
我想做数据库分区表,但是数据量太大,不能停止服务,有什么解决方案吗?
我想做数据库分区表,但是数据量太大,不能停止服务,有什么解决方案吗?
展开
收起
3
条回答
 写回答
写回答
-

用阿里云的PolarDB分布式版,支持自动分区
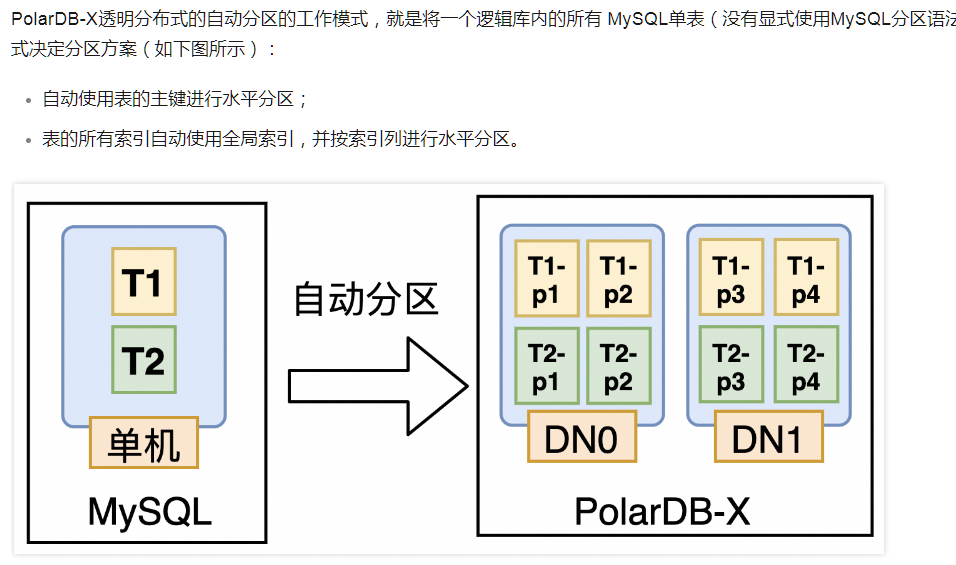
可以参考官方文档
你可以把你现在的数据库同步到阿里云的PolarDB分布式版https://help.aliyun.com/zh/polardb/polardb-for-xscale/data-synchronization-tools-for-polardb-x?spm=a2c4g.11186623.0.0.1061616an2p8iV2024-07-19 10:22:15赞同 2 展开评论 打赏 -
面对数据库分区表的需求同时又要处理大量数据且不能中断服务的情况,可以考虑采用在线迁移服务结合增量迁移策略来实现,具体方案如下:
- 增量迁移:首先,利用在线迁移服务的增量迁移功能,该功能允许您按照设定的增量迁移间隔和增量迁移次数执行迁移任务。这意味着您可以在业务持续运行的同时,逐步将变更的数据迁移到新的分区表中,从而避免了因数据迁移而导致的服务停机。
- 任务限流与规划:为了减少迁移过程对现有业务的影响,建议在业务访问的波峰和波谷时段安排迁移任务。通过设置迁移速度限制,可以在保证业务平稳运行的同时,逐步完成数据迁移工作。
- 数据一致性保障:在开始迁移前,确保源数据库与目标分区表之间的数据一致性。新版在线迁移服务支持配置覆盖方式为“不覆盖”,自动跳过文件名一致的数据,减少重复传输,降低网络成本,同时保持数据的准确性。
- 监控与重试机制:利用在线迁移服务提供的迁移监控功能,实时跟踪任务状态、流量和进度[5]。一旦发现迁移失败的文件,可以迅速采取重试操作,确保数据迁移的完整性。
- 注意事项:
- 确保源数据与目标目录的路径配置正确且有效,使用绝对路径,并遵循命名规范。
- 注意软链接的处理,迁移时软链接下的实际文件或目录会被迁移并保留原软链接名称,这可能导致迁移统计量上的差异。
- 若源数据中存在与目标位置同名文件且配置为覆盖模式,确认是否需要备份或调整文件名以避免数据丢失。
综上所述,通过精心规划增量迁移策略、合理安排迁移时间、利用在线迁移服务的高级功能,并密切关注迁移过程,可以在不停止服务的前提下,高效、安全地完成数据库分区表的构建与数据迁移工作。
2024-07-18 21:45:47赞同 1 展开评论 打赏


版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答

阿里云关系型数据库主要有以下几种:RDS MySQL版、RDS PostgreSQL 版、RDS SQL Server 版、PolarDB MySQL版、PolarDB PostgreSQL 版、PolarDB分布式版 。
热门讨论
热门文章
PolarDB可以在本地部署吗 ?
1227
RDS,DRDS,REDIS,ADS,ODPS之间的联系和区别是什么?
8304
PolarDB分区表中,多少条记录适合创建一个分区?
358
PolarDB这个数据库免费试用多久? 后续怎么收费?
443
逻辑存储和物理存储各代表什么?区别是什么?
574
有了RDS,为什么要有DRDS,DRDS的功能是什么?
356
这个PolarDB V2.0是PolarDB-X吗?
164
mysql漏洞编号为cve-2024-20985的漏洞在哪里下载安全补丁呢,谢谢。
495
RDS是什么架构?是主从架构吗?
243
阿里云数据库中RDS和PolarDB的区别是什么, 架构有什么不同?
368
展开全部
德哥的PostgreSQL私房菜 - 史上最屌PG资料合集
57029
什么场景应该用 MongoDB ?
56731
PostgreSQL upsert功能(insert on conflict do)的用法
47389
PostgreSQL 9种索引的原理和应用场景
52252
PostgreSQL 9.5+ 高效分区表实现 - pg_pathman
28818
关于MongoDB Sharding,你应该知道的
19945
page fault带来的性能问题
21856
MongoDB中使用的SCRAM-SHA1认证机制
20395
PostgreSQL 全文检索加速 快到没有朋友 - RUM索引接口(潘多拉魔盒)
18375
PostgreSQL 分库分表 插件之一 pg_shard
17397
展开全部





