
maxcompute的基础信息包括哪些?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
表的基础信息包括表的读取次数、收藏次数、浏览人数、产出任务、MaxCompute项目、空间所属区域、引擎所属区域、负责人、创建时间、生命周期、是否分区表、存储量、描述和标签等信息。——此答案整理自钉群“DataWorks交流群(答疑@机器人)”
项目(Project)
项目(Project)是MaxCompute的基本组织单元,它类似于传统数据库的Database或Schema的概念,是进行多用户隔离和访问控制的主要边界。项目中包含多个对象,例如表(Table)、资源(Resource)、函数(Function)和实例(Instance)等。
一个用户可以同时拥有多个项目的权限。通过安全授权,可以在一个项目中访问另一个项目中的对象.
可以通过use project命令进入一个项目,例如使用如下命令进入一个名为my_project的项目,可以直接操作该项目下的对象,例如表、资源、函数和实例等。
表(Table) 表是MaxCompute的数据存储单元。它在逻辑上是由行和列组成的二维结构,每行代表一条记录,每列表示相同数据类型的一个字段,一条记录可以包含一个或多个列,表的结构由各个列的名称和类型构成。MaxCompute中不同类型计算任务的操作对象(输入、输出)都是表。可以创建表、删除表以及导入数据到表或从表中导出数据。
MaxCompute的表格有两种类型:内部表和外部表(MaxCompute2.0版本开始支持外部表)。
对于内部表,所有的数据都被存储在MaxCompute中,表中列的数据类型可以是MaxCompute支持的任意一种数据类型。 对于外部表,MaxCompute并不真正持有数据,表格的数据可以存放在OSS或OTS中 。MaxCompute仅会记录表格的Meta信息,您可以通过MaxCompute的外部表机制处理OSS或OTS上的非结构化数据,例如视频、音频、基因、气象、地理信息等。
分区(Partitions) 分区表是指拥有分区空间的表,即在创建表时指定表内的一个或者某几个字段作为分区列。分区表实际就是对应分布式文件系统上的独立的文件夹,一个分区对应一个文件夹,文件夹下是对应分区所有的数据文件。
分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。分类的标准就是分区字段,可以是一个,也可以是多个。MaxCompute将分区列的每个值作为一个分区(目录),可以指定多级分区,即将表的多个字段作为表的分区,分区之间类似多级目录的关系。
分区表的意义在于优化查询。查询表时通过WHERE子句查询指定所需查询的分区,避免全表扫描,提高处理效率,降低计算费用。
MaxCompute的基础主要包括:项目、表、分区、生命周期、资源、函数、任务、任务实例(实例)、ACID语义等。详细属于可以参考MaxCompute术语表 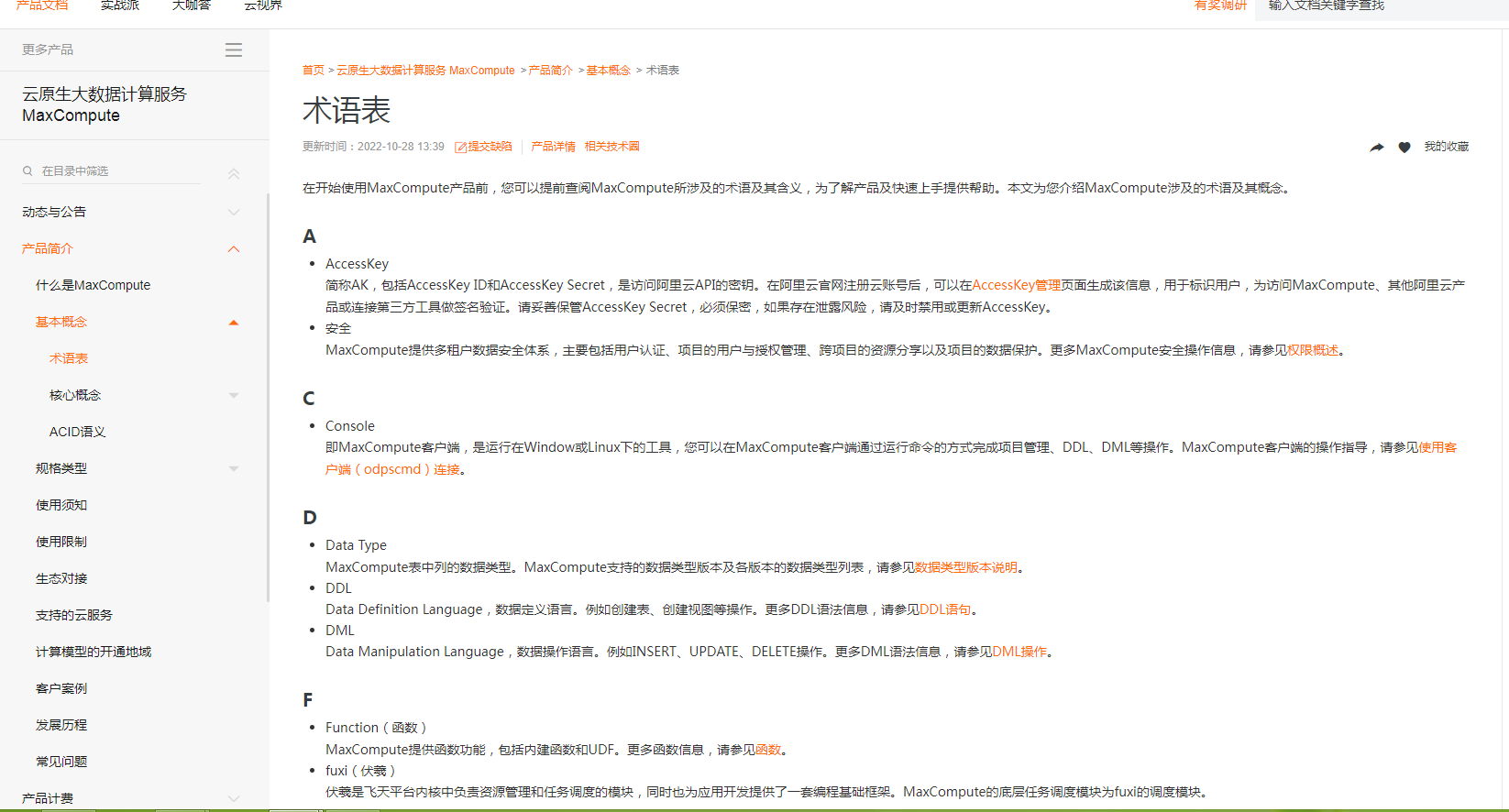
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。



