Flink冷备工作机制是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink 的冷备方案既支持 Flink 冷备,也支持 Kafka AZ 容灾,主要指消费两个同名的 Topic 和写出两个同名的 Topic。同名 Topic 在不同的 AZ 下,两个同名的 Topic 共同组成一份完整的数据。
这时如果上游的一个 Kafka 集群挂掉,Flink 会自动容灾,并推动 watermark 的前进,整个作业不受影响。Flink 在常规情况下,通过轮转写的方式,将数据写到下游的两个 Topic。如果一个 Topic 挂掉,数据会全部导到另一个 Topic。
针对 Flink 作业,我们会定期将快照写到备集群。一旦作业管理平台监测到 Flink 所在的 AZ 挂掉,会自动在备集群拉起一个一样的 Flink 作业。
未来,我们将实现 HDFS、Kafka 的双 AZ 部署,到时它们会自动 AZ 容灾并为 Flink 呈现逻辑视图。
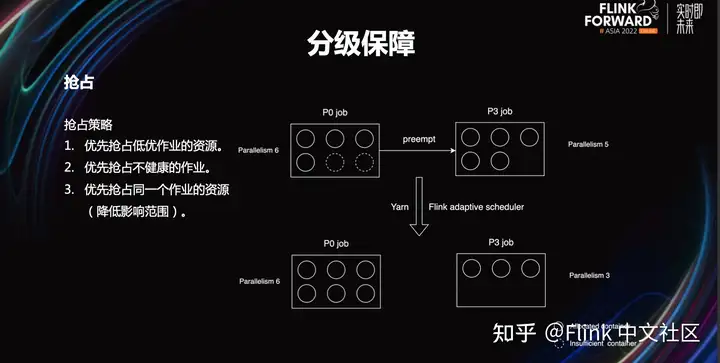
资源不足时的抢占方案。抢占策略主要有三点。
高优作业抢占低优作业资源。
优先抢占不健康的作业,比如 lag 严重的作业。
实时作业会优先抢占同一个作业的资源。
右图展示了我们的抢占效果。作业通过改造,在资源不足时,也能启动。

常见的保障措施,主要包括以下四点:
资源隔离。高优作业可以单独划定队列,实现物理隔离,同时不与离线作业混部。
资源抢占。在资源紧张情况下,高优作业可自动抢占低优作业的资源。
AZ 容灾。高优作业可实现 AZ 容灾,包括冷备和热备。
智能监控报警。高优作业配套的报警更加完善,一旦出现预期之外的问题可快速人工介入。
Flink冷备工作机制主要涉及到作业的高可用配置与故障转移能力。虽然提供的参考资料未直接详述Flink冷备的具体机制,但可以从相关文档中推断出一些关键点,结合Flink的通用知识来阐述冷备概念。
在Apache Flink中,冷备机制虽未直接命名,但其高可用(HA)部署模式间接实现了类似冷备的功能。Flink通过JobManager的高可用配置确保作业的持续运行和故障恢复。以下是Flink实现高可用的关键组件和步骤概述:
JobManager的HA配置:
ZooKeeper或其它协调服务:
Checkpoint机制:
状态与数据恢复:
Flink冷备工作机制主要是指在Flink集群发生故障时,通过预先设置好的备份机制来确保数据不丢失,并能够在另一个集群上快速恢复计算任务。具体来说,Flink冷备工作机制包括以下几个方面:
一、数据备份
快照(Snapshot)与保存点(Savepoint):Flink支持使用快照和保存点来保存作业的状态和数据。快照是Flink自动在特定时间间隔内创建的,用于恢复作业到故障发生前的状态。而保存点则是由用户手动触发的,具有更高的可靠性和灵活性。在冷备机制中,通常会定期创建保存点,并将其存储在可靠的存储系统中,如HDFS。
状态一致性:Flink确保在保存点创建时,作业的状态是一致的,即所有相关的数据都已经正确处理并更新到最新的状态。这样,在集群故障后,可以从最近的保存点恢复作业,而不会丢失数据或造成数据不一致。
二、集群恢复
集群故障检测:当Flink集群发生故障时,系统会检测到故障并触发恢复机制。这通常通过监控集群的健康状态、网络连接、资源使用等指标来实现。
冷备集群启动:在检测到主集群故障后,系统会立即在预配置的冷备集群上启动Flink作业。冷备集群通常是一个与主集群完全独立的集群,具有相同的配置和资源。
从保存点恢复:在冷备集群上启动作业时,Flink会从最近一次保存的保存点恢复作业的状态和数据。这包括所有的数据流、处理逻辑、状态信息等。恢复过程通常是自动的,不需要人工干预。
阿里云实时计算Flink版提供了冷备功能来确保数据的安全性。当主节点故障时,冷备节点会接管工作,确保作业连续性。具体的冷备工作机制包括:
主节点监控:主节点持续监控自身的运行状态。
故障检测:一旦主节点检测到异常,如崩溃或网络隔离。
冷备切换:冷备节点接收到故障信号后,开始接管主节点的角色。
作业恢复:冷备节点启动作业,确保数据处理不中断
Flink 冷备的主要特点包括:
并行双跑验证:在迁移或部署新版本时,通常采用新旧任务并行运行的方式,这不仅用于数据正确性验证
1
,也是冷备思想的一种体现。通过比较新旧任务的输出数据,确保新任务的数据质量和业务逻辑正确无误。
状态与数据同步:虽然直接描述冷备机制的文档未明确提及,但从数据正确性验证和状态管理的讨论中
1
2
,可以推断冷备作业需要一种机制来同步或初始化其状态,以便在切换时能无缝继续处理数据,这可能涉及Checkpoint机制的高效利用。
业务迁移与切换:一旦验证新任务(或备用任务)的数据正确性、性能和稳定性均符合要求,即可将业务流量从主作业切换到新作业
1
。此过程涉及结果表的替换及原生产链路的下线,确保服务的连续性。
参考文档:
https://help.aliyun.com/zh/flink/user-guide/perform-intelligent-deployment-diagnostics
当Flink系统检测到某个节点故障时,它会尝试进行“冷备”(cold backup)操作。冷备是指在正常节点运行的同时,创建一个新的节点来接管其任务。这个新节点会从上一个完整微批次的结束位置开始读取数据,并逐步赶上当前的微批次处理进度。在这个过程中,旧节点和新节点都会处理数据,但只有新节点才会写入最终的结果。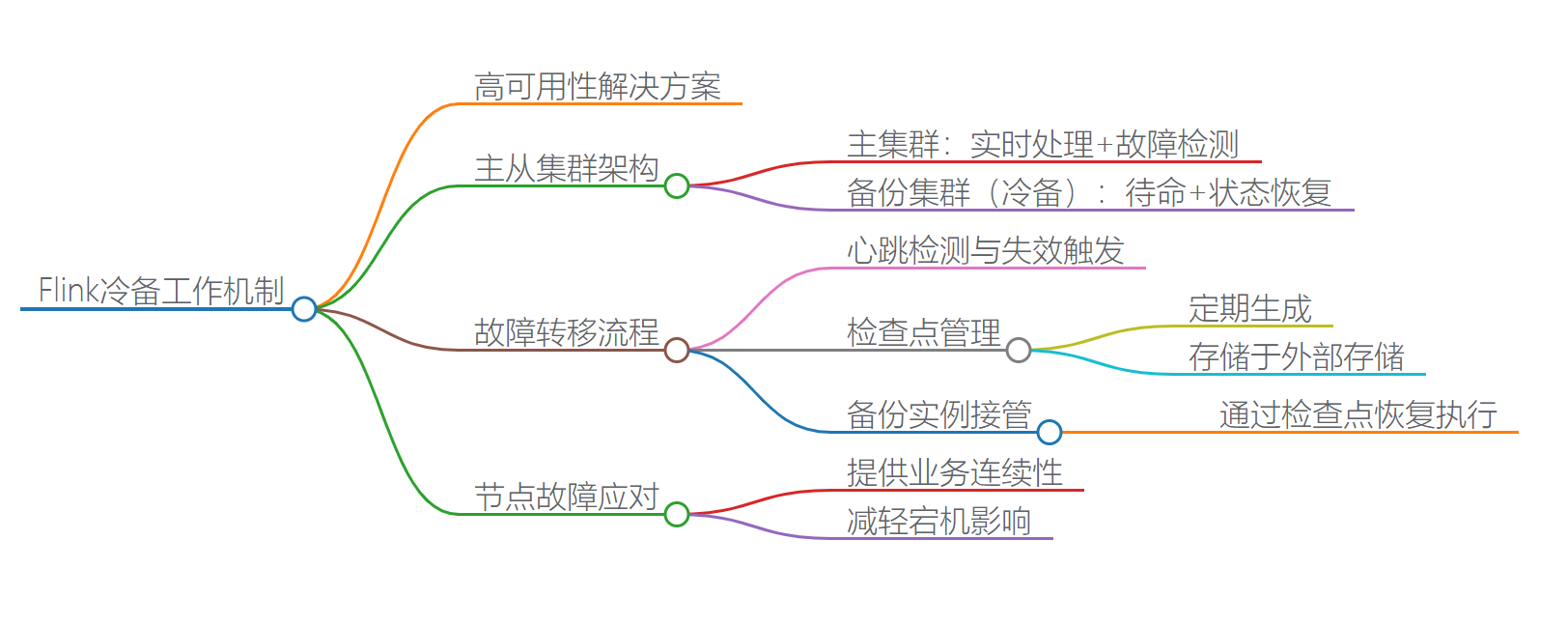
冷备主要指的是对数据做备份,集群挂掉以后可以快速在另外一个集群启动计算任务。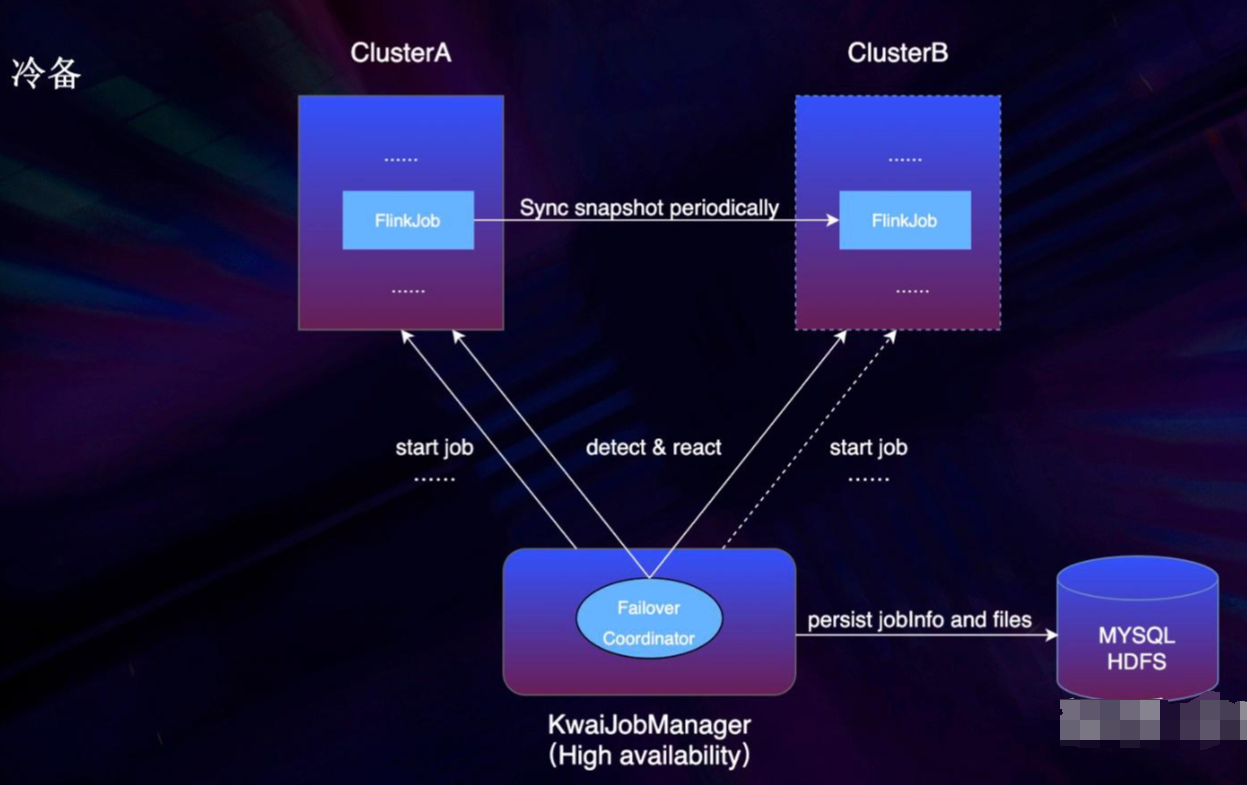
KwaiJobManager 是作业管理服务,其中的 failover coordinator 主要负责故障处理。把所有 jar 包等文件保存在 HDFS,所有的信息保存在 Mysql,这两者都做到了高可用。作业运行在主集群 ClusterA,线上用的是增量快照,会存在文件依赖的问题,所以我们定期做 savepoint 并拷贝到备集群。为了避免文件过多,我们设置了定时删除历史快照。
一旦服务检测到集群 A 故障,就会立刻在集群B启动作业,并从最近一次的快照恢复,确保了状态不丢失。对于用户来说,只需要设置一下主备集群,剩下的全都交由平台方来做,用户全程对故障无感知。
——参考链接。
Flink版提供了冷备机制来确保数据安全。它会定期将Flink作业的状态保存到持久化存储中,如阿里云的OSS。在发生故障时,系统能够利用这些备份状态快速恢复作业,减少数据丢失并保证业务连续性。
对于依赖实时流的业务而言,Flink计算所依赖的消息队列集群或者Flink的集群以及强依赖的其他组件发生故障带来的影响都是灾难性的。为保障整体Pipeline的整体稳定性,我们采用了备份容灾的方案。主备链路使用相互隔离的物理环境,以Pulsar集群和Flink集群为例,主备链路分别使用不同IDC的存储和计算集群。这里采用了冷备和热备两种方式。
冷备:在备份Pulsar集群预先准备好最原始的Source数据;在备份计算集群预先准备好计算任务(在主链路故障时刻启动)。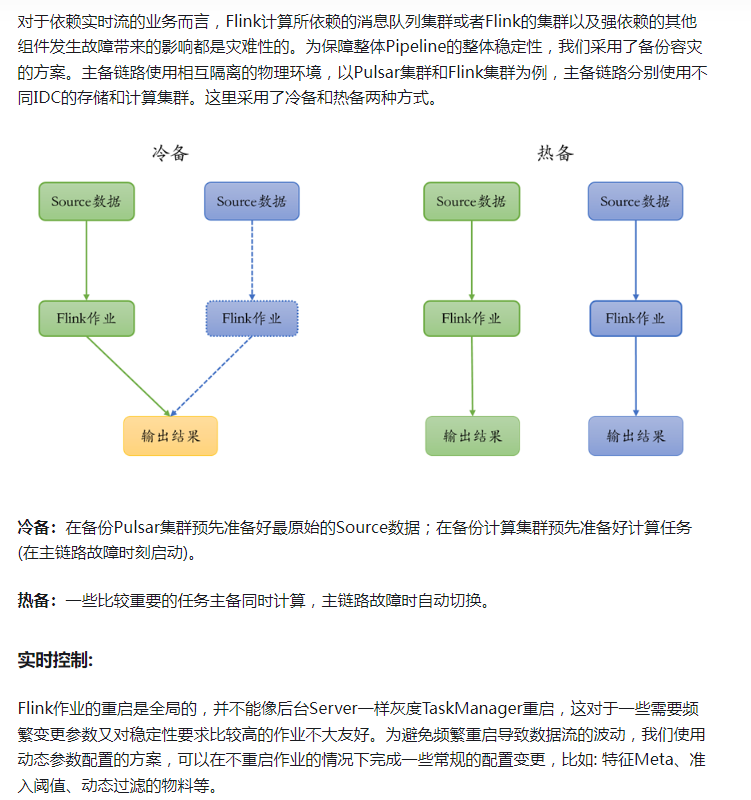
参考文档https://zhuanlan.zhihu.com/p/489051224
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。