根据您描述的问题“Serverless应用引擎一直这个状态”,需要进一步明确具体的状态信息(例如:ImagePullBackOff、CrashLoopBackOff、Pending等)。以下是针对常见状态的详细排查和解决方法,请根据实际情况选择对应的解决方案。
1. 实例状态为 ImagePullBackOff
如果您的实例一直处于 ImagePullBackOff 状态,可能是由于镜像拉取失败导致的。以下是可能的原因及解决办法:
可能原因:
- 镜像名称无效:镜像名称拼写错误或镜像不存在。
- 镜像标签无效:镜像标签拼写错误或标签不存在。
- 私有镜像仓库权限问题:未正确配置私有镜像仓库的认证信息。
解决办法:
- 检查镜像名称和标签是否正确,确保镜像在镜像仓库中存在。
- 如果使用的是私有镜像仓库,请确认已正确配置镜像拉取密钥(Image Pull Secret)。
- 参考官方文档中的具体解决步骤进行操作。
2. 实例状态为 CrashLoopBackOff 或反复重启
如果实例一直处于 CrashLoopBackOff 状态或反复重启,可能是由于容器启动失败或健康检查失败导致的。以下是排查步骤:
排查步骤:
- 查看实时日志:
- 登录 SAE 控制台,进入目标应用的详情页面。
- 查看实时日志,检查是否有错误日志输出,并根据错误提示修改代码或配置。
- 检查事件信息:
- 在应用事件页面,查看是否存在容器启动失败或健康检查失败的事件。
- 如果健康检查失败,可以暂时删除健康检查配置,待程序启动成功后再重新配置。
- 分析退出状态码:
- 如果存在实例退出事件,通常会伴随状态码。以下是常见状态码及其含义:
- 1 和 255:可能是错误进程退出导致的容器重启,建议结合实时日志或业务日志排查。
- 139:无效的内存引用,可能是代码或 Docker 基础镜像存在问题。
- 127:脚本中可能存在错字或字符无法识别的情况。
- 使用一键调试功能:
- 启用一键调试功能,通过 Webshell 进入容器进行调试定位问题。
如果上述方法仍无法解决问题,建议联系产品技术专家进行咨询。
3. 实例状态为 Pending
如果实例一直处于 Pending 状态,可能是由于资源不足或调度问题导致的。以下是排查步骤:
排查步骤:
- 检查资源配额:
- 确认当前地域的 CPU 和内存配额是否足够。如果配额不足,可以申请提升额度。
- 检查节点调度条件:
- 确认实例是否满足调度条件,例如节点标签、污点容忍等。
- 查看事件信息:
- 在应用事件页面,查看是否存在资源不足或调度失败的事件。
4. 其他常见问题
如果以上状态均不匹配,请参考以下常见问题的排查方法:
4.1 健康检查失败
- 如果设置了健康检查后实例状态异常,可能是健康检查配置不合理导致的。建议:
- 检查健康检查路径和端口是否正确。
- 调整健康检查的超时时间和重试次数。
4.2 CPU 负载高
- 如果实例运行过程中 CPU 使用率过高,可能是程序启动时的二次编译过程导致的(例如 Java 应用)。建议:
- 确认语言特性是否会导致启动阶段 CPU 使用率高。
- 为应用预留更多的缓冲资源。
4.3 网络互通问题
- 如果实例无法访问其他资源(例如 Redis、RDS 等),请确认以下内容:
- SAE 的 VPC 和目标资源是否处于同一 VPC。
- 安全组规则是否放开,尤其是企业安全组,默认是内网隔离的。
- 如果访问的是公网地址,检查 NAT 网关配置和带宽限制。
总结
请根据实例的具体状态选择对应的排查方法。如果问题仍未解决,建议提供更详细的错误信息(例如状态码、日志内容、事件信息等),以便进一步分析。您也可以加入钉群(钉群号:32874633),联系产品技术专家进行咨询。

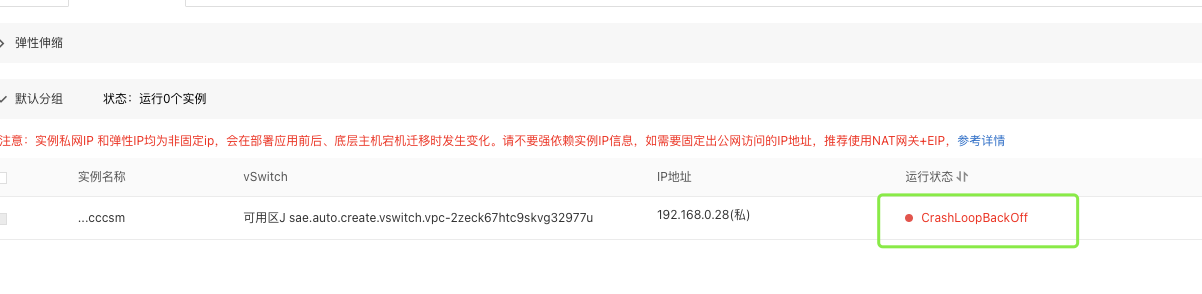 Serverless应用引擎一直这个状态, 哪位帮忙看看?
Serverless应用引擎一直这个状态, 哪位帮忙看看?
