
DataWorks中Local 方式使用 Spark 配置好jar包,依旧报The value of spark.sql.catalogImplementation should be one of hive, in-memory, but was odps?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
当在DataWorks中使用Local方式使用Spark时,配置好了Jar包但仍然报错"The value ?",这可能是由于以下原因之一:
Jar包路径配置错误:请确保在DataWorks中正确配置了Spark任务的Jar包路径。检查路径是否正确,并确认Jar包是否存在于指定路径中。
Spark任务代码中的参数问题:在Spark任务代码中,出现"The value ?"的错误可能是由于未正确设置参数导致的。检查Spark任务代码中的参数设置,确保参数的正确性和完整性。
数据输入问题:如果Spark任务需要读取输入数据,检查数据输入的路径和格式是否正确。确保数据在指定路径下可用,并符合Spark任务的输入要求。
依赖库冲突:如果使用的Jar包中包含与DataWorks环境中的依赖库冲突的类或方法,可能会导致"The value ?"的错误。解决方法可能涉及排除冲突的依赖项或调整Jar包中的依赖库版本。
其他错误:如果以上步骤都已确认正确,还是无法解决问题,建议检查其他相关配置和日志信息,或联系DataWorks的技术支持团队,提供更详细的错误信息和配置情况,以便他们能够帮助进一步排查和解决问题。
在DataWorks中,使用Local方式配置Spark时,如果报错提示"spark.sql.catalogImplementation"的值应该是"hive"、"in-memory"之一,但实际值为"odps",这通常是由于配置文件中存在冲突或错误的设置导致的。
要解决这个问题,请按照以下步骤进行操作:
确认配置文件:在DataWorks中,查看您的Spark配置文件,通常为spark-defaults.conf。确保没有其他地方对"spark.sql.catalogImplementation"参数进行了重复的设置。
检查依赖关系:确认您的项目中是否有其他地方使用了ODPS(MaxCompute)相关的依赖项或设置,例如pom.xml、DataWorks中的数据源连接等。当存在与ODPS相关的依赖时,可能会干扰Spark的配置。
修改配置:将"spark.sql.catalogImplementation"参数设置为正确的值(如"hive"),并确保在配置文件中没有其他地方修改了此参数。可以尝试重新启动Spark服务以使新的配置生效。
使用DataWorks提供的资源管理功能:如果您需要在DataWorks中使用Spark,建议使用DataWorks的集群资源管理功能,而不是直接在本地配置Spark。通过此方式,DataWorks会自动处理Spark的配置,并保证与其他组件的兼容性。
在DataStudio(数据开发)页面,鼠标悬停至
图标,单击MaxCompute > ODPS Spark。您也可以打开相应的业务流程,右键单击MaxCompute,选择新建 > ODPS Spark。在新建节点对话框中,输入节点名称,并选择目标文件夹。说明 节点名称必须是大小写字母、中文、数字、下划线(_)和小数点(.),且不能超过128个字符。单击提交。在ODPS Spark编辑页面,配置各项参数。ODPS Spark的详情请参见概述。ODPS Spark节点支持两种spark版本和语言。选择不同的语言,会显示相应不同的配置,您可以根据界面提示进行配置:选择语言为Java/Scala,配置如下。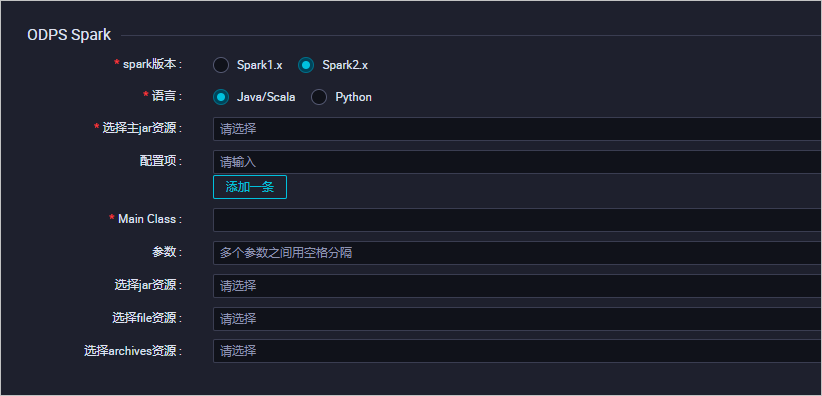
参数 描述
spark版本 包括Spark1.x和Spark2.x两个版本。
语言 此处选择Java/Scala。
选择主jar资源 从下拉列表中选择您已上传的JAR资源。
配置项 单击添加一条,即可配置key和value。
Main Class 选择类名称。
参数 添加参数,多个参数之间用空格分隔。支持使用调度参数,调度参数使用方式请参考文档调度参数。
选择jar资源 ODPS Spark节点根据上传的文件类型自动过滤,选择下拉框中显示的您已上传的JAR资源。
选择file资源 ODPS Spark节点根据上传的文件类型自动过滤,选择下拉框中显示的您已上传的File资源。
选择archives资源 ODPS Spark节点根据上传的文件类型自动过滤,选择下拉框中显示的您已上传的Archives资源,仅展示压缩类型的资源。选择语言为Python,配置如下。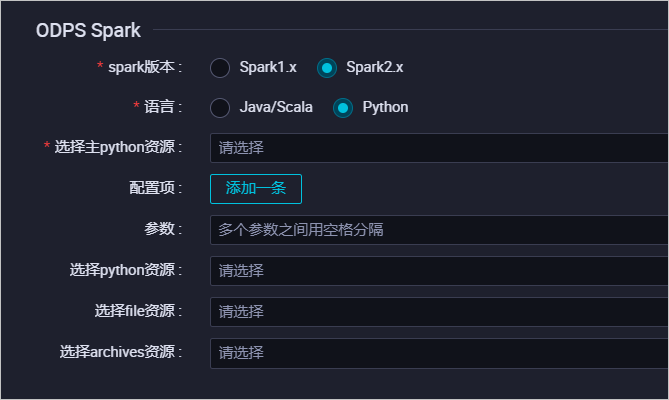
参数 描述
spark版本 包括Spark1.x和Spark2.x两个版本。
语言 此处选择Python。
选
https://help.aliyun.com/document_detail/201516.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


