
阿里函数计算中这个问题怎么解决?
阿里函数计算中这个问题怎么解决?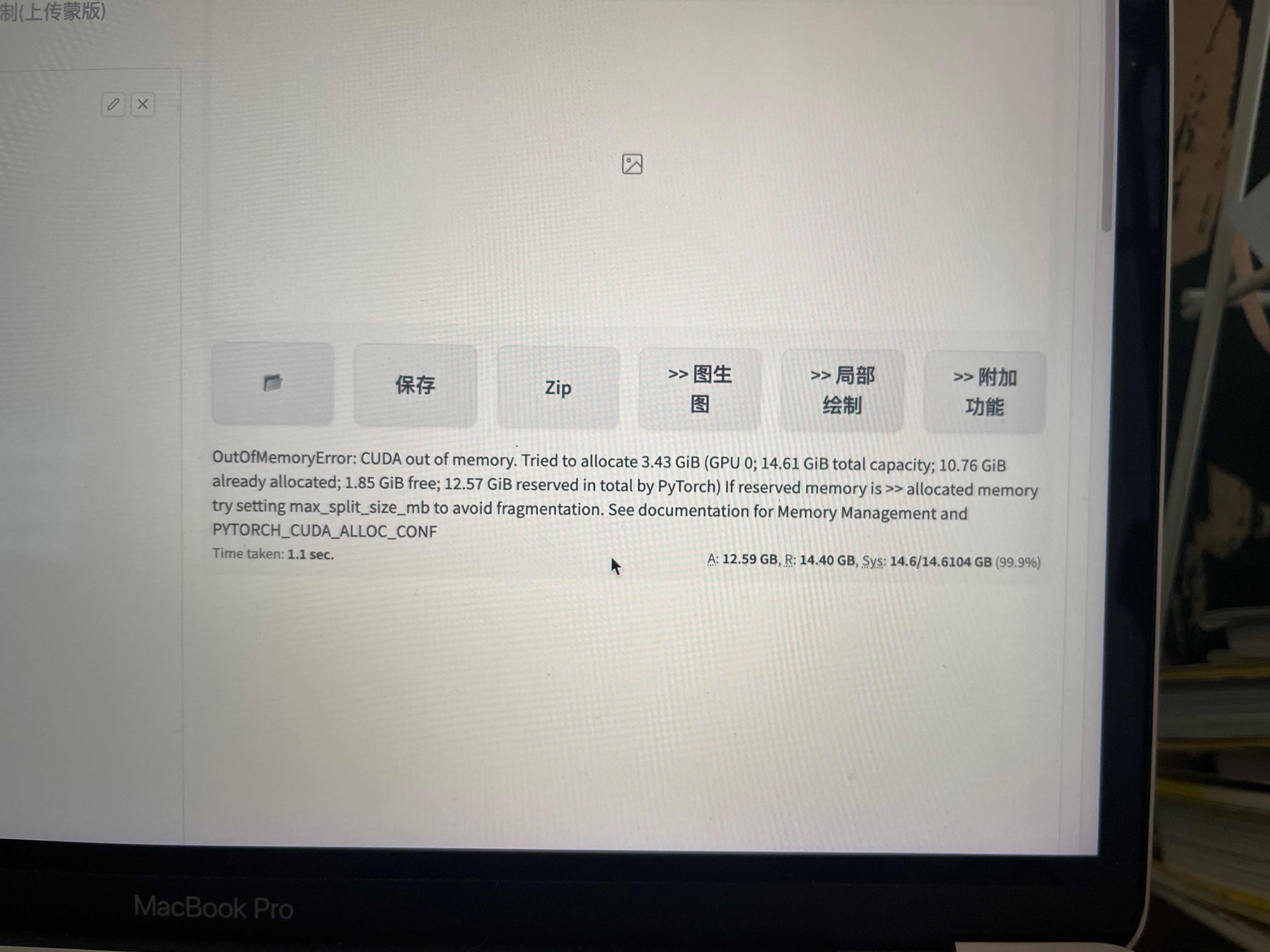
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
2
条回答
写回答
-
这个错误提示表明你的GPU内存不足,无法完成分配请求。这通常发生在处理大数据集或执行复杂计算时。以下是一些可能的解决方案:
减小模型大小:尝试使用较小的模型,以减少GPU内存需求。
调整batch size:减小每次训练的样本数量,以减少GPU内存需求。
清理GPU内存:在执行PyTorch程序之前,确保其他占用GPU内存的程序已关闭。你也可以使用
torch.cuda.empty_cache()来清理未被使用的缓存。使用多块GPU:如果你的机器有多块GPU,可以尝试将模型分配到多块GPU上运行,以减少单个GPU的负担。
调整CUDA内存配置:你可以尝试调整
PYTORCH_CUDA_ALLOC_CONF环境变量,例如设置max_split_size_mb以避免内存碎片化。具体设置方式可以参考PyTorch的官方文档。升级硬件:如果上述方法都无法解决问题,你可能需要升级你的硬件,例如增加更多的GPU内存。
2023-11-30 14:52:42赞同 1 展开评论 -
当遇到这个问题时,可以尝试一下这些建议,按代码更改的顺序递增:
减少“batch_size”
降低精度
按照错误说的做
清除缓存
修改模型/训练
2023-11-14 08:02:19赞同 1 展开评论

相关问答

相关文章
热门讨论
热门文章
展开全部
展开全部
还有其他疑问?
咨询AI助理