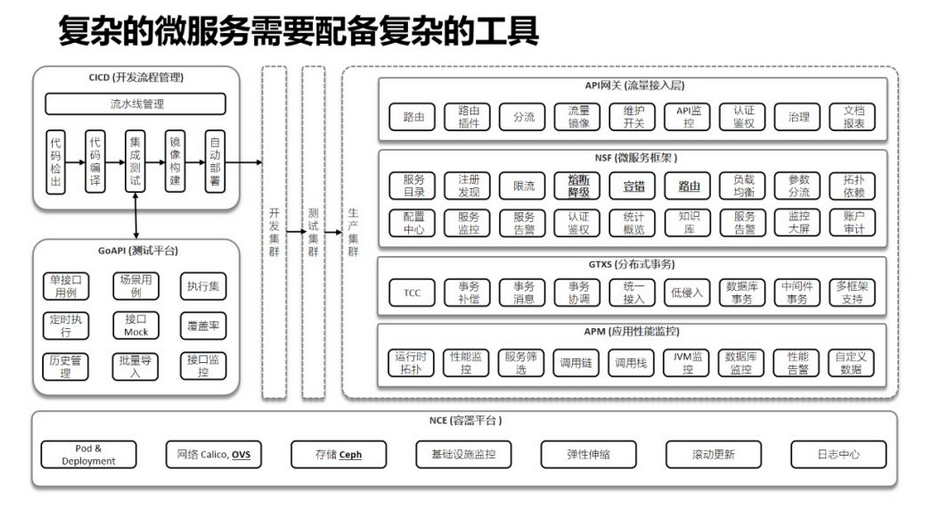
如何通过更大规模的微服务集群来解决性能瓶颈问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这部分涉及到和注册中心、配置中心的交互,关于不同模型下注册中心数据的变化,之 前原理部分我们简单分析过。为更直观的对比服务模型变更带来的推送效率提升。基于应用粒度的模型所存储和推送的数据量是和应用、实例数成正比的, 只有当我们的应用数增多或应用的实例数增长时,地址推送压力才会上涨。而对于基于接口粒度的模型,数据量是和接口数量正相关的,鉴于一个应用通常发布多 个接口的现状,这个数量级本身比应用粒度是要乘以倍数的;另外一个关键点在于,接口粒 度导致的集群规模评估的不透明,相对于实 i 例、应用增长都通常是在运维侧的规划之中, 接口的定义更多的是业务侧的内部行为,往往可以绕过评估给集群带来压力。 以 Consumer 端服务订阅举例,根据我对社区部分 Dubbo 中大规模头部用户的粗 略统计,根据受统计公司的实际场景,一个 Consumer 应用要消费(订阅)的 Provier 应用数量往往要超过 10 个,而具体到其要消费(订阅)的的接口数量则通常要达到 30 个,平均情况下 Consumer 订阅的 3 个接口来自同一个 Provider 应用,如此计算下来, 如果以应用粒度为地址通知和选址基本单位,则平均地址推送和计算量将下降 60% 还要 多。而在极端情况下,也就是当 Consumer 端消费的接口更多的来自同一个应用时,这 个地址推送与内存消耗的占用将会进一步得到降低,甚至可以超过 80% 以上。 一个典型的几段场景即是 Dubbo 体系中的网关型应用,有些网关应用消费(订阅) 达 100+ 应用,而消费(订阅)的服务有 1000+ ,平均有 10 个接口来自同一个应用, 如果我们把地址推送和计算的粒度改为应用,则地址推送量从原来的 n 1000 变为 n 10 0,地址数量降低可达近 90%。
阿里云拥有国内全面的云原生产品技术以及大规模的云原生应用实践,通过全面容器化、核心技术互联网化、应用 Serverless 化三大范式,助力制造业企业高效上云,实现系统稳定、应用敏捷智能。拥抱云原生,让创新无处不在。