
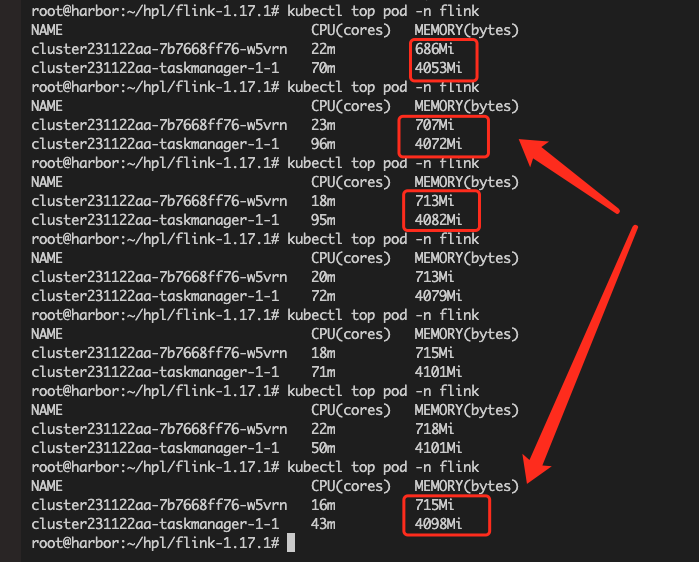
Flink CDC任务里有三个 全量+增量 的数据同步。现在有两个已经完成了全量同步(如上图蓝框),但是我查看任务所占的内存,并没有下降(如下图红框),这是为什么呀?是否正常,可否优化?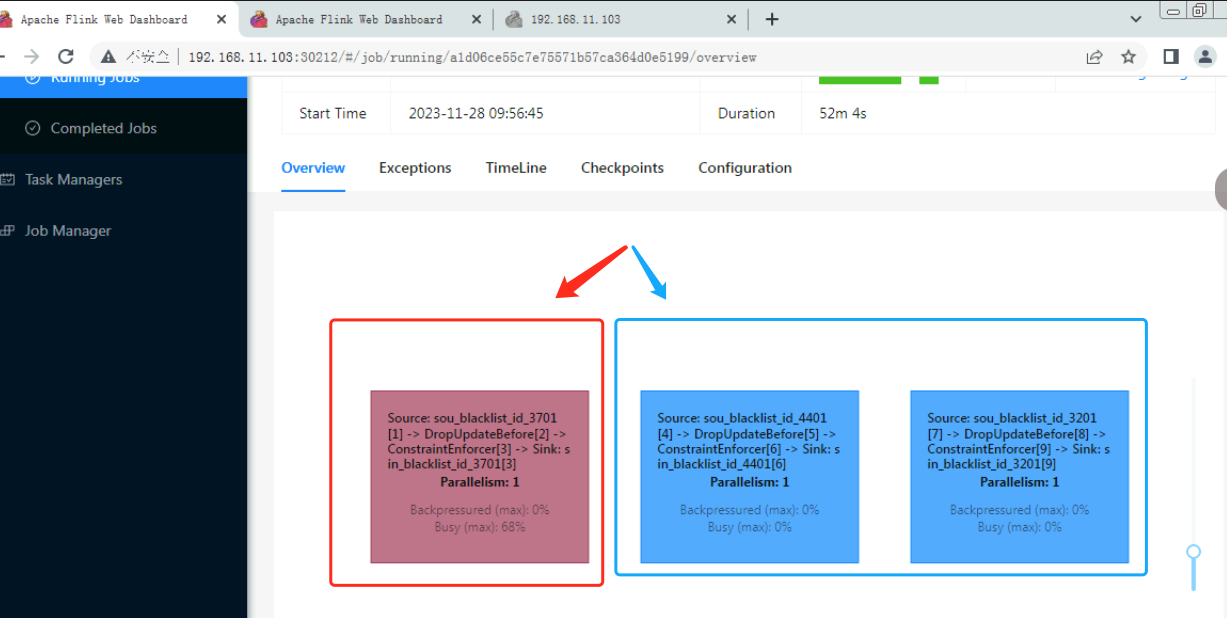
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink CDC任务中,全量和增量数据同步完成后,理论上内存占用应该有所下降。但您当前观察到的内存占用并未下降,可能的原因包括:
为了减小Flink CDC的内存占用并进一步优化任务,您可以考虑以下建议:
table.scan.startup.timeout = 60s。Flink CDC任务在完成全量同步后,所占用的内存并不会立即下降。这是因为Flink的内存管理机制是基于流处理的,它会缓存一部分数据以便进行实时计算。所以,即使你已经完成了全量同步,Flink仍然会保留一部分内存用于增量数据的处理和计算。
这种情况是正常的,不需要过于担心。但是,如果你发现任务所占用的内存过高,可能会影响到系统的性能,你可以尝试以下方法进行优化:
调整Flink的资源分配。你可以通过增加或减少任务的并行度来调整任务所占用的内存。
调整Flink的内存管理策略。你可以通过调整Flink的内存缓冲区大小、堆外内存等参数来优化内存使用。
优化数据处理逻辑。你可以通过优化数据处理的逻辑,减少不必要的数据复制和传输,从而降低内存使用。
如果可能,可以考虑使用更高效的数据同步工具,如Canal等,这些工具通常会有更好的内存管理和资源调度能力。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


