
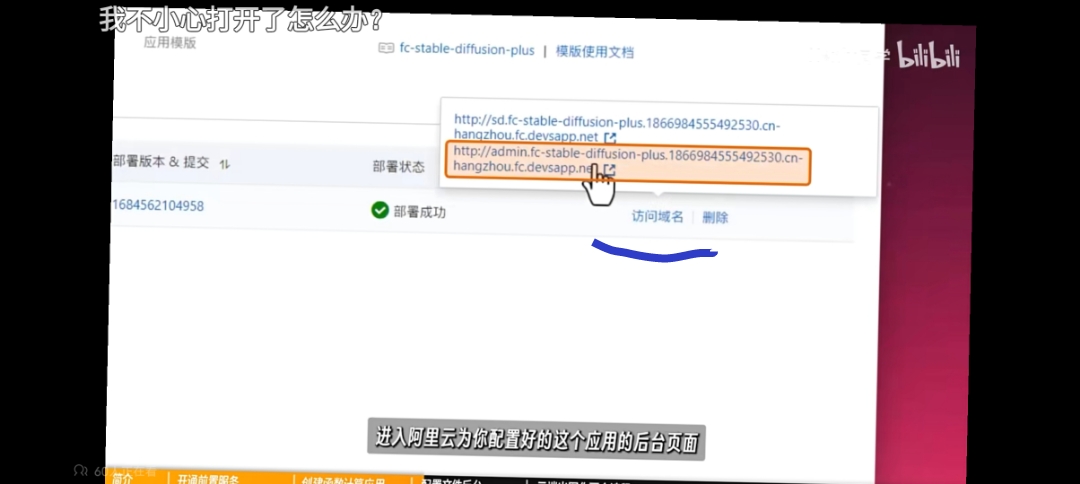
函数计算,麻烦问一下,在FC应用中,我是要找这个“访问域名”,然后再打开桔色的这个网址
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
【 函数计算,麻烦问一下,在FC应用中,我是要找这个“访问域名”,然后再打开桔色的这个网址
】
然后,在函数计算的代码中,你可以使用方法来获取指定 URL 的内容。例如,获取“访问域名”对应的网页内容: 然后,在函数计算的代码中,你可以使用方法来获取指定 URL 的内容。例如,获取“访问域名”对应的网页内容: 然后,在函数计算的代码中,你可以使用方法来获取指定 URL 的内容。例如,获取“访问域名”对应的网页内容: 获取到网页内容后,你可以使用Python的正则表达式库(如)来解析网页,提取所需的信息。例如,提取网址中的域名: 然后,在函数计算的代码中,你可以使用方法来获取指定 URL 的内容。例如,获取“访问域名”对应的网页内容: 获取到网页内容后,你可以使用Python的正则表达式库(如)来解析网页,提取所需的信息。例如,提取网址中的域名: 然后,在函数计算的代码中,你可以使用方法来获取指定 URL 的内容。例如,获取“访问域名”对应的网页内容: 获取到网页内容后,你可以使用Python的正则表达式库(如)来解析网页,提取所需的信息。例如,提取网址中的域名:
在函数计算中,要实现这个功能,你可以使用Python的requests库来获取指定URL的内容。首先,你需要安装requests库,可以使用以下命令安装:
pip install requests
复制复制
然后,在函数计算的代码中,你可以使用requests.get()方法来获取指定 URL 的内容。例如,获取“访问域名”对应的网页内容:
import requests
url = "访问域名" # 请替换为实际的域名
response = requests.get(url)
if response.status_code == 200:
content = response.text
# 在这里处理获取到的网页内容
else:
print(f"请求失败,状态码:{response.status_code}")
复制复制
获取到网页内容后,你可以使用Python的正则表达式库(如re)来解析网页,提取所需的信息。例如,提取网址中的域名:
import re
domain = re.search(r'http.?://(.?)', content).group(1)
print("域名:", domain)
复制复制
这样,您就可以获取访问域名以及桔色网址的域名。请注意,这里的代码仅作为示例,您可能需要根据实际的网页结构调整正则表达式。
页面有调整,点左边的应用名进到详情也可以看到域名。
参考:https://developer.aliyun.com/adc/scenario/b2cc0e1c3a6244e0bd9fc0f37acd5a0e?spm=a2c6h.13858375.0.0.110365be6XOyAS
此答案来自钉钉群“阿里函数计算官网客户"

