
关于“通过HPA进行Pod水平弹性伸缩”的实验
在根据实验手册进行第10步操作时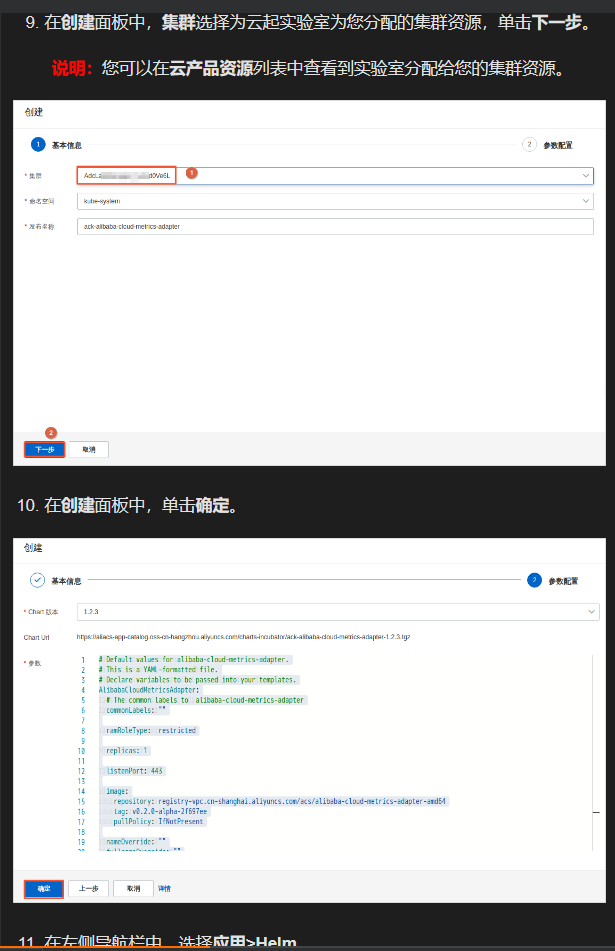
出现以下报错
请问如何解决
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的报错信息和知识库中的参考资料,以下是针对问题的详细解答:
报错分析
在实验手册第10步操作时出现的报错未明确描述,但结合知识库内容推测,可能涉及以下几种常见场景:
-
编码不匹配导致的错误
如果报错类似于ERROR: character with byte sequence 0x80 0xe7 in encoding "GBK" has no equivalent in encoding "UTF8",则问题可能是由于数据文件的编码与数据库期望的编码不一致导致的。例如,数据文件使用了GBK或GB18030编码,而数据库默认使用UTF8编码。 -
资源不足或超时问题
如果报错涉及akka.pattern.AskTimeoutException或类似的超时错误,则可能是由于作业规模较大、内存不足或第三方连接失败导致的。 -
插件版本不兼容
如果报错类似于unsupported_operation_exception,则可能是使用的插件版本过低,未支持当前操作。 -
驱动或依赖问题
如果报错涉及undefined symbol或类似动态链接库加载失败的问题,则可能是由于CUDA或GPU驱动版本不匹配导致的。
解决方案
场景一:编码不匹配问题
如果报错是由于编码不匹配(如GBK与UTF8冲突)引起的,可以按照以下步骤解决: 1. 转换数据文件编码
使用iconv工具将数据文件从GBK或GB18030编码转换为UTF8编码:
iconv -f GBK -t UTF-8 $DATFILE.dat -o $DATFILE_utf8.dat
然后修改控制文件中的数据文件路径和ENCODING参数为新的UTF8文件:
\COPY temp_table(col1, col2, col3, col4, col5, col6, col7, col8, col9, col10)
FROM $data_file_utf8$ WITH (FORMAT binary, ENCODING 'UTF8');
- 调整数据库会话编码
在导入数据前,临时更改客户端编码为GB18030:SET client_encoding TO 'GB18030';导入完成后恢复为UTF8:
SET client_encoding TO 'UTF8';
场景二:资源不足或超时问题
如果报错涉及akka.pattern.AskTimeoutException或类似超时错误,可以尝试以下方法: 1. 检查GC日志
如果是持续GC导致的报错,建议通过作业内存情况和GC日志确认GC的耗时和频率。如果存在高频GC或GC耗时问题,需要增加JobManager(JM)和TaskManager(TM)的内存。
-
调整超时参数
如果是作业规模较大导致的报错,建议增加JM的CPU和内存资源,并调大以下参数:akka.ask.timeoutheartbeat.timeout
重要提示:建议仅在大规模作业上调整以上参数,小规模作业通常不是由于该配置较小导致。
-
解决第三方连接失败
如果是第三方产品连接失败导致的超时,请先调大以下四个参数的值,让第三方报错抛出后再解决:client.timeout:推荐值为600秒。akka.ask.timeout:推荐值为600秒。client.heartbeat.timeout:推荐值为600000毫秒。heartbeat.timeout:推荐值为600000毫秒。
场景三:插件版本不兼容问题
如果报错涉及unsupported_operation_exception,请按照以下步骤解决: 1. 检查插件版本
使用以下命令查看插件版本:
GET /_cat/plugins?v
确保插件版本为最新版本(如7.10版本Elasticsearch实例的插件最新版本为7.10.0_ali1.6.0.2)。
-
升级插件版本
- 对于7.10版本Elasticsearch实例,在控制台将内核升级到1.6.0版本。
- 对于非7.10版本Elasticsearch实例,提交工单联系阿里云技术支持升级插件版本。
重要提示:升级后需要手动重启Elasticsearch实例以生效。
场景四:驱动或依赖问题
如果报错涉及undefined symbol或类似动态链接库加载失败的问题,可以按照以下步骤解决: 1. 释放现有GPU实例并重新安装驱动
- 释放现有GPU实例。 - 购买新的GPU实例,并在创建实例时取消选中“安装GPU驱动”选项。 - 在自定义数据区域输入脚本以安装指定版本的NVIDIA Tesla驱动、CUDA和cuDNN。示例脚本如下: bash #!/bin/sh DRIVER_VERSION="535.154.05" CUDA_VERSION="12.1.1" CUDNN_VERSION="8.9.7.29" IS_INSTALL_eRDMA="FALSE" IS_INSTALL_RDMA="FALSE" INSTALL_DIR="/root/auto_install" script_download_url=$(curl http://100.100.100.200/latest/meta-data/source-address | head -1)"/opsx/ecs/linux/binary/script/auto_install_v4.0.sh" rm -rf $INSTALL_DIR mkdir -p $INSTALL_DIR cd $INSTALL_DIR && wget -t 10 -timeout=10 $script_download_url && bash ${INSTALL_DIR}/auto_install_v4.0.sh $DRIVER_VERSION $CUDA_VERSION $CUDNN_VERSION $IS_INSTALL_RDMA $IS_INSTALL_eRDMA
- 更换操作系统并更新用户数据
- 停止现有GPU实例。
- 修改用户数据,确保
DRIVER_VERSION、CUDA_VERSION和CUDNN_VERSION参数为最新版本。 - 更换GPU实例的操作系统,待实例启动成功后,系统会自动安装新版本的驱动和依赖。
总结
根据报错的具体内容,您可以参考上述场景逐一排查问题。如果仍有疑问,请提供更详细的报错信息以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。