我这边flink sql任务设置了SET 'table.exec.state.ttl' = '24h' 后,从savepoint恢复任务,请问怎么 还是全量读取数据呢? 去掉ttl设置后 从savepoint恢复 则执行正常
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink SQL 中,如果你设置了 SET 语句来改变某些配置,但这些配置可能与你的期望不符,那么可能会出现全量读取数据的情况。以下是一些可能的原因和解决方案:
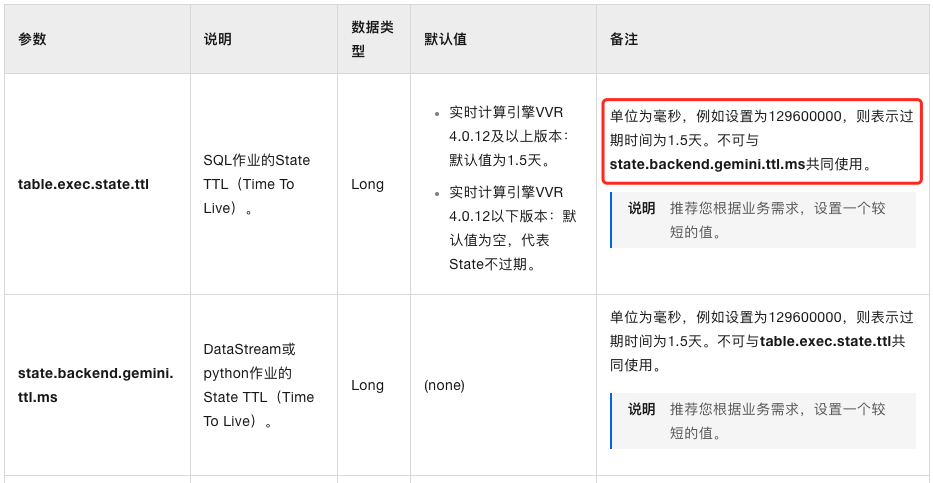
SET 'table.exec.state.ttl' = '1 hour';
SET 语句的范围
SET 语句可能只在特定的范围内有效。例如,如果你在一个会话中设置了某个属性,它可能不会影响到已经提交的作业。确保你的 SET 语句是在作业执行之前设置的。
作业重启
如果你更改了配置后没有重启作业,那么新的配置可能不会生效。你需要重启作业以使新的配置生效。
在您提到的场景中,Flink SQL任务设置了table.exec.state.ttl为24小时后,期望从savepoint恢复时能避免全量读取数据,但实际上仍进行了全量读取。当移除该TTL设置后,从savepoint恢复则恢复正常执行。这种情况可能与以下几个方面有关:
TTL参数的作用范围理解:table.exec.state.ttl参数是用来控制Flink SQL作业中状态的存活时间,即状态数据在多久之后被视为过期并被清理。它并不直接影响从savepoint恢复时的数据读取行为,特别是对于source的读取模式。
Savepoint机制:Savepoint是一个作业的快照,包含了作业运行时的所有状态信息,包括源数据的读取位置等。当从savepoint恢复时,Flink会尽可能地从savepoint中记录的位置继续读取数据,而不是根据TTL来决定读取模式<。
Source配置与读取模式:对于如CDC(Change Data Capture)源,其读取模式(如全量+增量或仅增量)通常由特定的配置项控制,例如MongoDB CDC的scan.startup.mode配置>。若从savepoint恢复后依然全量读取,可能是因为source的配置或其内部逻辑决定了在某些条件下忽略之前的状态信息,重新全量读取。
解决建议:
检查Source配置:确认您的数据源(如Kafka、MySQL CDC等)是否有特定的配置控制读取行为,特别是在使用savepoint恢复时。确保没有配置冲突或不当配置导致强制全量读取。
State TTL与Checkpoint/Savepoint区别:理解TTL主要影响状态数据的生命周期管理,而非直接干预从故障中恢复时的数据读取策略。如果目的是控制恢复时的数据处理起点,应关注于源的读取位置配置或Checkpoint/savepoint的正确使用。
测试与验证:在调整配置后,建议先在非生产环境进行测试,观察从savepoint恢复时的行为是否符合预期,以避免对生产数据造成影响。
综上所述,table.exec.state.ttl设置不影响从savepoint恢复时的数据读取模式,需检查并调整数据源的读取配置以解决全量读取的问题。
当您设置table.exec.state.ttl为24小时后,如果State在该时间后过期,新数据进来不会触发更新输出。这可能是由于State在保存点时已过期,导致恢复后无法正确处理新数据。若去掉TTL设置,任务恢复正常,表明依赖于旧状态的数据处理逻辑存在问题。建议在需要使用TTL的情况下,确保State在保存点时是有效的,或者调整TTL以适应您的业务需求。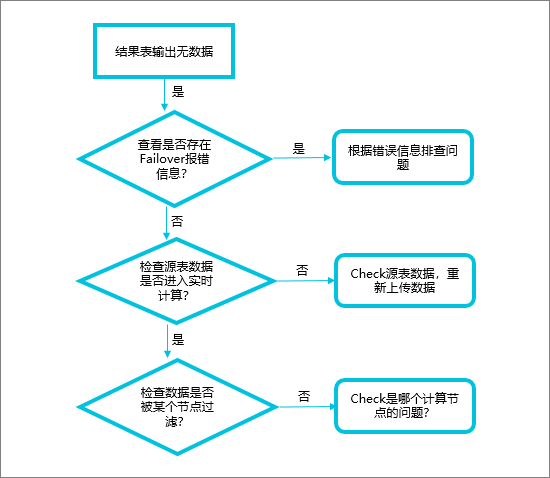
当你在Flink SQL任务中设置了table.exec.state.ttl为24小时,这意味着状态将被定期清理以减少内存占用。这个设置对于减少状态存储空间是有帮助的,但同时也可能会影响从savepoint恢复的行为。
State TTL: 当你设置了table.exec.state.ttl,Flink会定期清理过期的状态。如果状态过期了,在从savepoint恢复时,可能无法恢复到完全一致的状态点。
Savepoint: Savepoint保存了所有正在处理的数据的状态快照。当一个作业从savepoint恢复时,它试图恢复到与上次保存时相同的点。
全量读取: 如果你在设置table.exec.state.ttl之后发现作业从savepoint恢复时仍然进行全量读取,这可能是由于以下原因:
调整TTL设置:
table.exec.state.ttl的值,以确保在创建savepoint期间状态不会被清理。table.exec.state.ttl.check-interval来减少检查频率,从而降低状态被清理的风险。Savepoint策略:
table.exec.state.ttl为一个非常大的值(如'1y'),这样在创建savepoint时状态不会被清理。table.exec.state.ttl设置回原来的值。测试:
监控:
文档和社区支持:
请尝试上述建议,并观察结果。如果你还需要进一步的帮助,请随时告诉我。
你要知道 TTL参数应用范围理解,首先,确认table.exec.state.ttl参数是用来控制Flink作业中状态数据的生命周期,即状态数据在多久之后会被自动清除。这个设置不会直接影响到从Savepoint恢复时的数据读取行为,它主要作用于作业运行期间的状态管理,比如检查点和状态后端的清理策略
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。