
大数据计算MaxCompute的正则不支持汉字吗?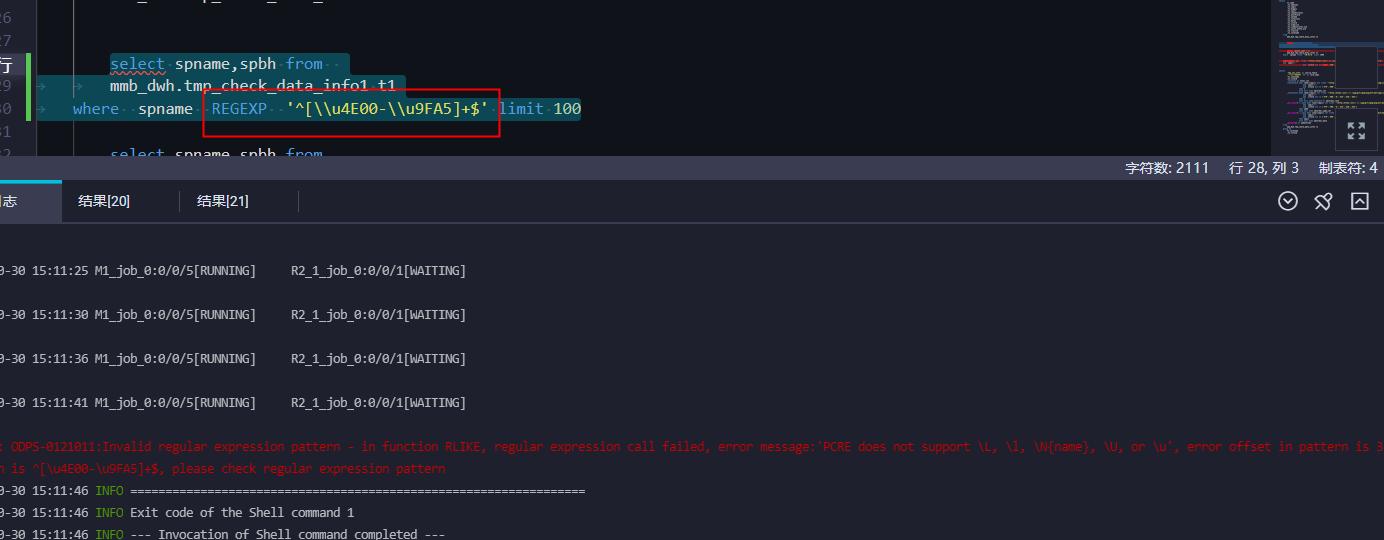
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
大数据计算MaxCompute的正则表达式支持汉字。MaxCompute支持使用正则表达式对中文字符进行匹配和处理。在MaxCompute中,你可以使用正则表达式来搜索、过滤、替换或解析包含汉字的数据。
需要注意的是,在编写正则表达式时,你需要正确地转义汉字字符,以确保正则表达式能够正确地匹配和处理中文字符。MaxCompute中使用的转义字符为反斜杠(\),你可以使用它来转义特殊字符和汉字字符。
例如,要匹配包含汉字的字符串"测试",你可以使用以下正则表达式:
\u4e2d\u6587\u6865\u7684\u8868\u793a
这个正则表达式中,\u4e2d表示汉字"中",\u6587表示汉字"文",\u6865表示汉字"测",\u7684表示汉字"试",\u8868表示汉字"的",\u793a表示汉字"正"。
总之,大数据计算MaxCompute的正则表达式支持汉字,但你需要注意正确地转义汉字字符以确保正则表达式的正确性。
实际上 MaxCompute 支持正则表达式中的汉字表示方法,但是需要注意的是,MaxCompute 的正则表达式规范与传统的正则表达式规范略有不同,而且 MaxCompute 不支持所有的 Unicode 字符,因此在使用正则表达式匹配汉字时需要特别注意。
在 MaxCompute 中,汉字可以使用中文字符组 [\u4e00-\u9fa5] 或者中文汉字字符组 [\x{4e00}-\x{9fa5}] 进行匹配,如下所示:
-- 使用中文字符组
SELECT REGEXP_EXTRACT('我爱中国','[\\u4e00-\\u9fa5]+')
-- 使用中文汉字字符组
SELECT REGEXP_EXTRACT('我爱中国','[\\x{4e00}-\\x{9fa5}]+')
MaxCompute支持使用正则表达式来匹配汉字。您可以在使用REGEXP函数时使用正则表达式来匹配包含汉字的字符串。以下是正则表达式中常用的汉字字符类:
汉字字符类描述
[\u4e00-\u9fa5]匹配中文简体字符
[\u3400-\u4dbf]匹配中文繁体字符
[\uac00-\ud7af]匹配韩文字母
[\u3040-\u309f]匹配日文假名
[\uff01-\uffef]匹配全角标点符号
[\u3002]匹配全角逗号
[\u3001]匹配全角分号
[\uff0c]匹配半角逗号
[\uff1b]匹配半角分号
支持的。
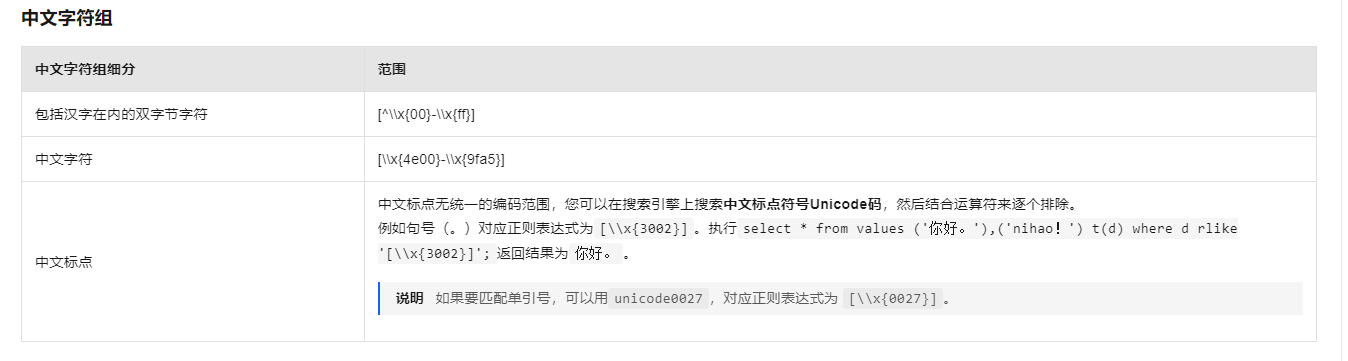
MaxCompute SQL中的正则表达式采用的是PCRE的规范,匹配时按字符进行。https://help.aliyun.com/zh/maxcompute/user-guide/regular-expressions?spm=a2c4g.11186623.0.i13
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


