
在阿里函数计算中, Kafka 触发器【投递并发最大值】是什么?在 yaml 中如何配置?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云函数计算中,当使用 Kafka 触发器时,"投递并发最大值" 是指 Kafka 触发器在同一时间向函数计算实例推送消息的最大并发数。这个参数是为了限制同时处理的消息数量,以避免过度消耗资源或超出函数计算的并发限制。
"投递并发最大值" 允许你根据实际的处理能力和资源需求调整并发级别,这样可以确保函数计算实例在高峰时段不会被压垮。
在使用 Fun 工具部署函数计算时,你可以在 YAML 文件中为 Kafka 触发器配置这个参数。配置的方式如下:
Events:
- Type: Kafka
TriggerName: [YourTriggerName]
TriggerProperties:
Topic: [YourTopicName]
AuthMode: "sasl"
ConsumerGroup: [YourConsumerGroupName]
...
MaxFetchBytes: [YourMaxFetchBytes]
...
MaxConsumerCount: [YourDesiredMaxConcurrent]
Kafka触发器是Function Compute的一种触发器,它可以将Kafka队列中的消息传送给Function Compute进行处理。在Kafka触发器的配置中,有一个叫做“投递并发最大值”的选项,它指定了函数计算同时接收和处理的最大消息数。
当Kafka触发器接收到消息时,它会将消息发送到函数计算,如果并发处理的消息数量超过了指定的“投递并发最大值”,那么消息就会排队等候,直到有足够的资源来处理它们。
在YAML配置文件中,您可以在Kafka触发器的配置部分添加concurrency字段来设置投递并发最大值,如下所示:
kafka:
type: kafka
topicName: your-topic-name
bootstrapServers: your-bootstrap-servers
concurrency: 50 # 设置投递并发最大值为50
投递并发最大值是阿里函数计算中Kafka触发器的一个配置项,它定义了同时投递到函数计算的请求的最大数量。这个参数的设定对于处理大流量的数据流至关重要,因为它可以有效控制并发度,防止因瞬间大量的数据流入而导致系统压力过大。在具体的YAML配置文件中,您可以参照以下示例进行设置:
triggers:
- name: kafkaTrigger
type: kafka
parameters:
topic: your_topic
partition: your_partition
maxDeliveryAttempts: 3
consumerGroup: your_consumerGroup
parallelism: 100 # 投递并发最大值
在这个示例中,parallelism字段就是用来配置投递并发最大值的。请将其中的your_topic、your_partition和your_consumerGroup替换为您实际的值。
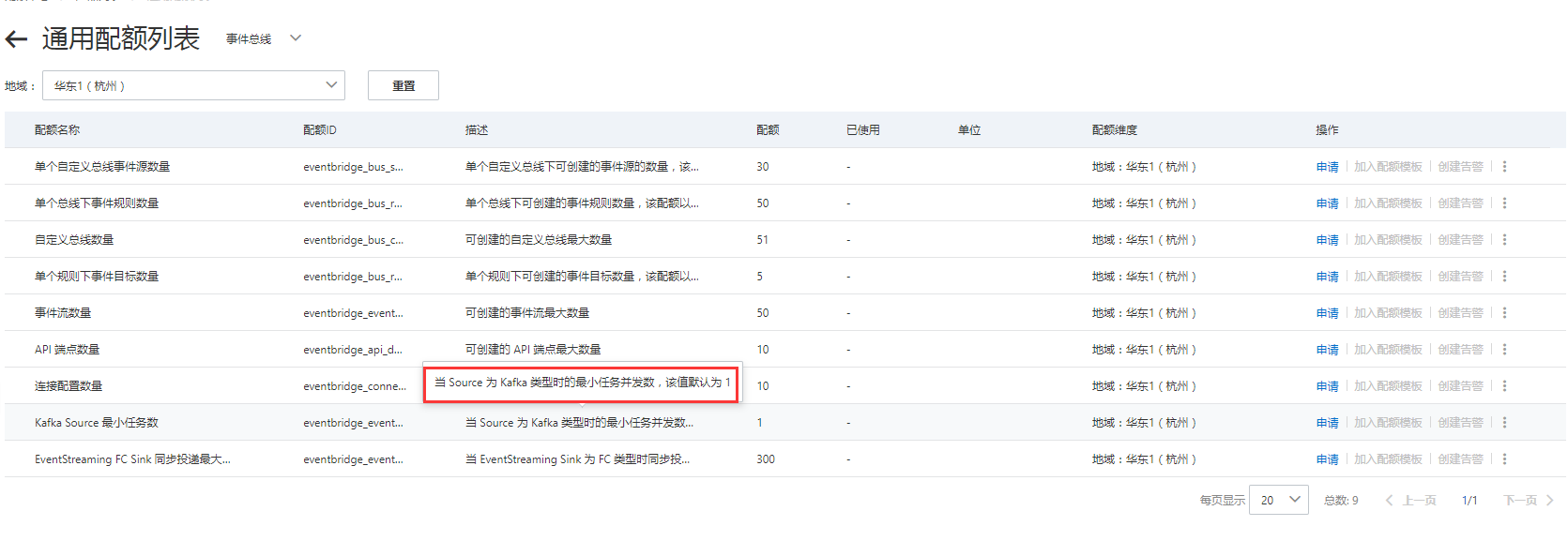
投递并发最大值是Kafka消息投递到函数计算的并发最大值,取值范围为1~300。该参数仅对同步调用生效。如果需要更高的并发,请进入EventBridge配额中心申请配额名称为EventStreaming FC Sink 同步投递最大并发数的配额。
https://quotas.console.aliyun.com/products/eventbridge/quotas?regionId=cn-hangzhou

Kafka消息投递到函数计算的并发最大值,取值范围为1~300。该参数仅对同步调用生效。如果需要更高的并发,请进入EventBridge配额中心申请配额名称为EventStreaming FC Sink 同步投递最大并发数的配额。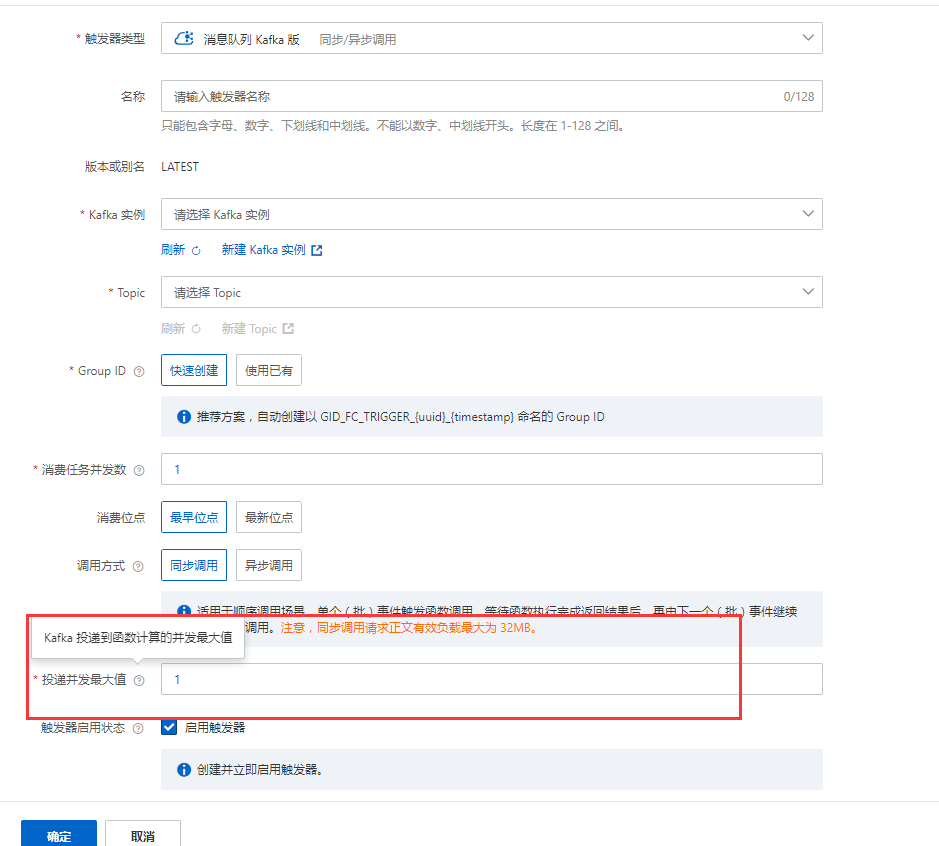
——参考来源于阿里云官方文档。
Kafka触发器的投递并发最大值是指Kafka消息投递到函数计算的并发最大值,其取值范围为1~300。这个参数只对同步调用生效。如果你需要更高的并发,可以通过进入EventBridge配额中心来申请对应的配额。


