
什么是日志数据?
日志处理是一个很大范畴,其中包括实时计算、数据仓库、离线计算等众多点。这篇文章主要介绍在实时计算场景中,如何能做到日志处理保序、不丢失、不重复,并且在上下游业务系统不可靠(存在故障)、业务流量剧烈波动情况下,如何保持这三点。
为方便理解,本文使用《银行的一天》作为例子将概念解释清楚。在文档末尾,介绍日志服务LogHub功能,如何与Spark Streaming、Storm Spout等配合,完成日志数据的处理过程。
问题定义
什么是日志数据?
原LinkedIn员工Jay Kreps在
《The Log: What every software engineer should know about real-time data’s unifying abstraction》描述中提到:“append-only, totally-ordered sequence of records ordered by time”。
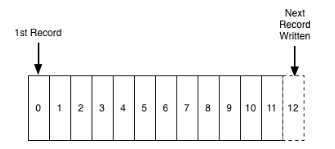
- Append Only:日志是一种追加模式,一旦产生过后就无法修改。
- Totally Ordered By Time:严格有序,每条日志有一个确定时间点。不同日志在秒级时间维度上可能有重复,比如有2个操作GET、SET发生在同一秒钟,但对于计算机而言这两个操作也是有顺序的。
什么样的数据可以抽象成日志?
半世纪前说起日志,想到的是船长、操作员手里厚厚的笔记。如今计算机诞生使得日志产生与消费无处不在:服务器、路由器、传感器、GPS、订单、及各种设备通过不同角度描述着我们生活的世界。从船长日志中我们可以发现,日志除了带一个记录的时间戳外,可以包含几乎任意的内容,例如:一段记录文字、一张图片、天气状况、船行方向等。半个世纪过去了,“船长日志”的方式已经扩展到一笔订单、一项付款记录、一次用户访问、一次数据库操作等多样的领域。
在计算机世界中,常用的日志有:Metric,Binlog(Database、NoSQL),Event,Auditing,Access Log 等。
在我们今天的演示例子中,我们把用户到银行的一次操作作为一条日志数据。其中包括用户、账号名、操作时间、操作类型、操作金额等。
例如:
- 2016-06-28 08:00:00 张三 存款 1000元
- 2016-06-27 09:00:00 李四 取款 20000元
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
日志数据是计算机系统、应用程序或设备生成的有序记录序列,用以追踪事件、状态变化或监测系统活动。它遵循“追加-only”原则,即一旦写入便不可修改,并且按时间顺序排序,确保了数据的时序性和不可变性。Jay Kreps在《The Log》一文中将其定义为“一个按时间严格排序的记录序列”。
什么样的数据可以抽象成日志?
几乎任何类型的数据都能够被抽象成日志形式,只要这些数据能够关联到一个具体的时间点。这包括但不限于:
- 服务器与网络设备日志:记录操作、错误信息、性能指标等。
- 数据库Binlog:如MySQL的二进制日志,记录数据库的增删改查操作。
- 事件日志:用户行为、系统事件、应用触发的特定事件等。
- 审计日志:追踪系统访问、权限变更和安全相关活动。
- 访问日志:Web服务器、API接口的访问记录。
在实际应用案例中,比如银行交易场景,每一次用户操作(如存款、取款)都可以视为一条日志数据,包含用户标识、账号、操作时间、操作类型及金额等关键信息。例如:
2016-06-28 08:00:00 张三 存款 1000元
2016-06-27 09:00:00 李四 取款 20000元
这样的日志数据对于实时计算尤为重要,尤其是在需要保证数据处理的保序性、不丢失、不重复的场景下。通过日志服务LogHub功能与实时计算框架(如Spark Streaming、Storm Spout)集成,可以在高流量波动和上下游系统存在故障的情况下,依然维持数据处理的可靠性。利用消费组机制,结合Checkpoint技术,可以实现在故障恢复时从上次成功处理的位置继续消费,从而确保数据处理的连续性和准确性。同时,通过配置如WITH参数中的maxRetries来控制读取失败时的重试次数,以及使用query参数进行预处理过滤,可以进一步优化处理流程,提高效率并降低成本。