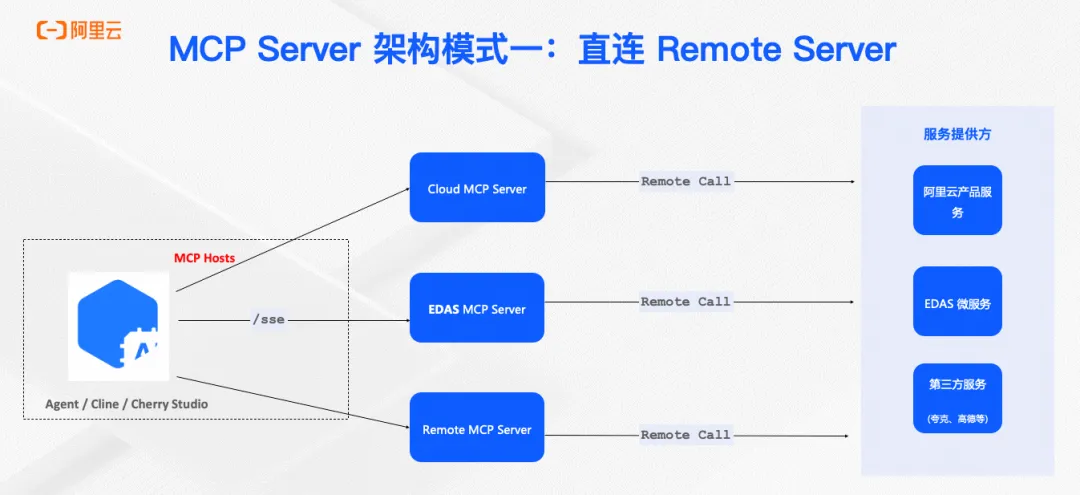
本文深入探讨了Model Context Protocol (MCP) 在企业级环境中的部署与管理挑战,详细解析了五种主流MCP架构模式(直连远程、代理连接远程、直连本地、本地代理连接本地、混合模式)的优缺点及适用场景,并结合Nacos服务治理框架,提供了实用的企业级MCP部署指南。通过Nacos MCP Router,实现MCP服务的统一管理和智能路由,助力金融、互联网、制造等行业根据数据安全、性能需求和扩展性要求选择合适架构。文章还展望了MCP在企业落地的关键方向,包括中心化注册、软件供应链控制和安全访问等完整解决方案。
本文以构建AIGC落地应用ChatBot和构建AI Agent为例,从代码级别详细分享AI框架LangChain、阿里云通义大模型和AnalyticDB向量引擎的开发经验和最佳实践,给大家快速落地AIGC应用提供参考。
通过遵循以上最佳实践,可以构建一个高效、可靠的 RAG 系统,为用户提供准确和专业的回答。这些实践涵盖了从文档处理到系统配置的各个方面,能够帮助开发者构建更好的 RAG 应用。
本文介绍了Ganos H3的相关功能,帮助读者快速了解Ganos地理网格的重要特性与应用实践。H3是Uber研发的一种覆盖全球表面的二维地理网格,采用了一种全球统一的、多层次的六边形网格体系来表示地球表面,这种地理网格技术在诸多业务场景中得到广泛应用。Ganos不仅提供了H3网格的全套功能,还支持与其它Ganos时空数据类型进行跨模联合分析,极大程度提升了客户对于时空数据的挖掘分析能力。
Nacos社区推出MCP Router与MCP Registry开源解决方案,助力AI Agent高效调用外部工具。Router可智能筛选匹配的MCP Server,减少Token消耗,提升安全性与部署效率。结合Nacos Registry实现服务自动发现与管理,简化AI Agent集成复杂度。支持协议转换与容器化部署,保障服务隔离与数据安全。提供智能路由与代理模式,优化工具调用性能,助力MCP生态普及。
LangChain为大型语言模型提供了一种全新的搭建和集成方式,通过这个强大的框架,我们可以将复杂的技术任务简化,让创意和创新更加易于实现。本文从LangChain是什么到LangChain的实际案例到智能体的快速发展做了全面的讲解。

本文描述DeepSeek的三个模型的学习过程,其中DeepSeek-R1-Zero模型所涉及的强化学习算法,是DeepSeek最核心的部分之一会重点展示。

本文围绕某线上客户部署DeepSeek-R1满血版模型时进行多次压测后,发现显存占用一直上升,从未下降的现象,记录了排查过程。

