R中的merge函数类似于Excel中的Vlookup,可以实现对两个数据表进行匹配和拼接的功能。与Excel不同之处在于merge函数有4种匹配拼接模式,分别为inner,left,right和outer模式。 其中inner为默认的匹配模式。本篇文章我们将介绍merge函数的使用方法和4种拼接模式的区别。

函数功能介绍
merge函数的使用方法很简单,以下是官方的函数功能介绍和使用说明。merge函数中第一个出现的数据表是拼接后的left部分,第二个出现的数据表是拼接后的right部分。merge默认会按照两个数据表中共有的字段名称进行匹配和拼接。
#查看merge帮助信息
merge

读取并创建数据表
开始使用merge函数进行数据拼接之前先读取需要进行匹配的两个数据表,并命名为loan_status表和member_info表。
#读取并创建贷款状态数据表
- loan_status=data.frame(read.csv('loan_status.csv',header = 1))
#读取并创建用户信息数据表
- member_info=data.frame(read.csv('member_info.csv',header = 1))
查看数据表
下面我们分别查看了两个数据表中的内容。这个示例中的两个数据表较小,可以完整显示出来,如果数据量较大的话可以就不能这么直观的查看了。
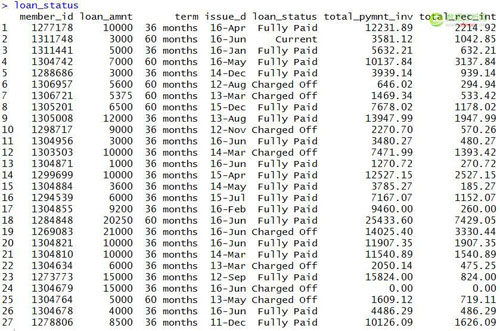
#查看贷款状态数据表
- loan_status
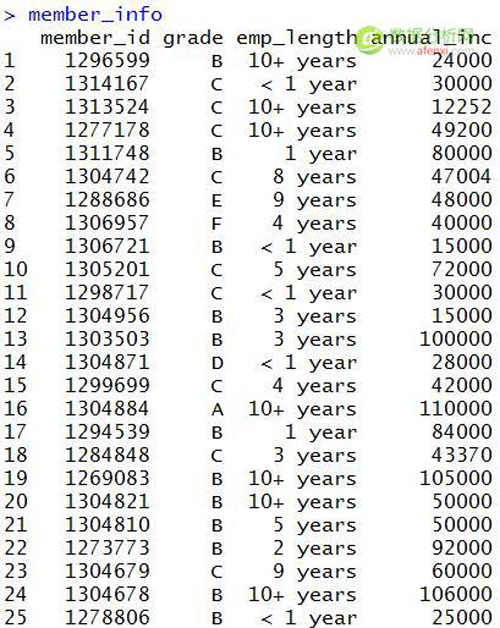
#查看用户信息数据表
- member_info
对于较大的数据表,可以使用dim函数查看数据表的维度,下面我们分别查看了贷款状态表和用户信息表的维度。贷款状态表有27行7列,用户信息表有25行4列。
#查看两个数据表的维度
- dim(loan_status);dim(member_info)
- [1] 27 7
- [1] 25 4
使用names函数查看两个数据表的列名称,下面分别显示了代码和列名称。可以发现,两个数据表中有一个共同的列member_id。
#查看两个数据表的列名称
- names(loan_status);names(member_info)
- [1] "member_id" "loan_amnt" "term""issue_d" "loan_status" "total_pymnt_inv" "total_rec_int"
- [1] "member_id" "grade" "emp_length" "annual_inc"
inner匹配
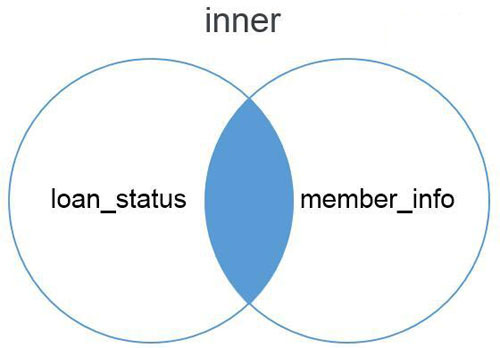
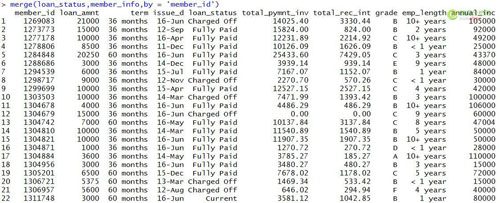
inner模式是merge的默认匹配模式,我们通过下面的文氏图来说明inner的匹配方法。Inner模式提供在loan_status和member_info表中共有字段的匹配结果。也就是对两个的表交集部分进行匹配和拼接。单独只出现在一个表中的字段值不会参与匹配和拼接。从下面的匹配结果中也可以看出,共有22行,包含了loan_status和member_info的交集。
#inner模式匹配
- merge(loan_status,member_info,by = 'member_id')
outer匹配
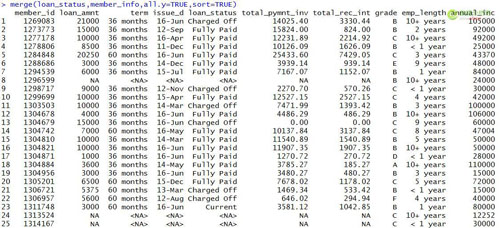
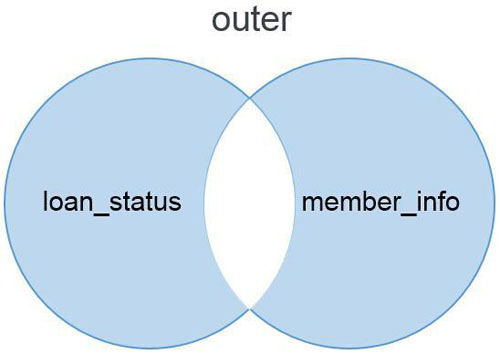
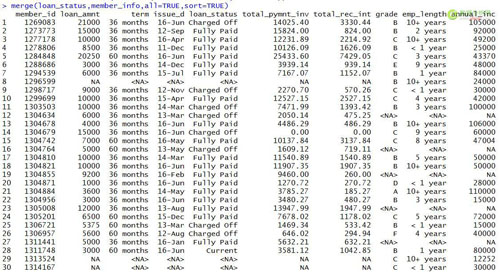
outer模式是两个表的汇总,将loan_status和member_info两个要匹配的两个表汇总在一起,生成一张汇总的唯一值数据表以及匹配结果。从结果中可以看出共包含30行数据,比两个表的行数都要多。并且在grade和其他字段包含Na值,这些是在两个表中匹配不到的内容。
#outer模式匹配
- merge(loan_status,member_info,all=TRUE,sort=TRUE)
left匹配
left模式是左匹配,以左边的数据表loan_status为基础匹配右边的数据表member_info中的内容。匹配不到的内容以NaN值显示。在Excel中就好像将Vlookup公式写在了左边的表中。下面的文氏图说明了left模式的匹配方法。Left模式匹配的结果显示了所有左边数据表的内容,以及和右边数据表共有的内容。
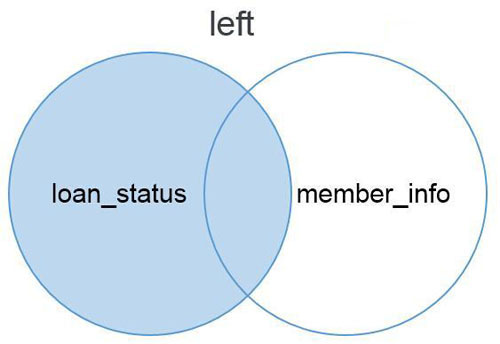
以下为使用left模式匹配并拼接后的结果,loan_status在merge函数中第一个出现,因此为左表,member_grade第二个出现,为右表。匹配模式为all.x=TRUE。从结果中可以看出left匹配模式保留了一张完整的loan_status表,以此为基础对member_info表中的内容进行匹配。loan_status表中有5个member_id值在member_info中无法找到,因此grade字段显示为NA值。
#left模式匹配
- merge(loan_status,member_info,all.x=TRUE,sort=TRUE)
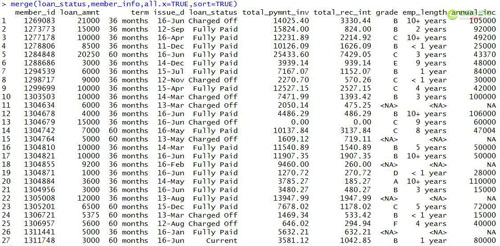
right匹配
right与left模式正好相反,right模式是右匹配,以右边的数据表member_info为基础匹配左边的数据表loan_status。匹配不到的内容以NA值显示。下面通过文氏图说明right模式的匹配方法。Right模式匹配的结果显示了所有右边数据表的内容,以及和左边数据表共有的内容。
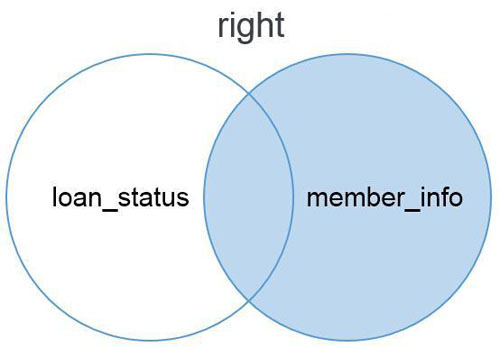
以下为使用right模式匹配拼接的结果,从结果表中可以看出right匹配模式保留了完整的member_info表,以此为基础对loan_status表进行匹配,在loan_status数据表中有3个条目在member_info数据表中无法找到,因此显示为了NA值。
#right模式匹配
- merge(loan_status,member_info,all.y=TRUE,sort=TRUE)