有遇到过flink 一直重启的问题么? 运行了 3-4天 突然开始 重启,而且一直重启。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink 任务一直重启的问题可能由多种原因引起,包括但不限于资源不足、网络问题、配置错误、代码逻辑错误等。以下是一些排查和解决该问题的步骤:
检查日志:查看 Flink 任务的运行日志,特别是错误日志,以确定重启的具体原因。日志通常会提供有关故障的详细信息。
资源分配:检查 Flink 任务的资源分配情况,确保任务有足够的内存和 CPU 资源。如果资源不足,任务可能会因为 OOM(Out of Memory)等原因频繁重启。
网络稳定性:网络问题也可能导致 Flink 任务重启。检查网络连接的稳定性,确保任务能够正常通信。
配置检查:检查 Flink 配置文件(如 flink-conf.yaml),确保所有的配置项都是正确的,没有遗漏或错误的配置。
代码审查:如果任务是自定义的,检查代码逻辑是否有潜在的错误,比如死循环、无限递归等,这些都可能导致任务无限重启。
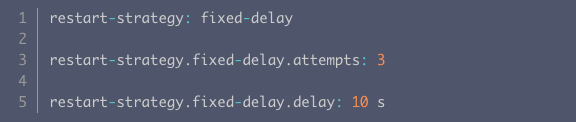
策略:策略**:检查 Flink 任务的重启策略配置。如果配置错误的重启错误的重启策略,可能会导致任务无限重启。
依赖问题:如果任务依赖外部服务或数据源,检查这些依赖是否稳定可靠。
操作系统和硬件问题:操作系统或硬件问题也可能导致 Flink 任务重启。检查操作系统日志和硬件监控工具,排除这些问题。
升级 Flink 版本:如果任务是在旧版本的 Flink 上运行,尝试升级到最新版本,新版本可能修复了一些已知的 bug。
社区支持:如果自己难以定位问题,可以寻求社区的帮助,分享你的配置和遇到的问题,社区成员可能会提供有价值的建议。
请记住,解决这类问题通常需要耐心和细致的排查。如果问题依然无法解决,可能需要专业的技术支持介入。
遇到Flink作业持续重启的问题,这可能是由多种因素引起的。这里有几个可能的原因及建议的排查方向:
任务优雅退出超时[1]:Flink作业在Failover或退出过程中,若Task因某些原因阻塞无法正常退出,超过默认180秒的超时时间,Flink会终止TaskManager以继续Failover流程。这可能导致看起来像是作业不断重启。检查自定义函数实现,如close方法是否有长时间阻塞或计算逻辑中是否存在长时间未返回的情况。可以通过调整task.cancellation.timeout参数来延长等待时间以便于调试,但请注意,这仅适用于调试目的,不推荐在生产环境中设置为0。
资源与性能瓶颈[2]:智能调优和定时调优功能可以帮助自动调整资源以应对不同时间段的负载变化,但它们有使用限制,且不保证解决所有性能问题。如果作业在特定时间点开始频繁重启,可能与资源分配不当或外部系统(如Sink性能、数据库死锁、数据总线容量不足)问题有关。检查作业运行的时间模式,适时调整资源计划,并关注外部依赖系统的稳定性。
相关链接
https://help.aliyun.com/zh/flink/support/faq-about-draft-development-and-deployment-operation
如果您的Flink作业运行一段时间后开始频繁重启,可能是由于多种原因,如资源不足、作业内部错误、网络问题或Checkpoint失败等。建议您检查作业日志以获取具体错误信息,同时关注TaskManager是否异常退出、网络是否稳定,以及Checkpoint配置是否合适。如果配置了Task快速重启,请注意数据丢失或重复的潜在风险。
还是再去深入分析Flink作业的日志,特别是重启时的日志信息,寻找具体的错误提示,如“Can not retract a non-existent record.”这类特定错误,它们可能指向问题的具体原因,如用户自定义函数实现不当等
TaskManager 的日志,查找异常数据或错误日志。确保数据格式正确,处理逻辑健壮。
监控资源使用情况,增加资源配置或优化作业逻辑以减少资源消耗。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。