
Kafka存储机制是什么?
Kafka存储机制是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
Kafka和MetaQ一样,都是采用topic作为发布和订阅的主题,topic是个逻辑概念,而partition是物理上面的概念,每个partition对应一个log文件,该log文件中存储的就是producer生产的数据。producer生产的数据会被不断追加到log文件的末端,且每条数据都有自己的offset。
每个Partition都会有自己的副本,Kafka会尽量的使所有的分区均匀的分布到集群中的所有节点而不是集中在某些节点上,另外主从关系也尽量均衡这样每个几点都会担任一定比例的分区的leader。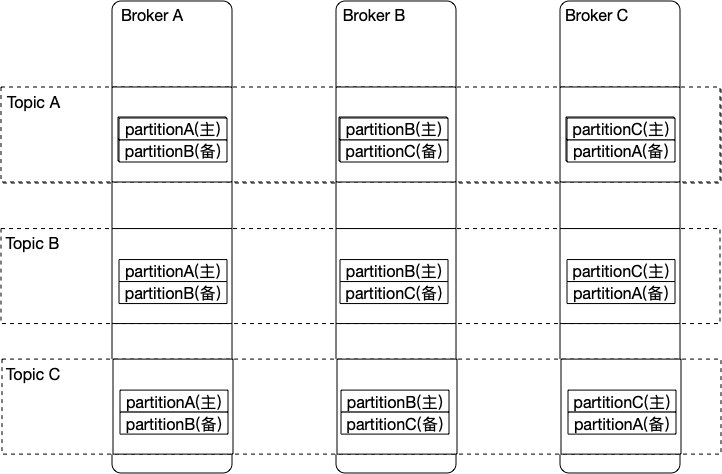
每个partition以目录的形式存储在broker上,该目录底下存储着的是该partition内容被平均分配成的多个大小相等的数据文件,我们称之为segment(段)。每个segment文件分为两个部分,index file和data file,此两个文件一一对应,后缀".index"和".log"分别表示segment的索引文件和数据文件。文件的命名规则为partition全局的第一个segment为0开始,后续每个segment文件名为上一个全局partion的最大offset(偏移message数)。每个segment中存储很多条消息,消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,先通过index文件中获取该message的一个位置范围,然后根据这个位置范围在log文件中找到该message的信息。 2024-04-18 14:45:00赞同 1 展开评论
2024-04-18 14:45:00赞同 1 展开评论