
2.0.4重启了nacos出现这个问题,各位大佬有什么处理经验不?目前双写都是关闭,环境为3台阿里云的ECS部署的集群,nginx tcp做的vip 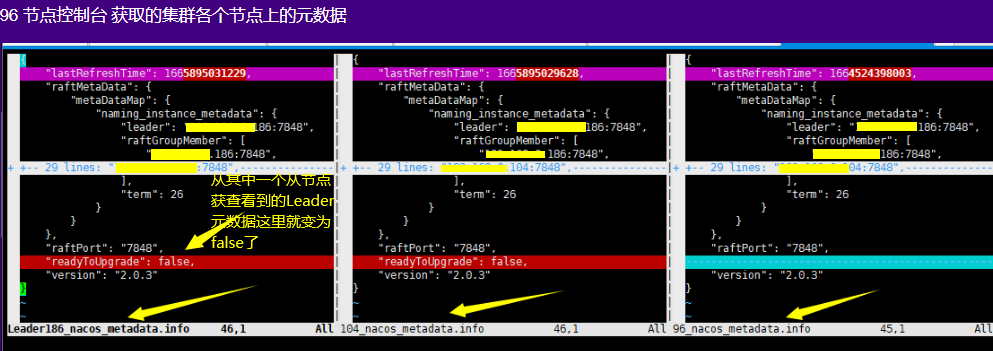

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,Nacos在重启后出现异常,并且当前环境为3台阿里云ECS部署的集群,使用Nginx TCP实现VIP(虚拟IP)负载均衡。以下是针对该问题的分析与解决方案:
Nacos重启后出现问题可能涉及以下几个方面: - Nacos服务配置问题:Nacos集群模式下,节点之间的通信和数据同步可能出现异常。 - Nginx TCP配置问题:Nginx作为负载均衡器,可能存在配置错误或未正确转发请求。 - 网络问题:阿里云ECS实例之间的网络连通性可能存在问题,导致Nacos节点间无法正常通信。 - 资源限制:ECS实例的内存、CPU等资源不足可能导致Nacos服务启动失败或运行异常。
登录到每台ECS实例,检查Nacos服务是否正常启动。
ps -ef | grep nacos
如果Nacos进程未启动,请尝试手动启动:
sh startup.sh -m cluster
确保以集群模式启动。
查看Nacos日志文件,定位具体错误信息。
/home/nacos/logs/。nacos.log和cluster.log,确认是否有节点通信失败或数据同步异常的记录。如果日志中提示内存不足,可以调整JVM参数。编辑conf/application.properties文件,增加以下内容:
JVM_XMS=2g
JVM_XMX=2g
确认Nginx是否正确配置了TCP负载均衡。编辑Nginx配置文件(通常位于/etc/nginx/nginx.conf或/etc/nginx/conf.d/目录下),确保包含类似以下内容:
stream {
upstream nacos_cluster {
server <ECS_IP_1>:8848;
server <ECS_IP_2>:8848;
server <ECS_IP_3>:8848;
}
server {
listen 8848;
proxy_pass nacos_cluster;
}
}
替换<ECS_IP_1>、<ECS_IP_2>、<ECS_IP_3>为实际的ECS私网IP地址。
重启Nginx服务以应用更改:
sudo systemctl restart nginx
使用netstat命令检查Nginx是否监听了8848端口:
netstat -anptu | grep 8848
在每台ECS实例上,使用ping命令测试与其他节点的连通性:
ping <ECS_IP_2>
ping <ECS_IP_3>
如果无法ping通,请检查安全组规则和VPC网络配置。
使用telnet命令测试Nacos服务端口(默认8848)是否可达:
telnet <ECS_IP_2> 8848
telnet <ECS_IP_3> 8848
如果网络不通,请检查阿里云安全组规则,确保允许8848端口的入站和出站流量。
使用top或free命令检查ECS实例的CPU和内存使用情况:
top
free -h
如果内存不足,可以参考知识库中的内存优化方法释放缓存。
如果发现内存占用过高,可以使用以下命令排查异常进程:
ps -eo pid,rss,pmem,pcpu,vsz,args --sort=rss
访问Nacos控制台,确认所有节点是否正常加入集群。
http://<VIP>:8848/nacos<VIP>为Nginx负载均衡的虚拟IP。在控制台中查看集群节点列表,确保所有节点状态为UP。
如果某个节点状态异常,可以尝试重新启动该节点的Nacos服务。
/home/nacos/data),以防止数据丢失。通过以上步骤,您可以逐步排查并解决Nacos重启后出现的问题。如果问题仍未解决,请提供更多日志信息以便进一步分析。
阿里云拥有国内全面的云原生产品技术以及大规模的云原生应用实践,通过全面容器化、核心技术互联网化、应用 Serverless 化三大范式,助力制造业企业高效上云,实现系统稳定、应用敏捷智能。拥抱云原生,让创新无处不在。
