类目筛选
大模型推理优化实践:KV cache复用与投机采样
在本文中,我们将详细介绍两种在业务中实践的优化策略:多轮对话间的 KV cache 复用技术和投机采样方法。我们会细致探讨这些策略的应用场景、框架实现,并分享一些实现时的关键技巧。
速成RAG+Agent框架大模型应用搭建
本文侧重于能力总结和实操搭建部分,从大模型应用的多个原子能力实现出发,到最终串联搭建一个RAG+Agent架构的大模型应用。
AI开源框架:让分布式系统调试不再"黑盒"
Ray是一个开源分布式计算框架,专为支持可扩展的人工智能(AI)和Python应用程序而设计。它通过提供简单直观的API简化分布式计算,使得开发者能够高效编写并行和分布式应用程序 。Ray广泛应用于深度学习训练、大规模推理服务、强化学习以及AI数据处理等场景,并构建了丰富而成熟的技术生态。

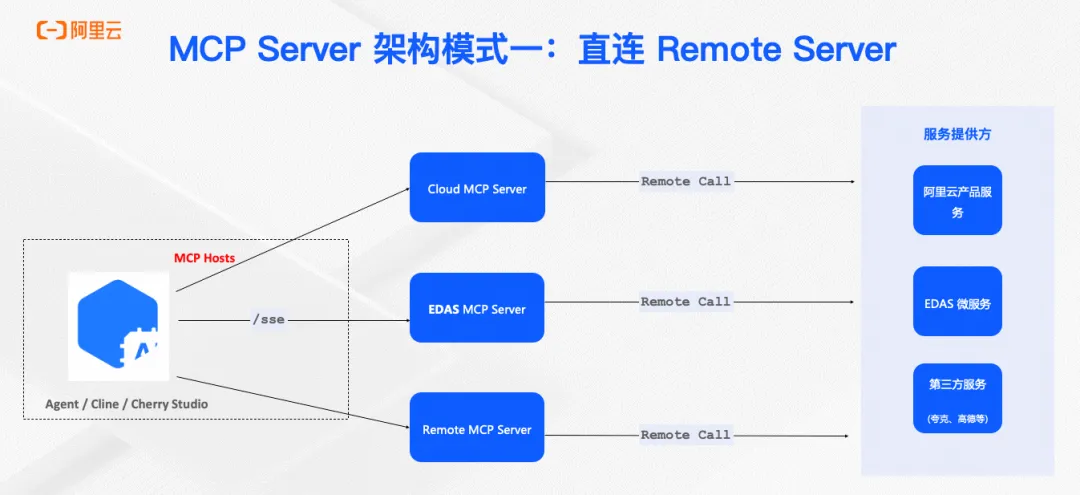
MCP Server的五种主流架构与Nacos的选择
本文深入探讨了Model Context Protocol (MCP) 在企业级环境中的部署与管理挑战,详细解析了五种主流MCP架构模式(直连远程、代理连接远程、直连本地、本地代理连接本地、混合模式)的优缺点及适用场景,并结合Nacos服务治理框架,提供了实用的企业级MCP部署指南。通过Nacos MCP Router,实现MCP服务的统一管理和智能路由,助力金融、互联网、制造等行业根据数据安全、性能需求和扩展性要求选择合适架构。文章还展望了MCP在企业落地的关键方向,包括中心化注册、软件供应链控制和安全访问等完整解决方案。
【算法精讲系列】通义模型Prompt调优的实用技巧与经验分享
本文详细阐述了Prompt的设计要素,包括引导语、上下文信息等,还介绍了多种Prompt编写策略,如复杂规则拆分、关键信息冗余、使用分隔符等,旨在提高模型输出的质量和准确性。通过不断尝试、调整和优化,可逐步实现更优的Prompt设计。
GraphRAG:基于PolarDB+通义千问+LangChain的知识图谱+大模型最佳实践
本文介绍了如何使用PolarDB、通义千问和LangChain搭建GraphRAG系统,结合知识图谱和向量检索提升问答质量。通过实例展示了单独使用向量检索和图检索的局限性,并通过图+向量联合搜索增强了问答准确性。PolarDB支持AGE图引擎和pgvector插件,实现图数据和向量数据的统一存储与检索,提升了RAG系统的性能和效果。
Post-Training on PAI (4):模型微调SFT、DPO、GRPO
阿里云人工智能平台 PAI 提供了完整的模型微调产品能力,支持 监督微调(SFT)、偏好对齐(DPO)、强化学习微调(GRPO) 等业界常用模型微调训练方式。根据客户需求及代码能力层级,分别提供了 PAI-Model Gallery 一键微调、PAI-DSW Notebook 编程微调、PAI-DLC 容器化任务微调的全套产品功能。
内附原文|详解SIGMOD’24最佳论文:PolarDB破解多主架构经典难题
在今年的SIGMOD会议上,阿里云瑶池数据库团队的论文《PolarDB-MP: A Multi-Primary Cloud-Native Database via Disaggregated Shared Memory》获得了Industry Track Best Paper Award,这是中国企业独立完成的成果首次摘得SIGMOD最高奖。PolarDB-MP是基于分布式共享内存的多主云原生数据库,本文将介绍这篇论文的具体细节。
