本文探讨了AI应用在实际落地过程中面临的三大核心问题:如何高效使用AI模型、控制成本以及保障输出质量。文章详细分析了AI应用的典型架构,并提出通过全栈可观测体系实现从用户端到模型推理层的端到端监控与诊断。结合阿里云的实践经验,介绍了基于OpenTelemetry的Trace全链路追踪、关键性能指标(如TTFT、TPOT)采集、模型质量评估与MCP工具调用观测等技术手段,帮助企业在生产环境中实现AI应用的稳定、高效运行。同时,针对Dify等低代码平台的应用部署与优化提供了具体建议,助力企业构建可扩展、可观测的AI应用体系。
代价估计是优化其中非常重要的一个步骤,研究代价估计的原理和MySQL的具体实现对做SQL优化是非常有帮助。本文有案例有代码,由浅入深的介绍了代价估计的原理和MySQL的具体实现。
阿里云云原生数据仓库AnalyticDB MySQL(ADB-M)与被OpenAI收购的实时分析数据库Rockset对比,两者在架构设计上有诸多相似点,例如存算分离、实时写入等,但ADB-M在多个方面展现出了更为成熟和先进的特性。ADB-M支持更丰富的弹性能力、强一致实时数据读写、全面的索引类型、高吞吐写入、完备的DML和Online DDL操作、智能的数据生命周期管理。在向量检索与分析上,ADB-M提供更高检索精度。ADB-M设计原理包括分布式表、基于Raft协议的同步层、支持DML和DDL的引擎层、高性能低成本的持久化层,这些共同确保了ADB-M在AI时代作为实时数据仓库的高性能与高性价比
年会中的抽奖环节不可或缺,但每年为了选择合适的抽奖小程序,团队往往需要投入大量时间和精力。然而,抽奖结束后,参与者通常只记得自己是否中奖,其他细节多被遗忘。在 AI 技术日益成熟的今天,如何打造一个既高效又有技术含量的抽奖应用呢?今天,就让我们跟随通义灵码,仅用 5 分钟现场手撕一个抽奖应用吧!
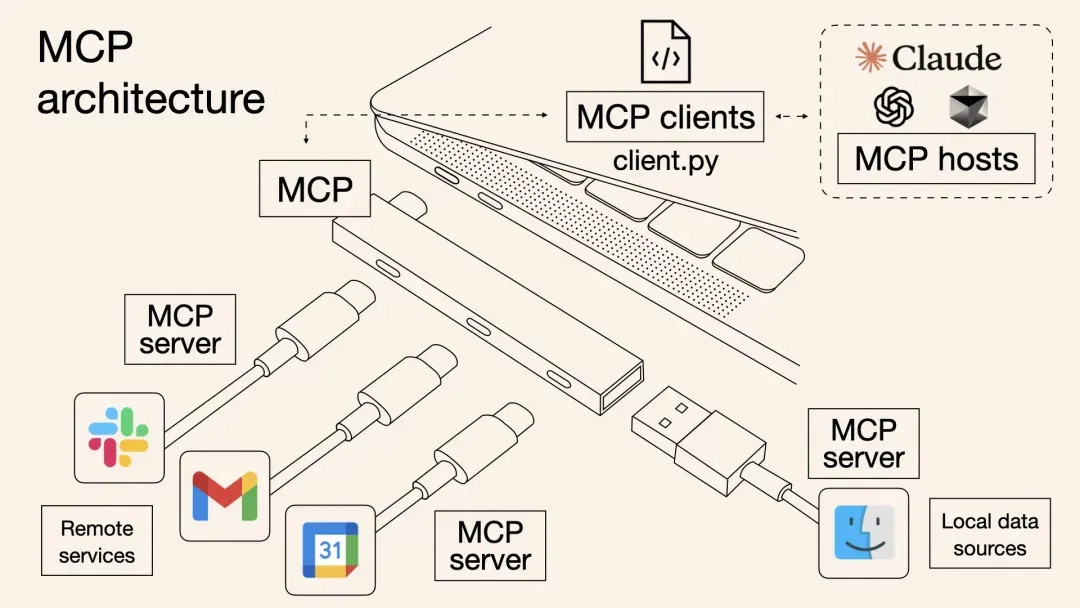
通义灵码支持MCP工具使用,通过模型自主规划实现工具调用,深度集成魔搭MCP广场,涵盖2400+热门服务。提供STDIO和SSE两种通信模式,适用于不同场景需求。用户可通过智能体模式调用MCP工具,完成如网页内容抓取、天气查询等任务。文档详细介绍了服务配置、使用流程及常见问题解决方法,助力开发者高效拓展AI编码能力。
本文介绍了一种基于阿里云计算巢的一站式MCP工具解决方案,解决了传统MCP工具集成中的效率低下、调用方式割裂和动态管理困难等问题。方案通过标准化协议实现多MCP工具批量部署,提高云资源利用率,并支持OpenAPI与MCP双通道调用,使主流AI助手如Dify、Cherry Studio等无缝接入。内容涵盖背景、原理剖析、部署使用实战及问题排查,最后强调MCP协议作为“通用语言”连接数字与物理世界的重要性。
本文介绍了如何使用 llmaz 快速部署基于 vLLM 的大语言模型推理服务,并结合 Higress AI 网关实现流量控制、可观测性、故障转移等能力,构建稳定、高可用的大模型服务平台。
