
DataWorks基本使用配置全局数据流是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
配置全局数据流的详情请参见全局数据流。配置组件属性 组件属性配置面板主要负责可视化的方式配置组件属性。 根据组件的属性配置规则,组件属性配置面板将会生成一个可视化表单,让您输入组件的属性配置。在组件属性配置表单中更改组件属性后,可视化操作区域将会根据接收到的组件属性,进行重新渲染。您可以实时查看组件不同属性的渲染结果。配置组件样式 组件样式面板主要负责组件样式的相关设置。 组件样式配置面板将会生成一个通用的样式配置可视化页面,您可以基于该面板定制组件基本的外观样式,包括布局、文字、背景、边框、效果等常用样式配置。 在组件样式配置面板中添加、修改组件样式,可视化搭建系统将会收集所有的样式设置到组件上,可视化操作区域将会根据新的样式设置重新渲染对应组件,您可以实时查看配置后的组件效果。配置组件联动高级 组件联动高级设置面板主要负责组件之间的联动设置。单击可视化操作区域中的某一个组件,选中高级面板。高级设置面板中,将会在左侧列出当前选中组件对应的组件属性,单击右侧的放大镜按钮选择需要关联的另一个组件。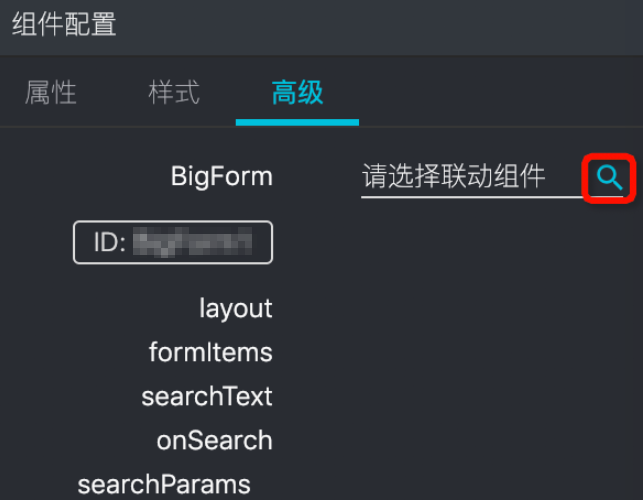
选中需要关联的另一个组件后,高级设置面板右侧将会出现对应的组件属性。
单击左侧属性列表中的某一个属性,连线至右侧属性列表中的另一个属性。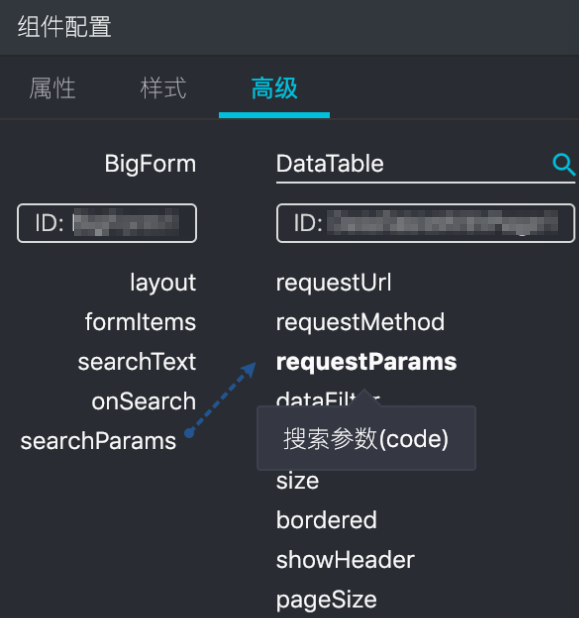
该操作将会实现两个组件之间的属性联动,左侧组件的searchParams参数变更将会及时传递到右侧组件的requestParams参数,从而实现两个组件基于属性之间的联动配置。
https://help.aliyun.com/document_detail/88117.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在DataWorks的基本使用配置中,"全局数据流"是作为一个核心功能可以帮助用户实现数据传输和集成的机制。它提供了一种灵活、可视化的方式来定义数据的输入、输出和转换规则,以实现数据在不同任务或节点之间的流动。
下面是配置全局数据流的基本步骤:
创建数据源表:在DataWorks中,首先需要创建数据源表,例如数据库表、文件、OSS对象等。
定义数据源节点:打开数据开发项目,进入数据开发页面,选择“数据开发” > “数据源”,然后点击“新建数据源”。在这里,你可以选择和配置适当的数据源类型,并填写连接信息,以便DataWorks能够访问数据源。
创建数据转换节点:在数据开发页面,选择“数据开发” > “数据转换”。通过拖拽和连接节点,可以实现数据的转换和清洗操作。例如,你可以使用SQL节点执行数据过滤、聚合、连接等操作。
配置全局数据流:在数据转换节点之间,可以通过右键单击节点并选择“配置数据流”来配置数据的传递关系。这样,你可以将输出数据流从一个节点连接到另一个节点的输入。
设置调度周期:在数据流配置完成后,你可以设置数据流的调度周期,即数据流的运行频率。根据需要,可以选择调度频率(如每天、每小时、每分钟等)和调度时刻。
保存和发布数据开发任务:在配置完成后,记得保存和发布数据开发任务,以便DataWorks能够调度和执行数据流。
通过配置全局数据流,你可以实现数据在不同节点之间的传递、转换和集成。这有助于构建复杂的数据处理管道,并且具备可维护性和可扩展性。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


