版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
你的这个错误信息 ODPS-0123065: Join exception - Hash Join Cursor small table exceeds limitation 指的是在使用MaxCompute进行哈希连接(Hash Join)操作时遇到了问题。错误指出哈希连接中的小表(build side)使用的内存超出了限制。MaxCompute为了优化性能,会对参与连接的较小表进行全表扫描并构建哈希表,而这个过程中的内存使用不能超过预设的上限。
在你提供的链接里错误详情提供了以下关键信息:
HashJoin1, HashJoin2, 和 HashJoin3 分别使用了大约6.7GB的内存。HashJoin3的构建阶段。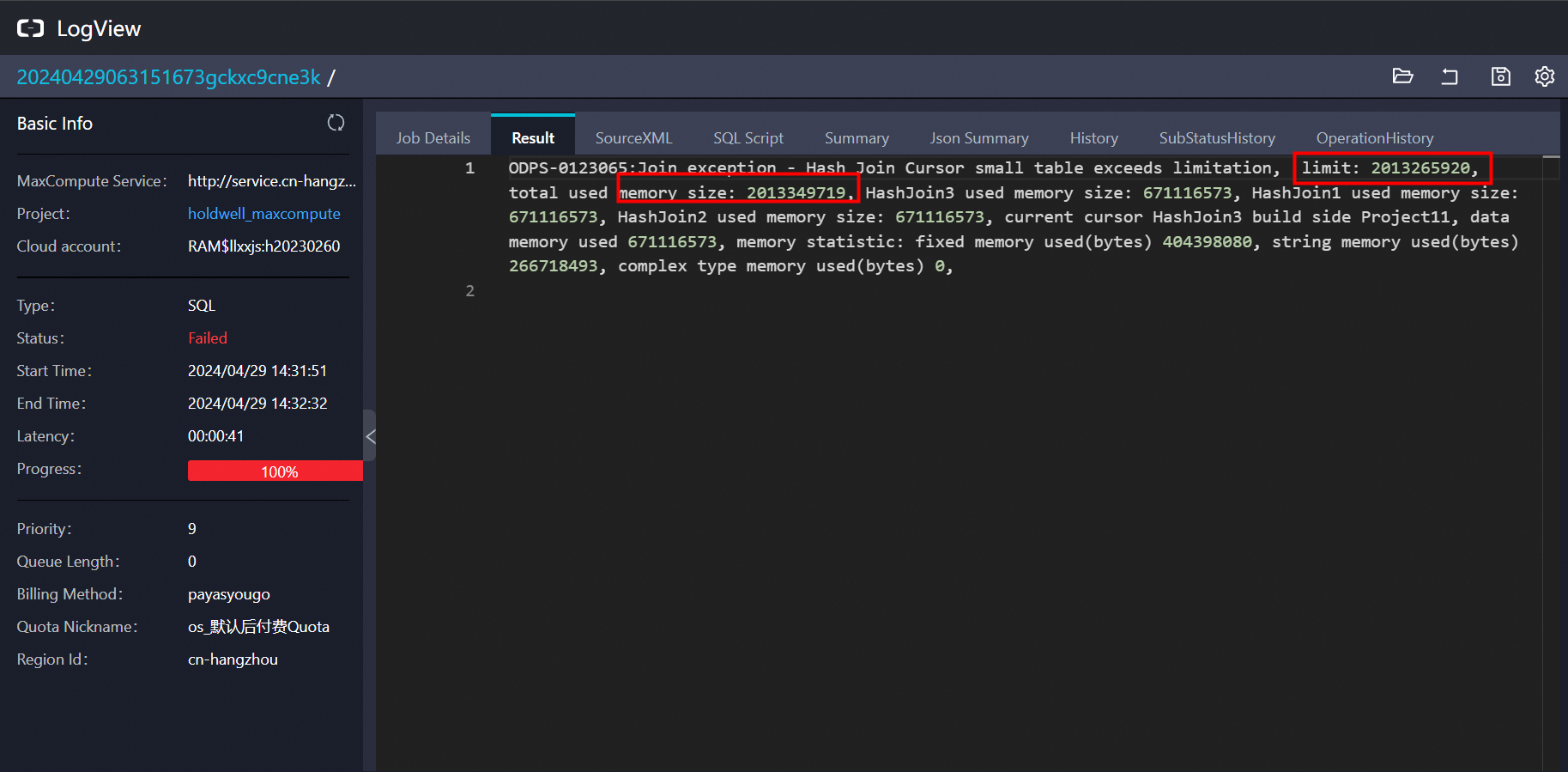
解决这个问题的可能方法有: 优化数据处理逻辑:检查是否可以通过优化查询逻辑,比如预先过滤掉不必要的数据,来减少参与连接的数据量。调整分区策略:如果数据是分区存储的,确保分区裁剪有效,以减少需要加载到内存中的数据量。增加内存配额:如果业务需求允许且资源充足,尝试联系阿里云客服或通过管理控制台调整作业的内存限制。这可能涉及成本增加。改用其他连接类型:如果哈希连接因内存限制而不适用,考虑是否可以改为使用其他类型的连接,如排序合并连接(Sort Merge Join),尽管这可能会影响性能。数据倾斜处理:检查是否存在数据倾斜问题,即某一分区的数据量远大于其他分区,这可能导致单个哈希连接步骤内存使用激增。解决数据倾斜可以缓解这个问题。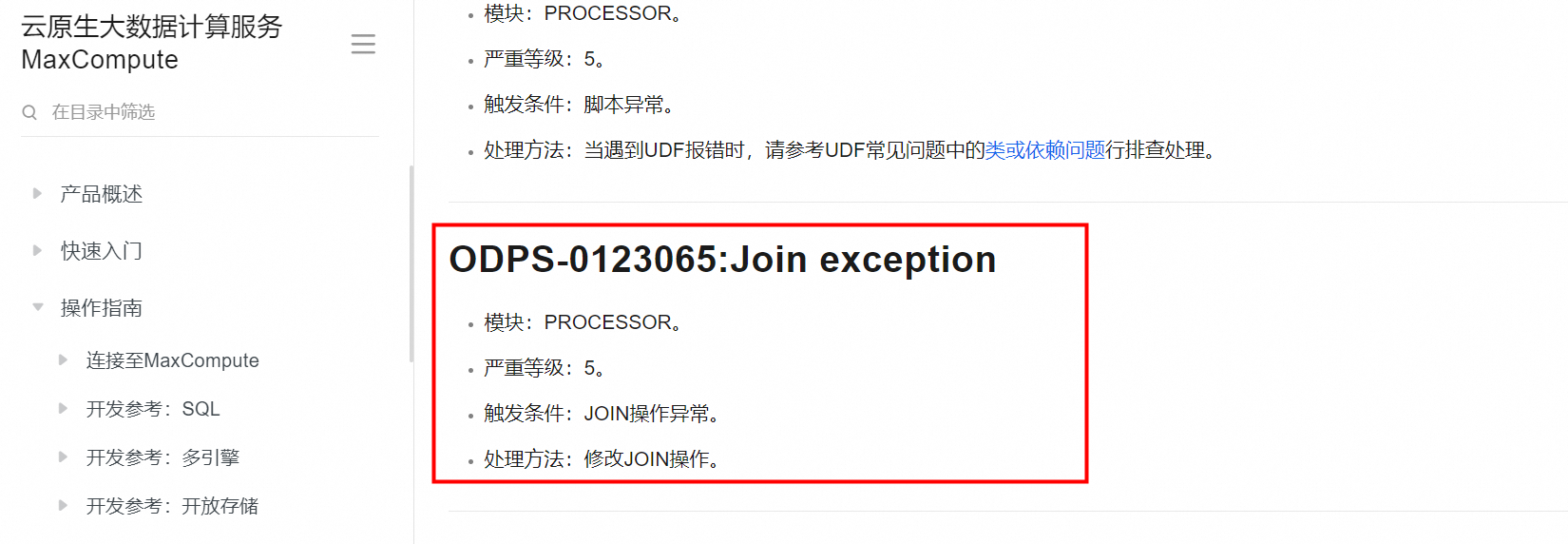
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。