
Hologres中flink sink hologres要设置啥参数吗?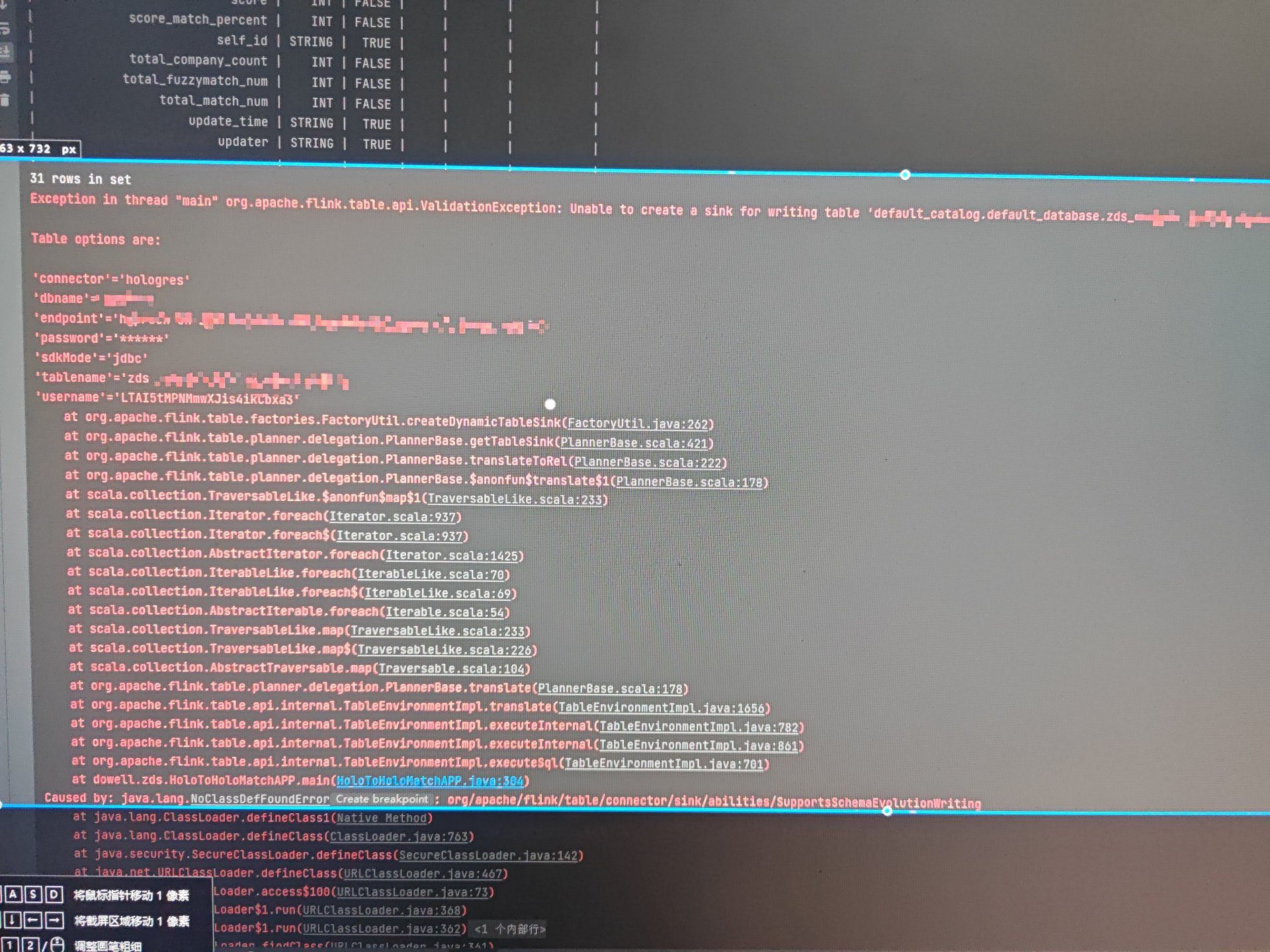
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink将数据写入Hologres时,需要设置一些关键的参数。首先,你需要提供数据库的URL,这是连接到Hologres实例所必需的。其次,用户名和密码也是必要的,用于在数据库中进行身份验证。此外,还需要提供目标表的名称。
如果你的Hologres实例是2.0及以上版本,需要注意的是,由于Hologres 2.0及以上版本下线了rpc服务,此时如果你将连接参数配置为rpc,Flink系统将自动切换该参数值为jdbc_fixed。
除了这些基本的连接参数外,你还需要提供一些写入参数。比如,你可以指定写入的数据格式,可以是CSV或者JSON。还可以指定写入的模式,比如是否按照主键去重(Exactly once),以及是否支持整行数据的局部更新等。
最后,关于数据类型映射,当前Flink全托管与Hologres的数据类型映射请参见 Blink/Flink与Hologres的数据类型映射。
通过以上参数的配置,就可以实现将Flink中的数据成功写入Hologres。
在Hologres中使用Flink的sink连接到Hologres时,需要设置以下参数:
jdbcUrl: 指定连接Hologres的JDBC URL。格式为jdbc:postgresql://<host>:<port>/<database>,其中<host>是Hologres服务器的主机名或IP地址,<port>是端口号(默认为5432),<database>是要连接的数据库名称。
tableName: 指定要写入的表名。
username和password: 分别指定连接Hologres所使用的用户名和密码。
sink.buffer-flush.max-rows: 指定每个批次中要刷新的最大行数。可以根据实际情况进行调整,以提高写入性能。
sink.buffer-flush.interval: 指定刷新缓冲区的时间间隔,以毫秒为单位。可以根据实际情况进行调整,以避免频繁刷新缓冲区。
sink.max-retries: 指定连接失败时重试的最大次数。可以根据实际情况进行调整,以避免过多的重试操作。
sink.batch-size: 指定每个批次中要写入的行数。可以根据实际情况进行调整,以提高写入性能。
sink.write-mode: 指定写入模式,可以是insert(插入)或upsert(更新)。根据实际需求选择适当的写入模式。
以上是一些常见的参数设置,具体使用过程中可能还需要根据具体情况进行调整和优化。
看错误是少了Flink的依赖包,你用的是哪个版本的Flink,java 代码包含了阿里云实时计算Flink版的商业版连接器依赖,IDEA 调试可能会遇到无法找到连接器有关类的运行错误。可以参考https://help.aliyun.com/zh/flink/developer-reference/run-or-debug-a-flink-deployment-that-includes-a-connector-in-an-on-premises-environment?spm=a2c4g.11186623.0.0.2bfbf438mDyfiq 操作看下 ,此回答整理自钉群“实时数仓Hologres交流群”
本技术圈将为大家分析有关阿里云产品Hologres的最新产品动态、技术解读等,也欢迎大家加入钉钉群--实时数仓Hologres交流群32314975


