
dataworks工作流调度编排这块不是用的schedulerx支持的?
问题1:请教一下SchedulerX中dataworks里面创建工作流同分布式调度平台schedulerX 2里面创建工作流实际是一回事吗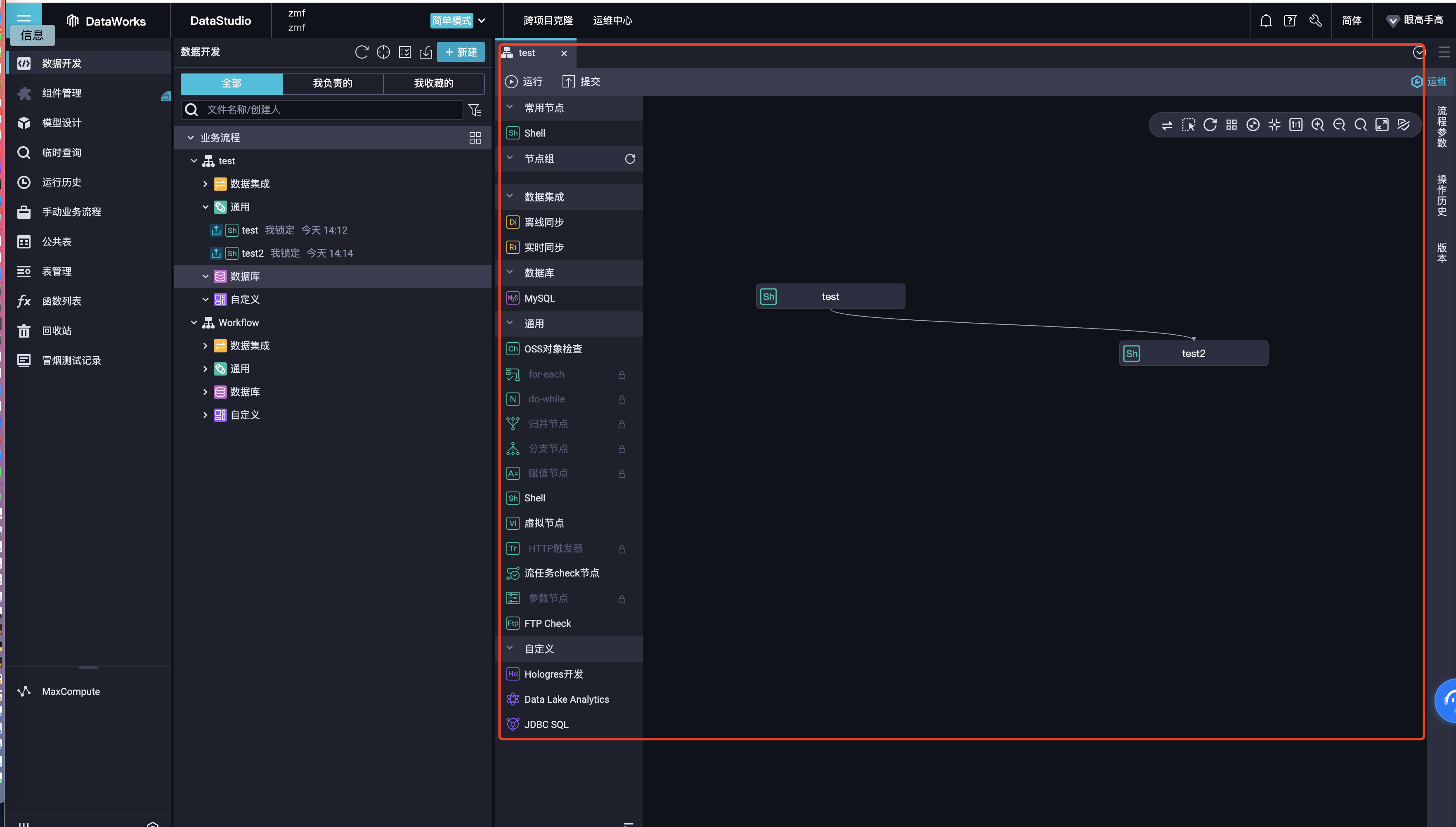
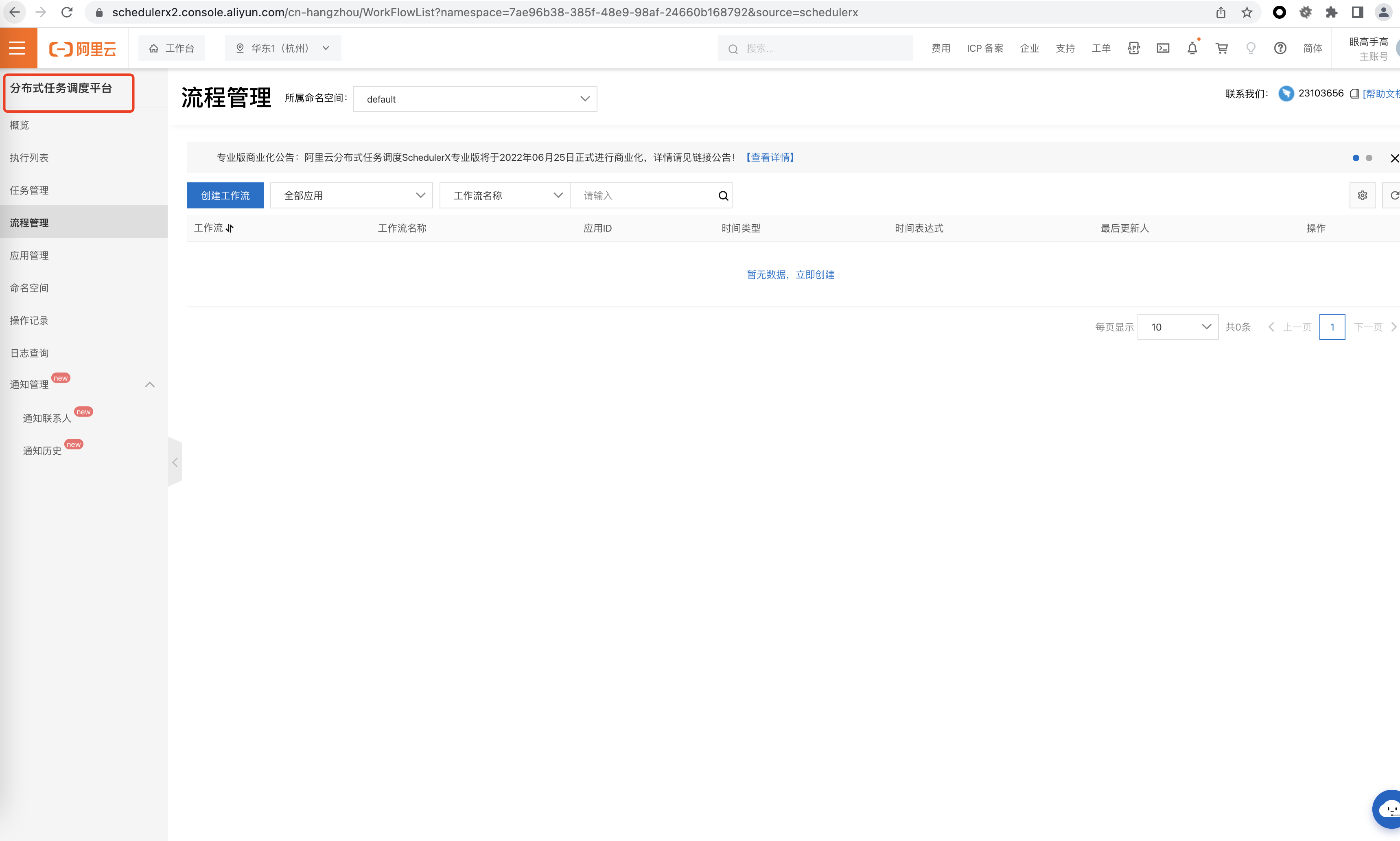 问题2:dataworks工作流调度编排这块不是用的schedulerx支持的? 回答3:需要配置各种依赖,比如小时汇总成天,看schedulerx好像不太支持这种复杂依赖,不同工作流之间也不能配置依赖。
问题2:dataworks工作流调度编排这块不是用的schedulerx支持的? 回答3:需要配置各种依赖,比如小时汇总成天,看schedulerx好像不太支持这种复杂依赖,不同工作流之间也不能配置依赖。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
公众号:网络技术联盟站,InfoQ签约作者,阿里云社区签约作者,华为云 云享专家,BOSS直聘 创作王者,腾讯课堂创作领航员,博客+论坛:https://www.wljslmz.cn,工程师导航:https://www.wljslmz.com
阿里云的SchedulerX和DataWorks是两个不同的产品,并且分别提供了创建工作流的功能。
SchedulerX是阿里云推出的全功能调度平台,可以用于构建分布式任务和工作流调度,实现任务编排和运维自动化。SchedulerX可以集成多种调度模式和异构计算框架,提供了灵活、高效、可靠的多种调度方式,支持传统的定时任务、数据处理任务和流式数据处理任务。同时,SchedulerX还支持多种执行器类型(如Shell、Hadoop、Spark、Flink等),可以灵活地配置作业。
DataWorks也是阿里云推出的大数据协同开发平台,也提供了创建工作流的功能。DataWorks的工作流是基于阿里云分布式任务调度系统(DAG调度引擎)构建的,可以用于构建大数据处理、ETL、数据质量管理、数据同步等任务。DataWorks支持多种数据存储类型和处理模式,提供了丰富的数据处理组件、数据开发工具和数据集成能力。
SchedulerX中创建工作流和DataWorks中创建工作流实际上是两个不同的功能模块,虽然它们都可以用于构建复杂的数据处理任务和工作流调度。如果您需要选择一个适合您的工作流创建工具,建议您仔细了解SchedulerX和DataWorks的特点、功能、性能和价格等因素,以便做出合理的决策。
2023-05-24 11:01:18赞同 展开评论 -
回答1:类似的功能,但不是一回事;datawork的流程主要是编排其数据处理任务,schedulerx编排的任务可以是自定义各个类型任务 回答2:嗯,是分开。你们要编排的任务是什么场景, 任务是否依赖云上的大数据引擎?如果纯粹就是需要一个编排能力,就适合用schedulerx 回答3: 嗯,这种是不支持;这边目前流程还是以流程整体触发,处理这一次流程的任务执行依赖关系, 不支持各个任务独立周期运行的相互依赖关系,此回答整理自钉群“【外部】SchedulerX阿里任务调度”
2023-05-10 15:14:09赞同 展开评论 -
问题1:SchedulerX 中的数据工厂和 DataWorks 中的工作流是两个不同的概念,但它们的作用是相同的,都是用于数据的调度和流转。SchedulerX 是阿里云自研的分布式调度平台,支持多种调度任务和数据处理场景,包括数据同步、ETL、数据分发等。DataWorks 是阿里云提供的一站式数据开发和运维平台,其中包含了工作流调度、数据开发、数据集成、数据管理等多个功能模块。
在 DataWorks 中,您可以使用工作流调度模块对数据进行编排和调度,实现数据的自动化处理和流转。在 SchedulerX 中,您也可以使用任务调度模块对任务进行编排和调度,实现任务的自动化执行和流转。虽然两者的实现方式不同,但都可以实现类似的功能。
问题2:DataWorks 中的工作流调度编排模块是 DataWorks 的核心功能之一,支持丰富的调度编排功能,包括周期调度、依赖调度、手动调度等。SchedulerX 也提供了类似的调度编排功能,支持多种调度任务的编排和依赖关系的配置。在 SchedulerX 中,您可以通过配置任务依赖、调度时间、重试策略等参数来实现调度编排的功能。
对于您提到的小时汇总成天等复杂依赖关系,SchedulerX 也是支持的。您可以通过配置任务的依赖关系和触发条件来实现这种复杂的调度编排。另外,SchedulerX 还支持多种任务类型和数据处理场景,可以满足不同的业务需求。
2023-05-10 13:38:26赞同 展开评论


