio等无缝接入。内容涵盖背景、原理剖析、部署使用实战及问题排查,最后强调MCP协议作为“通用语言”连接数字与物理世界的重要性。
本文介绍了如何使用 llmaz 快速部署基于 vLLM 的大语言模型推理服务,并结合 Higress AI 网关实现流量控制、可观测性、故障转移等能力,构建稳定、高可用的大模型服务平台。
今天,来自 Qwen1.5 开源家族的新成员,代码专家模型 CodeQwen1.5开源!CodeQwen1.5 基于 Qwen 语言模型初始化,拥有 7B 参数的模型,其拥有 GQA 架构,经过了 ~3T tokens 代码相关的数据进行预训练,共计支持 92 种编程语言、且最长支持 64K 的上下文输入。效果方面,CodeQwen1.5 展现出了优秀的代码生成、长序列建模、代码修改、SQL 能力等,该模型可以大大提高开发人员的工作效率,并在不同的技术环境中简化软件开发工作流程。

年会中的抽奖环节不可或缺,但每年为了选择合适的抽奖小程序,团队往往需要投入大量时间和精力。然而,抽奖结束后,参与者通常只记得自己是否中奖,其他细节多被遗忘。在 AI 技术日益成熟的今天,如何打造一个既高效又有技术含量的抽奖应用呢?今天,就让我们跟随通义灵码,仅用 5 分钟现场手撕一个抽奖应用吧!
接下来,人与智能体的交互将变得更为紧密,比如 N 年以后是否可以逐渐过渡。这个逐渐过渡的过程实际上是温和的,从依赖人类到依赖超大规模算力的转变,可能会取代我们的一些职责。这不仅仅是简单的叠加关系。对于AI和超大规模算力,这是否意味着我们可以大幅度提升软件质量,是否可以缩短研发周期并提高效率,还有创造出更优质的软件并持续发展,这无疑是肯定的。
MCP Specification 在 2025-03-26 发布了最新的版本,本文对主要的改动进行详细介绍和解释
通义灵码支持MCP工具使用,通过模型自主规划实现工具调用,深度集成魔搭MCP广场,涵盖2400+热门服务。提供STDIO和SSE两种通信模式,适用于不同场景需求。用户可通过智能体模式调用MCP工具,完成如网页内容抓取、天气查询等任务。文档详细介绍了服务配置、使用流程及常见问题解决方法,助力开发者高效拓展AI编码能力。
简介:本文整理自阿里云高级技术专家李麟在Flink Forward Asia 2025新加坡站的分享,介绍了Flink 2.1 SQL在实时数据处理与AI融合方面的关键进展,包括AI函数集成、Join优化及未来发展方向,助力构建高效实时AI管道。
