
DataWorks如何使用oss读取csv文件至云端?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,您可以使用OSS Reader组件来读取OSS中的CSV文件,并将数据写入到ODPS表中。具体操作步骤如下:
创建OSS连接:在DataWorks控制台中,选择“数据开发”>“数据源”,然后单击“新建数据源”按钮,在弹出的对话框中选择“OSS”,然后填写相应的连接信息(例如AccessKey、SecretKey、Endpoint等)。
创建ODPS表:在DataWorks控制台中,选择“数据开发”>“数据开发空间”,然后单击“新建表”按钮,在弹出的对话框中填写表名和字段信息,然后单击“提交”按钮。
创建数据同步任务:在DataWorks控制台中,选择“数据集成”>“数据同步”,然后单击“新建同步任务”按钮,在弹出的对话框中填写任务名称和描述信息,然后单击“下一步”按钮。
配置同步任务:在创建同步任务页面中,选择“OSS Reader”组件,然后配置相应的参数(例如OSS连接、OSS文件路径、CSV文件格式等),然后将数据写入到ODPS表中,选择“ODPS Writer”组件,然后配置相应的参数(例如ODPS连接、ODPS表名、写入模式等)。
要使用DataWorks将CSV文件从OSS读取到云端,您可以按照以下步骤操作:
当任务运行时,DataWorks将会从OSS读取CSV文件并将其加载到ODPS(MaxCompute)中进行进一步的数据处理和分析。这样,您就可以在云端使用DataWorks对CSV数据进行操作和管理了。
请注意,上述步骤是一个基本的示例流程。实际操作可能因您的具体需求和环境而有所不同。确保在操作前详细阅读DataWorks文档,并根据实际情况进行相应的配置和调整。
要在DataWorks中使用OSS读取CSV文件至云端,您可以按照以下步骤操作:
首先,确保您已经将CSV文件上传到OSS中。您可以使用阿里云的OSS管理控制台或者通过OSS的API将CSV文件上传到OSS中。 打开DataWorks,在"数据源"页面中创建一个新的数据源。在创建数据源的过程中,选择"OSS数据源"作为数据源类型。 在配置OSS数据源的过程中,输入OSS的访问密钥、访问地址、存储空间等信息,以便DataWorks可以连接到OSS并访问其中的CSV文件。 配置完OSS数据源后,在DataWorks中选择要使用CSV文件的任务或节点。在任务或节点的配置页面中,选择"数据源引用",并选择您刚刚创建的OSS数据源。 在任务或节点的配置页面中,找到"数据表定义"字段,选择"OSS表",然后输入CSV文件的路径和列分隔符(如逗号)。 根据需要配置其他选项,例如文件编码、字段类型、字段长度等。 配置完任务或节点后,保存并提交任务。DataWorks将自动从OSS中读取CSV文件,并将其转换为数据表,以便后续的数据处理任务可以使用。 通过以上步骤,您可以将OSS中的CSV文件读取至云端,并使用DataWorks进行数据处理和分析。
使用OSS读取CSV文件时,需要配置读取的文件名(Object前缀)。通常IoT会不停生成数据并存储为CSV文件,如果您手动配置同步任务以读取IoT数据至云端,会较为复杂且不易实现。下文将为您介绍每5分钟生成一份CSV文件的情况下,如何自动同步数据至云端(MaxCompute)。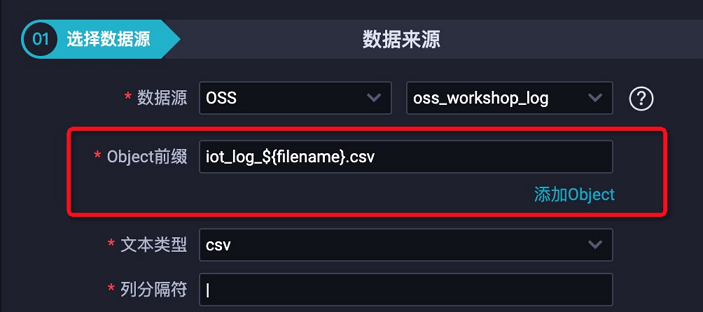 该解决方案需要注意的问题如下:OSS上的文件需要按时周期性生成。 DataWorks具备按照定时时间进行周期调度的特点,您可以设置DataWorks同步任务的调度周期为OSS生成文件的周期。例如,OSS上的文件每15分钟生成一份,设置DataWorks同步任务的调度周期为每15分钟调度一次。生成的文件名需要使用时间戳来命名。OSS同步任务在读取文件时,需要使用时间戳对文件进行命名。DataWorks通过参数变量来动态生成文件名称,以确保和OSS上的文件名称保持一致。说明 推荐您使用yyyymmddhhmm等时间戳作为文件名的一部分,例如iot_log_201911062315.csv。登录DataWorks控制台,单击相应工作空间后的进入数据集成。新增OSS数据源和MaxCompute数据源,详情请参见配置OSS数据源和配置MaxCompute数据源。单击当前页面左上角的图标,选择全部产品 > 数据开发,新建业务流程,详情请参见新建业务流程。新建离线同步节点,详情请参见新建离线同步节点。在离线同步节点的编辑页面,选择数据来源,并使用参数变量作为文件名。
该解决方案需要注意的问题如下:OSS上的文件需要按时周期性生成。 DataWorks具备按照定时时间进行周期调度的特点,您可以设置DataWorks同步任务的调度周期为OSS生成文件的周期。例如,OSS上的文件每15分钟生成一份,设置DataWorks同步任务的调度周期为每15分钟调度一次。生成的文件名需要使用时间戳来命名。OSS同步任务在读取文件时,需要使用时间戳对文件进行命名。DataWorks通过参数变量来动态生成文件名称,以确保和OSS上的文件名称保持一致。说明 推荐您使用yyyymmddhhmm等时间戳作为文件名的一部分,例如iot_log_201911062315.csv。登录DataWorks控制台,单击相应工作空间后的进入数据集成。新增OSS数据源和MaxCompute数据源,详情请参见配置OSS数据源和配置MaxCompute数据源。单击当前页面左上角的图标,选择全部产品 > 数据开发,新建业务流程,详情请参见新建业务流程。新建离线同步节点,详情请参见新建离线同步节点。在离线同步节点的编辑页面,选择数据来源,并使用参数变量作为文件名。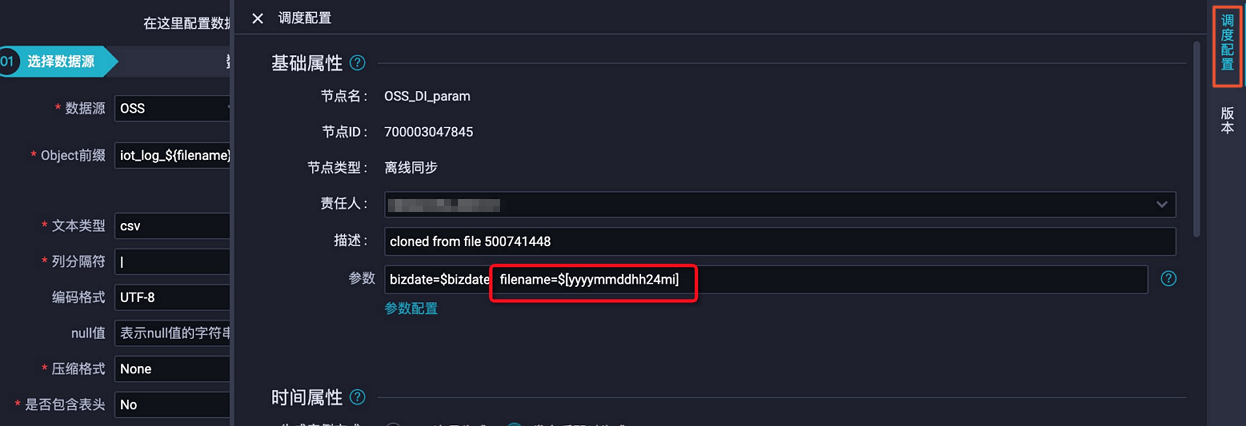 如上图所示,将文件名的时间戳部分作为变量,使用unknown格式的参数代替。您可以自定义参数名称,示例为filename。单击右侧的调度配置,在基础属性 > 参数中为上述自定义参数赋值为filename=$[yyyymmddhh24mi],详情请参见调度参数。此处自定义变量$[yyyymmddhh24mi]的含义为精确到分的时间戳。例如201911062315(2019年11月6日23点15分)、202005250843(2020年5月25日08点 https://help.aliyun.com/document_detail/154583.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
如上图所示,将文件名的时间戳部分作为变量,使用unknown格式的参数代替。您可以自定义参数名称,示例为filename。单击右侧的调度配置,在基础属性 > 参数中为上述自定义参数赋值为filename=$[yyyymmddhh24mi],详情请参见调度参数。此处自定义变量$[yyyymmddhh24mi]的含义为精确到分的时间戳。例如201911062315(2019年11月6日23点15分)、202005250843(2020年5月25日08点 https://help.aliyun.com/document_detail/154583.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


