
现在只有不到3T的mc存储,为什么DataWorks的数据地图昨天,前天,大前天,都是近5t的存储,但是mc的显示总量是正确的?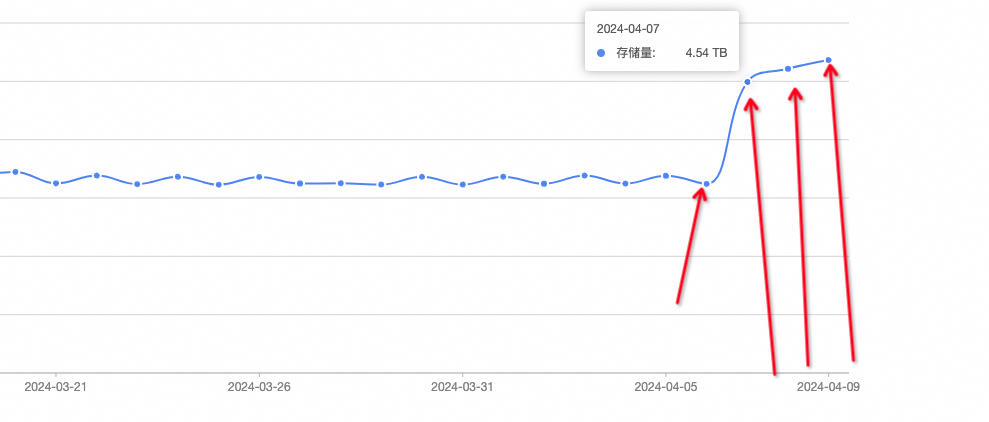
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的情况,DataWorks数据地图中显示的存储量与MaxCompute(MC)实际存储量存在差异。以下是可能的原因及详细解释:
DataWorks数据地图中的存储趋势图(折线图)展示的是某一时刻的快照数据,而MaxCompute的存储总量是实时计算的结果。如果当前计算任务较少(例如产生的临时表较少),两者之间可能会出现较大差距。
因此,数据地图中显示的近5TB存储可能是之前某个时间点的快照值,而MaxCompute的存储总量(不到3TB)则是最新的实时数据。
在MaxCompute中,计算任务可能会生成大量的临时表。这些临时表在任务完成后会被自动清理,但在数据地图的存储趋势图中可能会被短暂记录,导致趋势图显示的存储量高于实际存储量。
数据地图依赖于元数据的采集和同步。如果元数据同步存在延迟,可能会导致数据地图中的存储趋势图未能及时反映最新的存储变化。
为了进一步确认问题并解决存储量不一致的情况,您可以采取以下步骤:
如果怀疑元数据同步延迟,可以手动刷新表的元数据: - 在数据地图中,进入我的数据 > 刷新表元数据页面。 - 输入odps.项目名称.表名称格式的表GUID,单击刷新以更新元数据。
SELECT SUM(size) AS total_storage FROM information_schema.tables WHERE table_schema = 'your_project_name';
如果上述方法无法解决问题,建议联系阿里云技术支持团队,提供具体的项目信息和存储量差异情况,以便进一步排查。
通过以上分析和操作,您可以更好地理解存储量差异的原因,并采取相应措施解决问题。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。

