
DataWorks中A任务(虚拟节点)+ B任务(天级作业,但是我只需要他前天的数据即可)==>产出C,那么我C节点的依赖,可以设置成上一周期,然后选择B吗?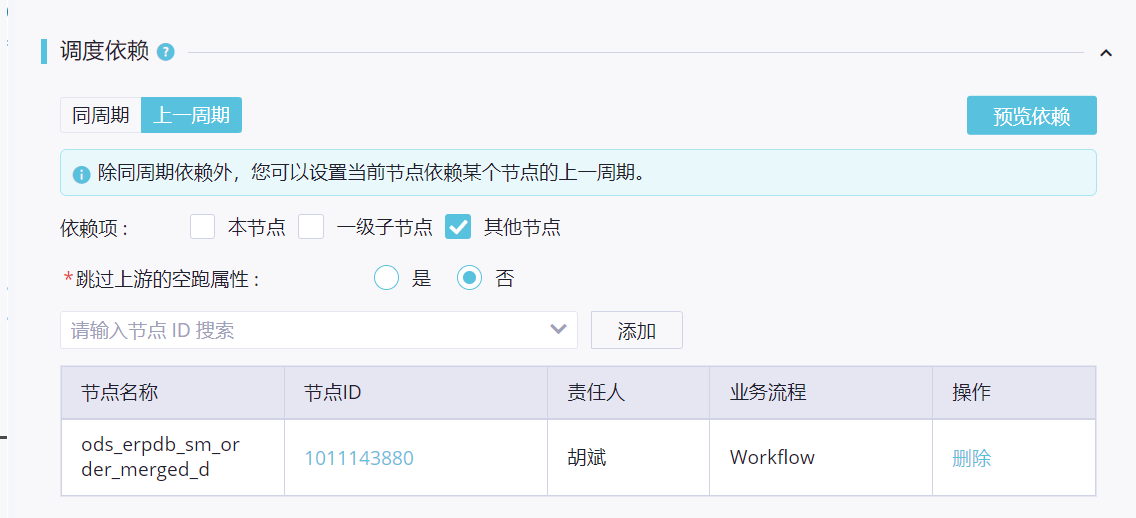
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,可以通过设置C节点的依赖方式为"上一周期",然后选择B节点作为依赖,来实现C节点依赖于A任务(虚拟节点)+ B任务的逻辑。
下面是一般的操作步骤:
在DataWorks的工作流编辑页面,将A任务(虚拟节点)和B任务连接起来,形成一个任务流。
在工作流中找到C节点,右键点击节点,选择"属性"。
在属性设置对话框中,找到"依赖"选项。
在依赖设置中,选择"上一周期"作为依赖方式。
在"上一周期"的依赖列表中,选择B任务作为依赖节点。
确认设置,保存工作流。
通过以上设置,C节点将会在每个周期依赖上一个周期的B任务的执行结果。这样,当A任务(虚拟节点)和B任务都完成后,C节点会在下一个周期开始时开始执行。
在DataWorks中,如果你想要设置C节点的依赖为上一周期的B任务节点,可以按照以下步骤进行操作:
创建A任务节点和B任务节点:首先,在数据开发页面创建A任务节点(虚拟节点)和B任务节点(天级作业)。确保这两个节点已经配置和调度正常。
创建C任务节点:在数据开发页面创建C任务节点,并在节点配置中设置合适的任务类型(例如SQL节点)。确保C任务节点的输出结果可以作为最终的产出数据。
设置C节点的依赖:在C任务节点的依赖设置中,选择上一周期选项,并从下拉列表中选择B任务节点。这样,C任务节点将会在每个周期开始时,依赖上一周期的B任务节点的输出数据。
需要注意的是,上一周期的定义方式有两种:
根据你的描述,你希望C节点依赖的是B任务节点前一天的数据,因此你可以选择自定义周期,并设置合适的时间范围来匹配前一天的数据。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


