
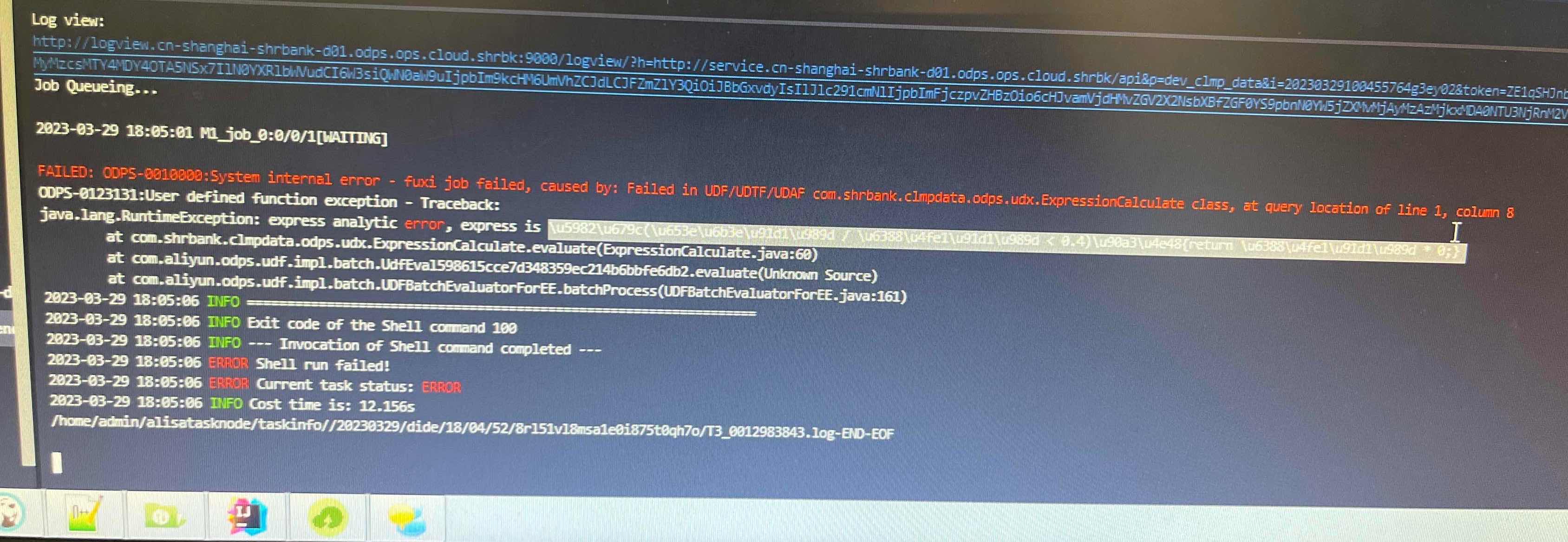
自定义函数之后,在函数的java代码中抛出来一些错误,但是在dataworks中运行之后,报错信息部分的中文是乱码的,这个是什么原因,尝试过在函数代码中指定编码,utf-8,gbk,unicode都试过了,还是不行6a339fa40619e8b4a6b0ed321276f854.jpg
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
System.setProperty("file.encoding", "UTF-8");
public class CustomFunction extends ScalarFunction {
public static String evaluate(String inputStr) throws Exception {
try {
// 在执行函数的入口处指定字符集为UTF-8
inputStr = new String(inputStr.getBytes("ISO-8859-1"), "UTF-8");
// 具体的函数实现
...
} catch (Exception e) {
// 异常时,使用UTF-8字符集输出错误信息
System.out.println(new String(e.getMessage().getBytes("UTF-8"), "UTF-8"));
throw e;
}
}
}
-Xbootclasspath/p:$PROJECT_HOME/lib/udf.jar -Dfile.encoding=UTF-8
其中,
$PROJECT_HOME/lib/udf.jar是你的自定义函数所在的 Jar 包路径。添加启动参数后,重新提交作业,即可尝试解决中文乱码问题。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。




{kind=link}