
flink1.13默认的跑批shuffle模式是什么啊?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
目前Flink支持3中shuffle mode,分别是Block Shuffle Mode,Pipeline Shuffle Mode,Hybrid Shuffle Mode。
默认Block Shuffle Mode的实现是hash shuffle mode。hash shuffle模式是每个上游的任务会针对对应的每个下游任务持久化数据到单独的文件。当下游任务运行时,他们会从上游任务对应的分区中获取数据,下游任务通过网络读取文件并传输数据。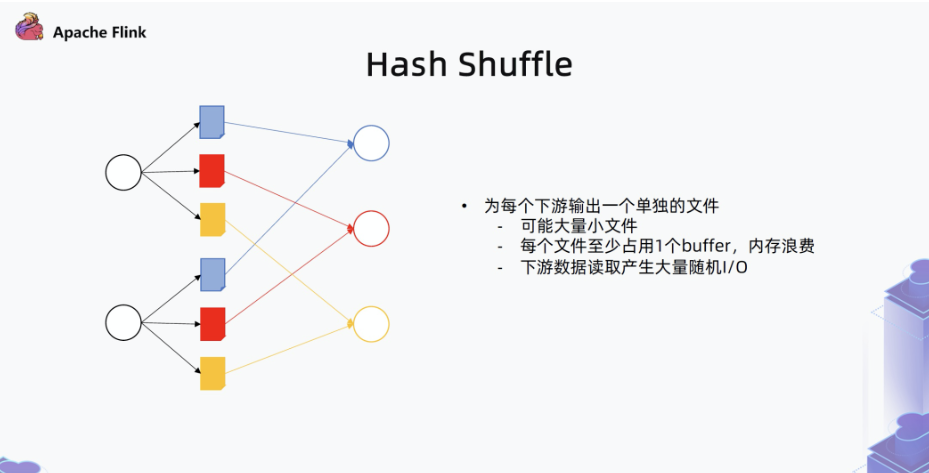
Flink 1.13的默认批处理数据交换模式是Blocking Shuffle。Blocking Shuffle会持久化所有的中间数据,只有当数据产出完全后才能被消费。此外,Flink还提供了另一种数据交换模式,即Hybrid Shuffle,它会更加智能地持久化数据,并允许在数据生产的同时进行消费。然而,这种模式目前仍处于实验阶段,并且存在一些已知的限制。
Apache Flink 1.13 默认的 Shuffle 模式是本地模式,这意味着所有 TaskManager 在同一节点上运行并使用本地文件系统进行 Shuffle 缓存。这种模式可以很好地工作于小型集群或单节点开发环境中。
Flink 也支持其他的 Shuffle 模式,包括分布式 Shuffle 和远程 Shuffle。这两种模式都是跨节点进行 Shuffle 缓存,其中分布式 Shuffle 使用本地文件系统,而远程 Shuffle 使用外部的分布式文件系统。
您可以根据自己的需求选择合适的 Shuffle 模式。如果您想要跨节点运行任务,可以选择分布式 Shuffle 或远程 Shuffle。具体的 Shuffle 模式的配置可以通过 ExecutionConfig.setShuffleMode() 方法来完成。例如,
final ExecutionConfig conf = new ExecutionConfig();
conf.setShuffleMode(ShuffleMode.BATCH);
Apache Flink是一个流行的流处理框架,它支持多种运行模式,包括批处理和流处理。在Flink 1.13版本中,默认的跑批shuffle模式取决于你使用的API。
如果你使用的是DataStream API,那么默认的shuffle模式是KeyedStream.groupBy().shuffle(),即基于键的分组和shuffle操作。在这个模式下,Flink会按照指定的键对数据进行分组,然后将每个分组内的数据进行随机排序,从而实现数据的分布均衡。
如果你使用的是DataSet API,那么默认的shuffle模式是GroupReduceOperator.shuffle(),即基于键的分组和reduce操作。在这个模式下,Flink会按照指定的键对数据进行分组,然后将每个分组内的数据进行reduce操作,从而实现数据的聚集和聚合。
需要注意的是,无论哪种shuffle模式,Flink都会自动处理数据的序列化和反序列化,以及网络传输等问题,从而简化用户的编程工作。
另外,如果你需要自定义shuffle模式,Flink还提供了多种选项可供选择,包括SortPartitioner、RangePartitioner和CustomPartitioner等。你可以根据自己的需求选择合适的partitioner,以便更好地控制数据的分布和排序。
总之,Flink 1.13版本中默认的跑批shuffle模式取决于你使用的API,但都可以通过自定义partitioner等方式进行定制和优化。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


