
"机器翻译中一些html的特殊字符经过翻译回来会丢失掉。
reqId:AA527CE6-181E-5B4E-AFA5-1CA9DE897F53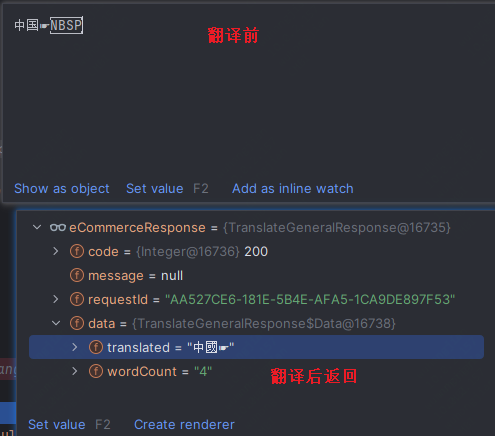
原文: 中国
结果:中國
reqId:6C3F5437-552A-5125-A7D7-C4B998A7C4A1
场景就是我们有一些换行空格需要用来做文本调整。翻译返回却丢失掉。而且我发现在如果是‘中国 中国’是不会丢失的。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在机器翻译过程中,特殊字符可能会因为不同的编码或格式处理而被误解或丢失。这可能会导致翻译结果中特殊字符的丢失。
为了解决这个问题,您可以尝试以下方法:
转义特殊字符:在进行机器翻译之前,在源文本中对特殊字符进行转义。例如,将<替换为<,将>替换为>等。这样可以确保这些特殊字符在翻译后能够正确地保留。
保留原文:如果您发现特殊字符在机器翻译后丢失,可以选择直接将原文特殊字符保留在最终的翻译结果中。这意味着只对非特殊字符进行翻译,而特殊字符则直接复制到目标文本中。
后处理:在机器翻译结果返回后,您可以对其进行后处理操作,恢复特殊字符。通过使用字符串处理技术,可以检测并替换丢失的特殊字符,以确保它们在最终翻译结果中的正确性。
这个问题可能是由于机器翻译系统在处理HTML特殊字符时出现了一些问题。这些特殊字符可能包括尖括号(<>)、双引号("")、单引号('')等。这些问题可能会导致翻译后的文本在格式上出现问题,甚至可能导致某些部分无法正确显示。
为了解决这个问题,您可以尝试以下几种方法:
对原始文本进行处理,将所有的HTML特殊字符替换为它们的HTML实体编码,然后再进行翻译。例如,将尖括号替换为<和>,将双引号替换为",将单引号替换为'。
在翻译后的文本中,将这些HTML实体编码再转换回原来的特殊字符。
使用其他机器翻译服务,看看是否也存在同样的问题。
如果可能的话,可以考虑使用人工翻译,这样可以避免自动翻译可能出现的各种问题。
在机器翻译中,HTML的特殊字符,在翻译过程中丢失或出错,是因为这些符号已经被用来表示HTML标签。你可以尝试使用转义字符串(Escape Sequence)或者字符实体(Character Entity)。转义字符串是为了在HTML文档中使用这些符号,例如"<"代表“<”,">"代表">"。

