大数据计算MaxCompute数据是按照分区存储的吗,要是一个数据每天都同步的话会不会导致数据重复?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
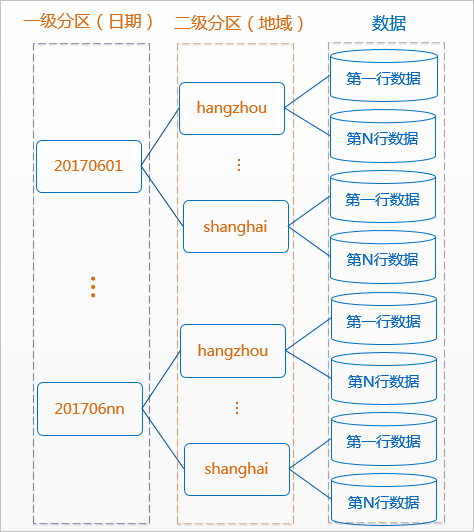
是的,阿里云的大数据计算服务 MaxCompute 中的数据是按照分区(Partition)进行存储的。对于每天都会同步的数据,如果按照日期作为分区字段进行组织,比如每天的数据存放在对应的日期分区中,则不会因为每天同步而导致数据重复。
例如,如果数据表 my_table 按照 dt 字段(表示日期)进行了分区,每天的新数据应当写入到当天的分区,如 dt=20240325 的分区。这样一来,即使每天同步数据,只要确保同步的数据插入到正确的分区,就不会出现数据重复的现象。
为了防止重复,还可以在同步过程中加入去重逻辑,例如使用唯一键约束(在 MaxCompute 中可能是通过特定的 DDL 语句实现),或者在数据加载前进行预处理,去除重复数据。
此外,在使用阿里云 DataWorks 进行数据同步时,应确保每次同步操作是针对目标分区进行的,而不是覆盖整个表,这样才能保证数据的一致性和完整性。
MaxCompute数据是按照分区存储的,并且数据同步机制设计上避免了数据重复的问题。
MaxCompute是一个面向海量数据处理的平台,它支持PB级别的数据分析,并提供数据仓库和BI分析等服务。在存储方面,MaxCompute提供了结构化存储的功能,用户可以根据需要创建分区表和非分区表来组织数据。分区表的使用可以使得数据的管理更加高效,尤其是在处理大规模数据集时,通过分区可以加快查询速度和简化数据维护工作。
MaxCompute的数据同步功能非常灵活,支持全增量一体化同步,即先进行全量迁移,然后实时同步增量数据至目标端。DataWorks数据集成工具为这一过程提供了强大的支持,包括离线同步、实时同步等多种数据集成作业类型。此外,DataHub支持将数据同步到MaxCompute对应的数据表中,同时支持分区表和非分区表,一般情况下推荐使用分区表进行数据同步以方便数据处理。
为了避免数据重复,MaxCompute的数据同步工具和平台通常包含了去重的逻辑。例如,在创建实时同步任务时,系统会首先进行全量迁移,确保所有历史数据被准确记录,随后仅同步新增的数据变更。这种设计确保了即使在每天同步的情况下,也不会出现数据重复的问题。
综上所述,MaxCompute不仅提供了高效的数据存储方式,其数据同步机制也考虑了避免数据重复的需求,使得用户可以安心地进行日常的数据同步工作。
在 MaxCompute 中,数据是按照分区(Partition)进行存储的。分区是一种逻辑概念,用于将数据按照指定的列进行分组存储,便于查询和管理。通常,按照时间字段(比如日期)作为分区进行存储是比较常见的做法,例如按照每天的日期作为一个分区存储数据。
当数据每天都同步到 MaxCompute 中时,如果按照日期作为分区进行存储,那么每天同步的数据会被存储到对应日期的分区中。这样设计可以有效避免数据重复的问题,因为不同日期的数据会被存储到不同的分区中,数据同步不会导致数据重复。
如果数据同步过程中存在需要避免重复数据的情况,可以在同步过程中进行去重操作,或者在写入数据前进行检查,确保不会插入重复的数据。此外,也可以通过数据清洗和数据校验等方式来确保数据的准确性和完整性。
总的来说,MaxCompute 的按分区存储设计可以很好地支持每天数据同步的场景,并且合理利用分区可以避免数据重复的问题。在具体实施过程中,可以根据业务需求和数据特点进行相应的操作和优化,确保数据同步的效率和准确性。
如果同步的是分区表,是按照分区存储。 会重复。因为MaxCompute 普通表不支持主键,只能单独去重 ,此回答整理自钉群“MaxCompute开发者社区2群”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。