
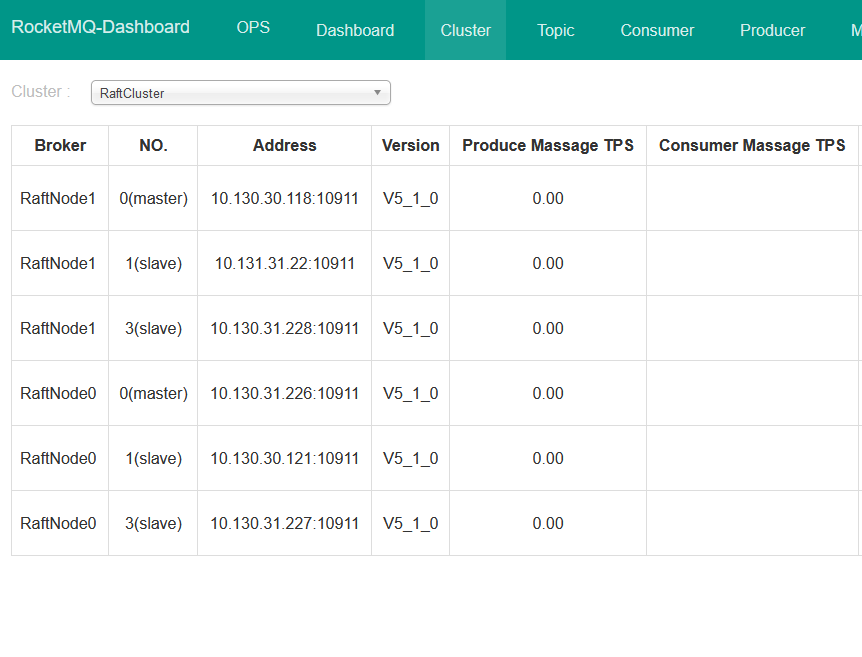
目前rocketmq版本是4.9。架构采用3+3 dledger模式,1个master下面有2个slave,然後有2组。消息是随机分配到其中1组处理。我们的云端是采用Red Hat OpenShift。我们遇到的问题是,当网络进行例行维护时,某个slave节点 採用drain驱逐节点(这个动作是机房人员日常维护),此时该个slave节点会重启。重启後,该组Topic的Perm权限就会由6变成4(只读),从Dashboard看,IP也有随着变动。此时如果有消息进来,就会报No route info of this topic: App01-topic See http://rocketmq.apache.org/docs/faq/ for further details. 此时需要手动进入rocketmq Dashboard对所有topic perm设置成6才能恢复正常。 请问有人知道这个问题原因是什麽吗? 以及如何解决这个问题,因为不知道网络什麽时候会维护,每次维护完都要手工重置perm为6这会影响正常服务。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这个问题可能是由于在网络例行维护时,drain驱逐节点的操作导致了slave节点的重启。重启后,该组Topic的权限可能会发生变化,主要是因为Broker的topic配置信息发生了变更,而namesrv的Topic的Queue信息并未得到相应的更新。
RocketMQ的权限控制(ACL)提供了Topic资源级别的用户访问控制。为了解决这个问题,您可以考虑以下步骤:
mqadmin updateTopicPerm -t topicA -p 6。mqadmin updateWhiteRemoteAddress命令来实现。涵盖 RocketMQ、Kafka、RabbitMQ、MQTT、轻量消息队列(原MNS) 的消息队列产品体系,全系列产品 Serverless 化。RocketMQ 中文社区:https://rocketmq-learning.com/

