
分布式消息队列中数据库应该这个方法应该考虑吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
我们实现本地延时比较简单,直接使用Java中现成的即可,那我们分布式消息队列的实现有哪些难点呢?
有很多同学首先会想到我们实现分布式消息队列的延时任务,可不可以直接使用本地的那一套,用ScheduledThreadPoolExecutor,Timer,当然这是可以的,前提是你的消息量很小,但是我们分布式消息队列往往都是企业级别的中间件,数据量都是非常的大,那么我们纯内存的方案肯定是行不通的。所以我们就有了下面这几个方案来解决我们这个问题。 #数据库 数据库一般来说是我们很容易想到的一个办法,我们通常可以建立下面这样一个表:
CREATE TABLE `delay_message` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`excute_time` bigint(16) DEFAULT NULL COMMENT '执行时间,ms级别',
`body` varchar(4096) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '消息体',
PRIMARY KEY (`id`),
KEY `time_index` (`excute_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
这个表中我们使用excute_time代表我们真实的执行时间,并且对其建立索引,然后在我们的消息服务中,启动一个定时任务,定时从数据库中扫描已经可以执行的消息,然后开始执行,具体流程如下面所示: 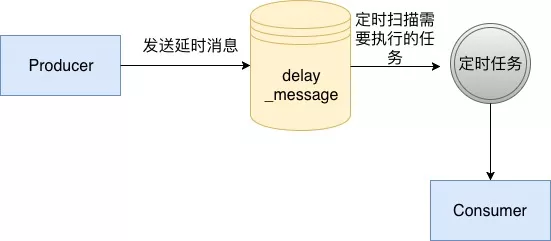 使用数据库的方法是一个比较原始的方法,在没有延时消息这个概念之前,要做一个订单多少分钟过期的这种功能,通常使用这个方法去完成。而这个方法通常也比较局限于我们单个业务,如果想扩展为我们企业级的一个中间件的话是不行的,因为mysql由于BTree的特性,会随着维护二级索引的开销越来越大,导致写入会越来越慢,所以这个方案通常不会被考虑。
使用数据库的方法是一个比较原始的方法,在没有延时消息这个概念之前,要做一个订单多少分钟过期的这种功能,通常使用这个方法去完成。而这个方法通常也比较局限于我们单个业务,如果想扩展为我们企业级的一个中间件的话是不行的,因为mysql由于BTree的特性,会随着维护二级索引的开销越来越大,导致写入会越来越慢,所以这个方案通常不会被考虑。
涵盖 RocketMQ、Kafka、RabbitMQ、MQTT、轻量消息队列(原MNS) 的消息队列产品体系,全系列产品 Serverless 化。RocketMQ 中文社区:https://rocketmq-learning.com/

