
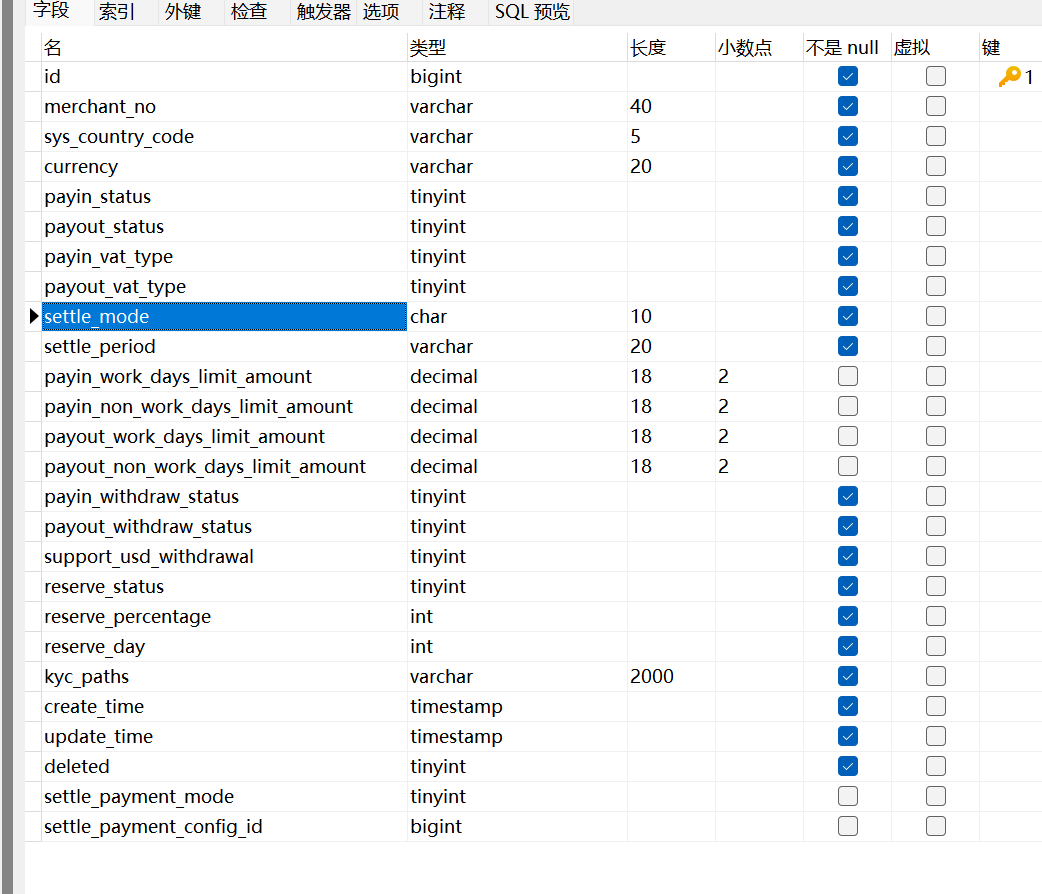
DataWorks在数据集成时,默认的建表结构是这样的;mysql 中这个表结构是;一个整数位14一个整数位16,会导致过长的数据存不了数仓来?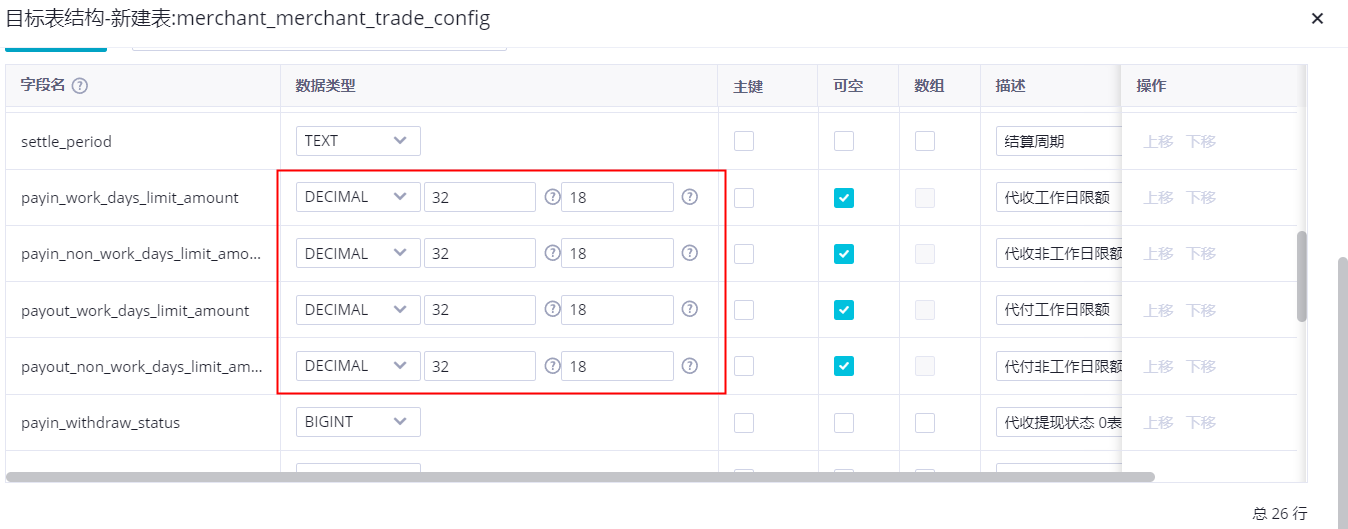
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云DataWorks进行数据集成时,如果遇到由于默认建表结构导致过长的数据无法存入数据仓库的情况,通常是因为某些字段的数据类型或长度限制不够。例如,某个文本字段在源系统中的长度超过了数据仓库中对应字段的预设长度,从而导致同步失败或数据截断。
解决这种问题的方法如下:
调整目标表结构:
登录到DataWorks界面,定位到目标数据仓库中的表结构设计。
根据源系统的数据特点,修改目标表中对应字段的数据类型和长度,确保能够容纳最长的数据记录。例如,增加VARCHAR类型的字段长度,或者使用TEXT类型来支持更长的字符串。
自定义数据同步任务的字段映射:
在创建或编辑数据同步任务时,明确指定每个字段的映射规则,包括数据类型和长度。
如果DataWorks支持,可以设置动态映射规则或通过脚本自定义处理逻辑,保证过长数据在写入数据仓库之前得到适当处理(如截取、拆分或压缩)。
监控和预警:
设置合理的数据质量监控规则,以便在数据同步过程中及时发现过长数据的问题,并发出预警。
业务逻辑优化:
考虑源系统是否有必要生成如此长的数据,或者数据仓库中是否真的需要存储完整的原始数据。有时可通过业务逻辑优化或数据清洗过程来避免过长数据的产生。
总之,确保在进行数据集成时充分理解源数据和目标数据结构的需求,合理规划表结构,并针对性地调整数据同步任务的配置。对于复杂情况,建议参考阿里云DataWorks的官方文档或联系技术支持获取专业的帮助和指导。
默认一键建表应该是(38,18)看下odps project是不是有开启hive兼容等情况,
https://help.aliyun.com/zh/maxcompute/user-guide/data-type-editions?spm=a2c4g.11186623.0.i2 ,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


