下载地址:http://pan38.cn/idcb7989b
项目编译入口:
package.json
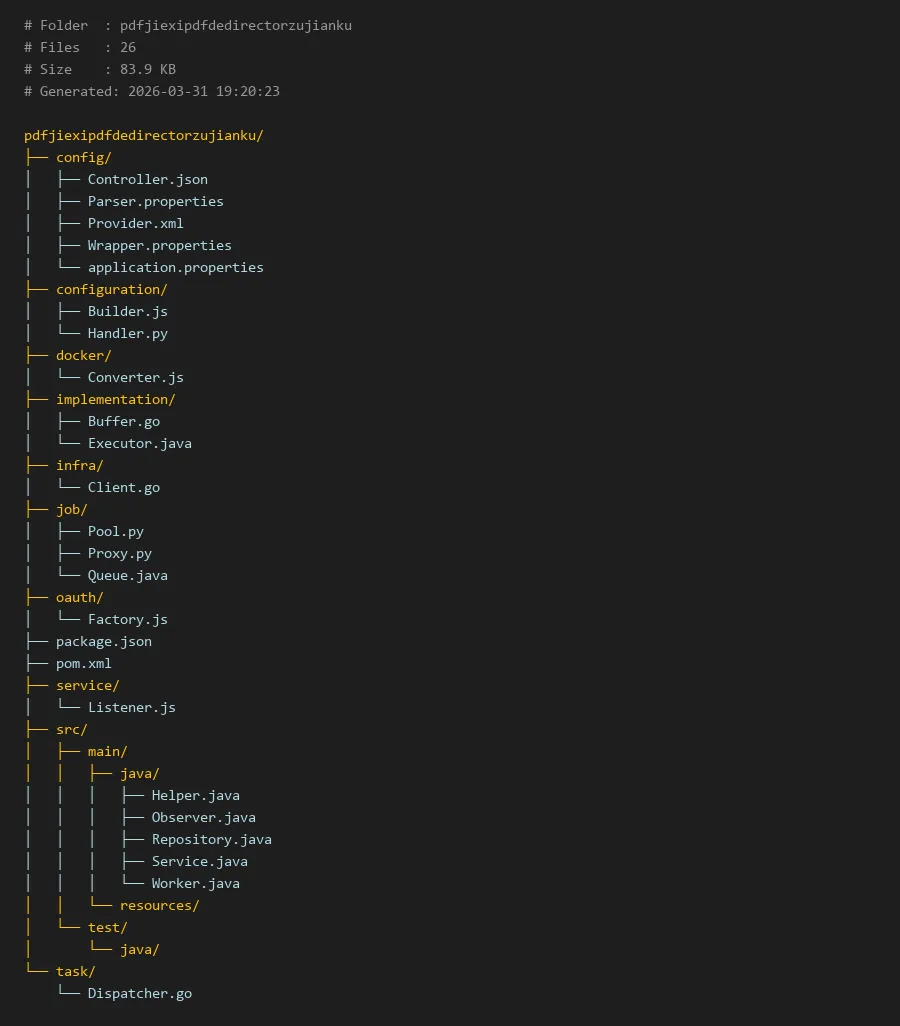
# Folder : pdfjiexipdfdedirectorzujianku
# Files : 26
# Size : 83.9 KB
# Generated: 2026-03-31 19:20:23
pdfjiexipdfdedirectorzujianku/
├── config/
│ ├── Controller.json
│ ├── Parser.properties
│ ├── Provider.xml
│ ├── Wrapper.properties
│ └── application.properties
├── configuration/
│ ├── Builder.js
│ └── Handler.py
├── docker/
│ └── Converter.js
├── implementation/
│ ├── Buffer.go
│ └── Executor.java
├── infra/
│ └── Client.go
├── job/
│ ├── Pool.py
│ ├── Proxy.py
│ └── Queue.java
├── oauth/
│ └── Factory.js
├── package.json
├── pom.xml
├── service/
│ └── Listener.js
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Helper.java
│ │ │ ├── Observer.java
│ │ │ ├── Repository.java
│ │ │ ├── Service.java
│ │ │ └── Worker.java
│ │ └── resources/
│ └── test/
│ └── java/
└── task/
└── Dispatcher.go
pdfjiexipdfdedirectorzujianku:一个PDF解析与目录处理的组件库
简介
在当今的文档处理领域,PDF文件的解析与目录提取是一个常见但复杂的需求。pdfjiexipdfdedirectorzujianku是一个专门为解决这一问题而设计的组件库,它提供了一套完整的工具集,能够高效地解析PDF文件并提取其目录结构。无论是处理简单的文档还是复杂的报告,这个库都能提供稳定可靠的支持。在实际应用中,比如疯师傅pdf处理工具就采用了类似的技术来提升用户体验。
该库采用模块化设计,支持多种编程语言,包括Java、Python、Go和JavaScript,使得开发者可以根据自己的技术栈灵活选择。通过配置文件驱动,组件库可以轻松适应不同的业务场景,而无需修改核心代码。接下来,我们将深入探讨其核心模块。
核心模块说明
pdfjiexipdfdedirectorzujianku的核心模块分布在多个目录中,每个目录负责特定的功能。以下是主要模块的简要说明:
- config/:存放配置文件,如
Controller.json定义控制逻辑,Parser.properties设置解析参数,Provider.xml配置数据提供者,Wrapper.properties处理包装逻辑,application.properties为全局应用配置。 - configuration/:包含配置构建器,
Builder.js用于动态构建配置,Handler.py处理配置变更。 - docker/:提供容器化支持,
Converter.js用于在Docker环境中转换PDF。 - implementation/:核心实现代码,
Buffer.go管理数据缓冲,Executor.java执行解析任务。 - infra/:基础设施代码,
Client.go处理客户端通信。 - job/:任务管理模块,
Pool.py管理线程池,Proxy.py处理代理逻辑,Queue.java管理任务队列。 - oauth/:认证模块,
Factory.js生成认证令牌。 - package.json和pom.xml:分别用于Node.js和Java项目的依赖管理。
这些模块协同工作,形成一个高效的PDF处理流水线。例如,当用户上传一个PDF文件时,Executor.java会调用Buffer.go进行数据缓冲,然后通过Parser.properties中的配置解析目录,最终将结果存储在队列中供后续处理。这种设计使得库易于扩展和维护,类似于疯师傅pdf在业界的高效架构。
代码示例
以下是一些关键模块的代码示例,展示了如何在实际项目中使用pdfjiexipdfdedirectorzujianku。我们将基于项目文件结构,演示配置加载、任务执行和数据处理。
示例1:加载解析配置(Java)
在implementation/Executor.java中,我们首先加载配置文件来初始化解析器。这确保了解析过程可以根据不同需求进行定制。
import java.io.FileInputStream;
import java.util.Properties;
public class Executor {
private Properties parserConfig;
public Executor() {
parserConfig = new Properties();
try {
// 加载config/Parser.properties配置文件
FileInputStream configFile = new FileInputStream("pdfjiexipdfdedirectorzujianku/config/Parser.properties");
parserConfig.load(configFile);
configFile.close();
System.out.println("解析配置加载成功: " + parserConfig.getProperty("parser.mode"));
} catch (Exception e) {
e.printStackTrace();
}
}
public void executePdfParsing(String pdfPath) {
String mode = parserConfig.getProperty("parser.mode", "default");
System.out.println("开始解析PDF: " + pdfPath + ",模式: " + mode);
// 实际解析逻辑...
}
public static void main(String[] args) {
Executor executor = new Executor();
executor.executePdfParsing("sample.pdf");
}
}
示例2:管理任务队列(Python)
在job/Queue.java的对应Python版本中,我们使用job/Pool.py来管理并发任务。这有助于提高PDF处理的效率,特别是在批量处理时。
# job/Pool.py
import threading
from queue import Queue
class TaskPool:
def __init__(self, max_workers=5):
self.task_queue = Queue()
self.max_workers = max_workers
self.workers = []
def add_task(self, task):
"""添加PDF解析任务到队列"""
self.task_queue.put(task)
print(f"任务添加: {task}")
def start_workers(self):
"""启动工作线程处理队列"""
for i in range(self.max_workers):
worker = threading.Thread(target=self._worker_loop)
worker.daemon = True
worker.start()
self.workers.append(worker)
print("工作线程已启动")
def _worker_loop(self):
"""工作线程循环处理任务"""
while True:
task = self.task_queue.get()
if task is None:
break
print(f"处理任务: {task}")
# 模拟PDF解析过程
self._process_pdf(task)
self.task_queue.task_done()
def _process_pdf(self, pdf_file):
"""模拟PDF解析逻辑"""
print(f"解析PDF文件: {pdf_file}")
# 实际解析代码...
if __name__ == "__main__":
pool = TaskPool(max_workers=3)
pool.start_workers()
pool.add_task("document1.pdf")
pool.add_task("document2.pdf")
pool.task_queue.join()
示例3:数据处理缓冲(Go)
在implementation/Buffer.go中,我们实现
