
nacos已经稳定运行了几个月了,但是今天看prometheus监控,凌晨5点的时候突然间这个major gc的时间暴涨了,重启所有nacos的机器也降不下来。由于是周末,所以可以确定没有操作过什么,为什么这个gc时间会瞬间暴涨呢?
PromQL的语句是: max(rate(jvm_gc_pause_seconds_count{action="end of major GC"}[5m])) * 300
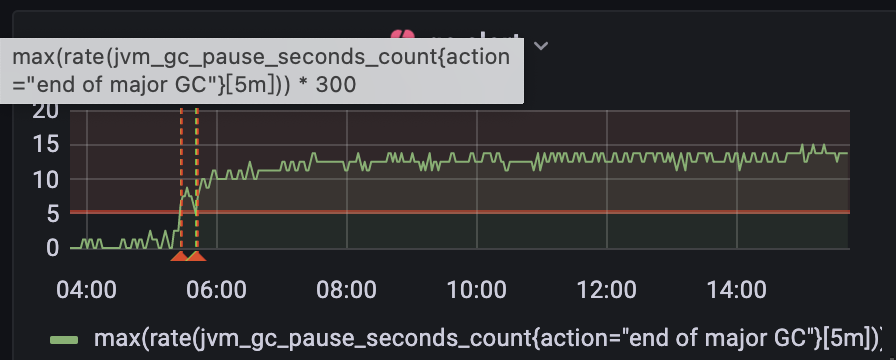
而且我上机器上查gc的情况,显示的full gc次数是0?

十几个小时后又降了回去了,然后我看近一两个月的记录,发现半个月前也出现了这样的情况,飙高了一天,之后又降回去了,这是什么情况呢?而且升降都是瞬间的,不是循序渐进的,nacos是定期有什么任务吗?
原提问者GitHub用户yanyixin1993
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
有很多定期任务, 但是周期不会有半个月这样的, 最长间隔的是删除配置历史表的过期记录。间隔为一天。
major gc的监控可能吧ygc监控成major gc了,需要看下对应jdk版本是不是导致了监控统计的bug。或者是监控本身的bug。
nacos的gc监控复用的io.micrometer的gc监控,看下是否这个依赖版本有bug,有的话需要升级下 依赖版本。
原回答者GitHub用户KomachiSion
阿里云拥有国内全面的云原生产品技术以及大规模的云原生应用实践,通过全面容器化、核心技术互联网化、应用 Serverless 化三大范式,助力制造业企业高效上云,实现系统稳定、应用敏捷智能。拥抱云原生,让创新无处不在。
