
flink1.15.2,cdc2.4.1
checkpoint存在hdfs上。
业务场景:我们有多张mysql表。历史数据大概有2.1亿条,表中有多个字段是text类型,单条record消息稍大些。
flinkcdc写kafka,initial消费,6个并行度,TM8GB,JM8GB。
任务运行一段时间后,flink tm报错:
job leader lost leadership。
然后flink框架会基于上一个成功的状态恢复这个tm。但是恢复失败。
失败的具体表现是:
1、在任务恢复且未触发checkpoint的时候,从session页面看source的subtasks,对应的task并不真正干活;
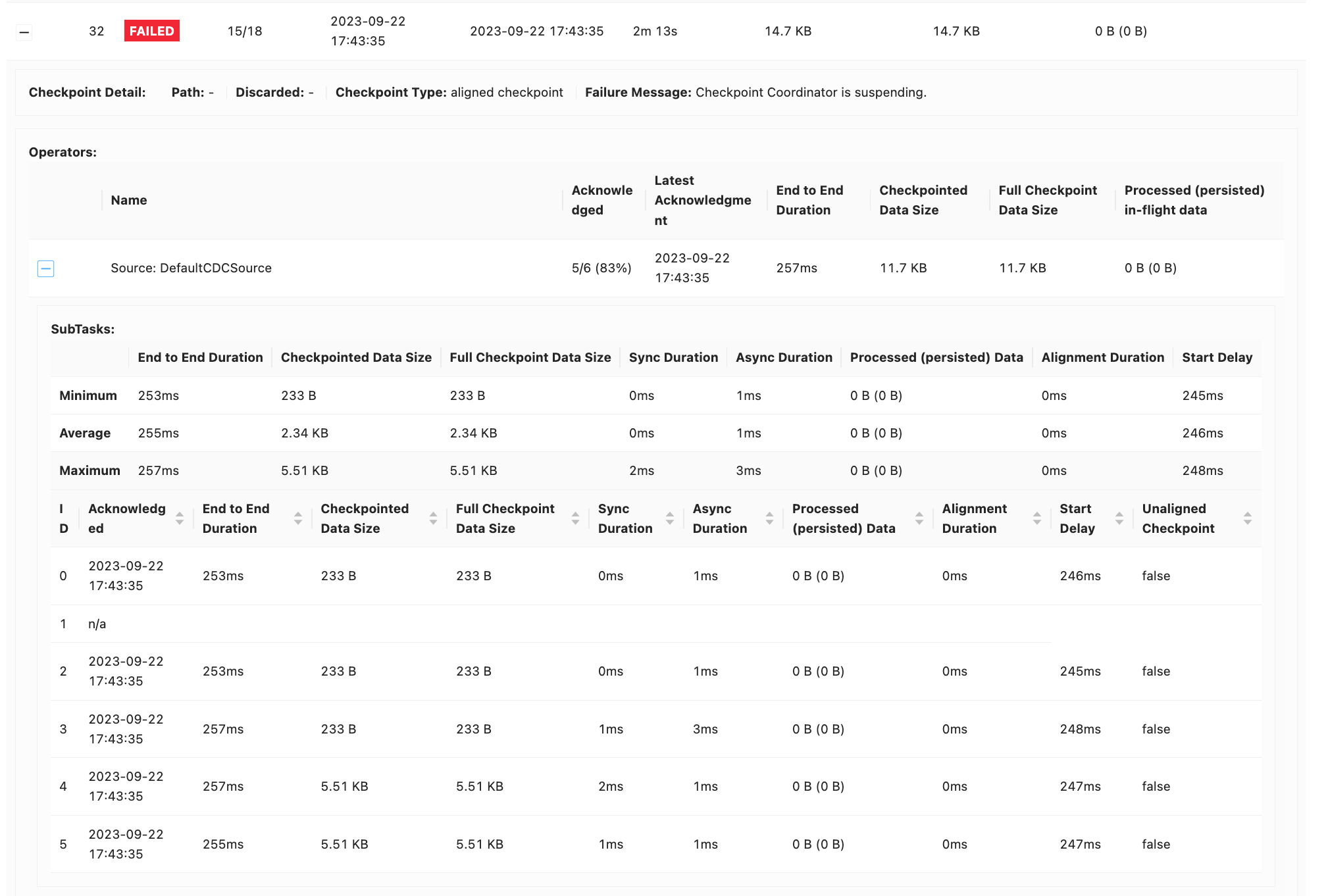
2、触发checkpoint时超时失败?如果人为干预任务,基于上一个成功的checkpoint恢复,也是一样的问题。
但是,我如果基于上上个成功的checkpoint恢复,就没有问题。
现在怀疑:在出现lost leadership这个异常之前的状态是不可用的。
请问,在flink框架层面是否有验证状态是否写成功的机制呢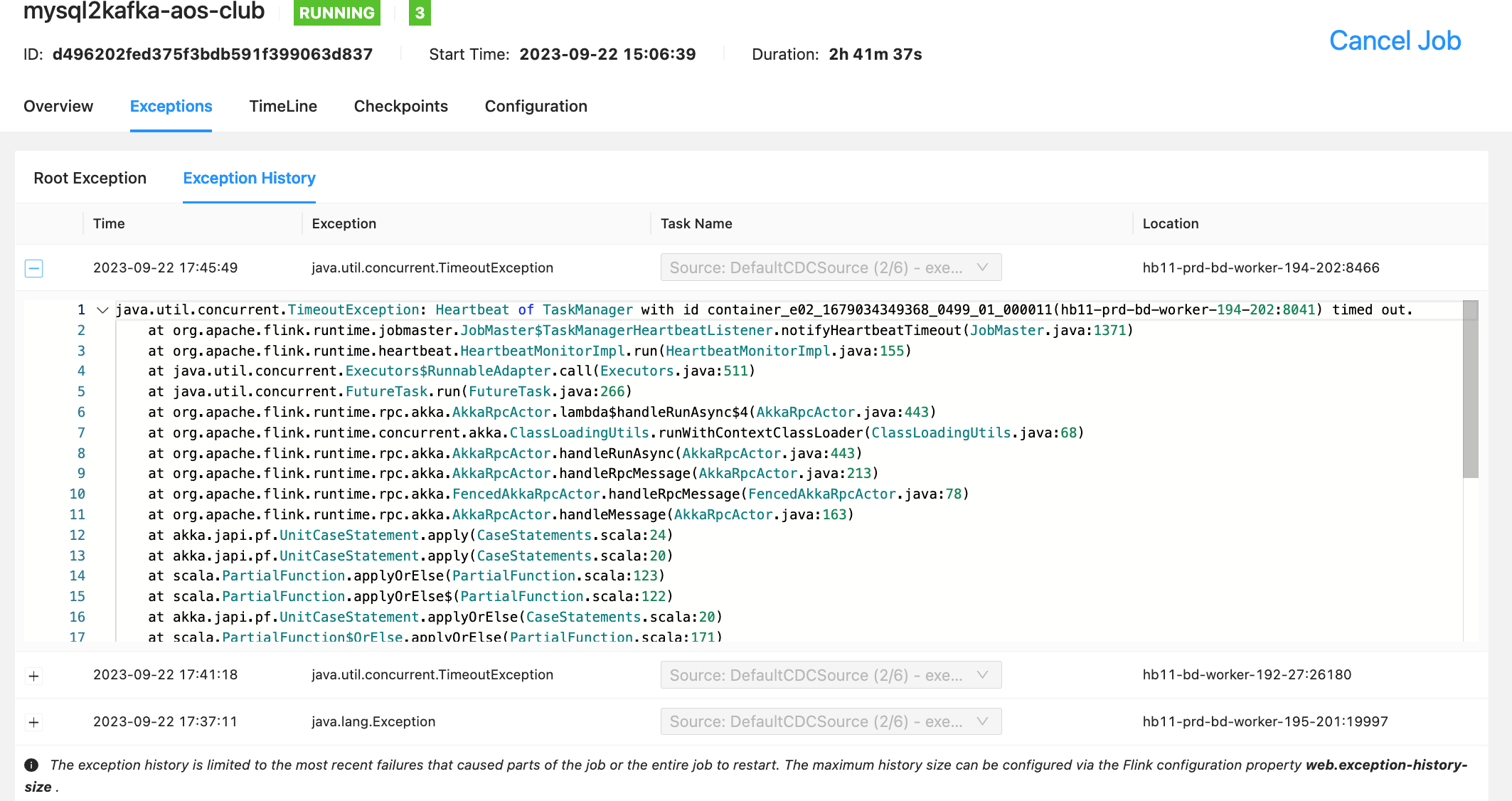
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink 1.15.2 和 CDC 2.4.1 的 checkpoint 可以存在 HDFS 上。但是,如果使用了 CDC 2.4.1 的新加表功能,那么 checkpoint 可能不会写入 HDFS。这是因为 CDC 2.4.1 的新加表功能会在启动的时候创建一个新的 Flink Job,而这个 Job 的 checkpoint 默认会存在本地磁盘上。
要解决这个问题,可以将 CDC 2.4.1 的新加表功能的 checkpoint 目录设置为 HDFS 上的一个目录。可以通过以下方式设置 checkpoint 目录:
checkpoint.dir: hdfs://:/flink/checkpoints
另外,如果使用了 CDC 2.4.1 的新加表功能,那么 checkpoint 文件的大小可能会比较大。这是因为 CDC 2.4.1 会将整个 Kafka 分区的数据写入 checkpoint 文件中。如果 Kafka 分区的数据量比较大,那么 checkpoint 文件的大小也会比较大。
要解决这个问题,可以尝试以下方法:
减少 Kafka 分区的数据量。
使用更加高效的 checkpoint 算法。
使用更快的网络连接。
使用更大的磁盘空间。
如果以上方法都不能解决问题,可以尝试联系 Flink 的社区支持寻求帮助。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


