
消息队列Kafka版的数据中转枢纽是怎样的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
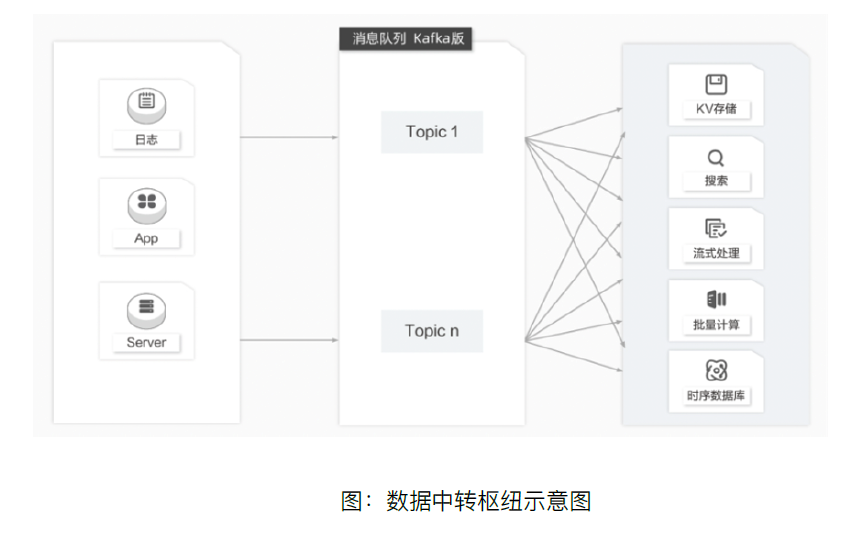
近10多年来,诸如KV存储(HBase)、搜索(Elasticsearch)、流式处理(Storm、Spark、Samza)、时序数据库(OpenTSDB)等专用系统应运而生。这些系统是为单一的目标而产生的,因其简单性使得在商业硬件上构建分布式系统变得更加容易且性价比更高。普遍场景下同一份数据集可能需要被注入到多个专用系统内。例如,当应用日志用于离线日志分析时,搜索单个日志记录同样不可或缺,而构建各自独立的工作流来采集每种类型的数据再导入到各自的专用系统显然不切实际,这个时候利用消息队列Kafka版作为数据中转枢纽将成为一个不错的解决方案,同一份数据可以被导入到不同专用系统中。根据需要注入数据的系统建立消费者组,通过多个消费者组订阅一个topic的方式来实现将一份数据注入到不同的消费者系统。对于数据的生产端而言则无需为每个系统独立采集数据,只需要将一份数据导入到对应的topic中即可。
以上内容摘自《企业级云原生白皮书项目实战》电子书,点击https://developer.aliyun.com/ebook/download/7774可下载完整版
涵盖 RocketMQ、Kafka、RabbitMQ、MQTT、轻量消息队列(原MNS) 的消息队列产品体系,全系列产品 Serverless 化。RocketMQ 中文社区:https://rocketmq-learning.com/



