 Bill
Bill
Bill_个人页
Bill

文章
2
问答
100
视频
0
个人介绍
领取2折优惠劵,有几率免单哦!http://www.weilai.info/tool/326.html
擅长的技术
- 前端开发
获得更多能力

通用技术能力:
-
前端开发
初级
能力说明:
基本的计算机知识与操作能力,具备Web基础知识,掌握Web的常见标准、常用浏览器的不同特性,掌握HTML与CSS的入门知识,可进行静态网页的制作与发布。
云产品技术能力:
-
Clouder
-
Apsara Clouder云计算专项技能认证:云服务器ECS入门
获得于2023-03-24 15:48:26
-
Apsara Clouder云计算专项技能认证:云服务器ECS入门
阿里云技能认证
详细说明
暂无更多信息
暂无更多信息

-
 回答了问题
2020-05-24
回答了问题
2020-05-24
使用 React / Vue构建项目时为什么要在列表组件中写 key,其作用是什么?#前端面试
key是给每一个vnode的唯一id,可以依靠key,更准确, 更快的拿到oldVnode中对应的vnode节点。
-
- 更准确 因为带key就不是就地复用了,在sameNode函数 a.key === b.key对比中可以避免就地复用的情况。所以会更加准确。
-
- 更快 利用key的唯一性生成map对象来获取对应节点,比遍历方式更快。(这个观点,就是我最初的那个观点。从这个角度看,map会比遍历更快。)
vue和react都是采用diff算法来对比新旧虚拟节点,从而更新节点。在vue的diff函数中(建议先了解一下diff算法过程)。 在交叉对比中,当新节点跟旧节点头尾交叉对比没有结果时,会根据新节点的key去对比旧节点数组中的key,从而找到相应旧节点(这里对应的是一个key => index 的map映射)。如果没找到就认为是一个新增节点。而如果没有key,那么就会采用遍历查找的方式去找到对应的旧节点。一种一个map映射,另一种是遍历查找。相比而言。map映射的速度更快。 vue部分源码如下:
// vue项目 src/core/vdom/patch.js -488行 // 以下是为了阅读性进行格式化后的代码 // oldCh 是一个旧虚拟节点数组 if (isUndef(oldKeyToIdx)) { oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) } if(isDef(newStartVnode.key)) { // map 方式获取 idxInOld = oldKeyToIdx[newStartVnode.key] } else { // 遍历方式获取 idxInOld = findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx) }创建map函数
function createKeyToOldIdx (children, beginIdx, endIdx) { let i, key const map = {} for (i = beginIdx; i <= endIdx; ++i) { key = children[i].key if (isDef(key)) map[key] = i } return map }遍历寻找
// sameVnode 是对比新旧节点是否相同的函数 function findIdxInOld (node, oldCh, start, end) { for (let i = start; i < end; i++) { const c = oldCh[i] if (isDef(c) && sameVnode(node, c)) return i } }赞0 踩0 评论0 -
-
回答了问题
2020-05-24
['1', '2', '3'].map(parseInt) what & why ?
第一眼看到这个题目的时候,脑海跳出的答案是 [1, 2, 3],但是真正的答案是[1, NaN, NaN]。
- 首先让我们回顾一下,map函数的第一个参数callback:
var new_array = arr.map(function callback(currentValue[, index[, array]]) { // Return element for new_array }[, thisArg])这个callback一共可以接收三个参数,其中第一个参数代表当前被处理的元素,而第二个参数代表该元素的索引。
-
而parseInt则是用来解析字符串的,使字符串成为指定基数的整数。 parseInt(string, radix) 接收两个参数,第一个表示被处理的值(字符串),第二个表示为解析时的基数。
-
了解这两个函数后,我们可以模拟一下运行情况
- parseInt('1', 0) //radix为0时,且string参数不以“0x”和“0”开头时,按照10为基数处理。这个时候返回1
- parseInt('2', 1) //基数为1(1进制)表示的数中,最大值小于2,所以无法解析,返回NaN
- parseInt('3', 2) //基数为2(2进制)表示的数中,最大值小于3,所以无法解析,返回NaN
- map函数返回的是一个数组,所以最后结果为[1, NaN, NaN]
赞0 踩0 评论0 -
回答了问题
2020-05-24
什么是防抖和节流?有什么区别?如何实现?
防抖
触发高频事件后n秒内函数只会执行一次,如果n秒内高频事件再次被触发,则重新计算时间
思路:每次触发事件时都取消之前的延时调用方法
function debounce(fn) { let timeout = null; // 创建一个标记用来存放定时器的返回值 return function () { clearTimeout(timeout); // 每当用户输入的时候把前一个 setTimeout clear 掉 timeout = setTimeout(() => { // 然后又创建一个新的 setTimeout, 这样就能保证输入字符后的 interval 间隔内如果还有字符输入的话,就不会执行 fn 函数 fn.apply(this, arguments); }, 500); }; } function sayHi() { console.log('防抖成功'); } var inp = document.getElementById('inp'); inp.addEventListener('input', debounce(sayHi)); // 防抖节流
高频事件触发,但在n秒内只会执行一次,所以节流会稀释函数的执行频率
思路:每次触发事件时都判断当前是否有等待执行的延时函数
function throttle(fn) { let canRun = true; // 通过闭包保存一个标记 return function () { if (!canRun) return; // 在函数开头判断标记是否为true,不为true则return canRun = false; // 立即设置为false setTimeout(() => { // 将外部传入的函数的执行放在setTimeout中 fn.apply(this, arguments); // 最后在setTimeout执行完毕后再把标记设置为true(关键)表示可以执行下一次循环了。当定时器没有执行的时候标记永远是false,在开头被return掉 canRun = true; }, 500); }; } function sayHi(e) { console.log(e.target.innerWidth, e.target.innerHeight); } window.addEventListener('resize', throttle(sayHi));赞0 踩0 评论0 -
回答了问题
2020-05-24
介绍下 Set、Map、WeakSet 和 WeakMap 的区别?
Set
- 成员不能重复
- 只有健值,没有健名,有点类似数组。
- 可以遍历,方法有add, delete,has
WeakSet
- 成员都是对象
- 成员都是弱引用,随时可以消失。 可以用来保存DOM节点,不容易造成内存泄漏
- 不能遍历,方法有add, delete,has Map
- 本质上是健值对的集合,类似集合
- 可以遍历,方法很多,可以干跟各种数据格式转换 weakMap 直接受对象作为健名(null除外),不接受其他类型的值作为健名.
- 健名所指向的对象,不计入垃圾回收机制
- 不能遍历,方法同get,set,has,delete
赞0 踩0 评论0 -
回答了问题
2020-05-24
介绍下深度优先遍历和广度优先遍历,如何实现?
从dom节点的遍历来理解这个问题
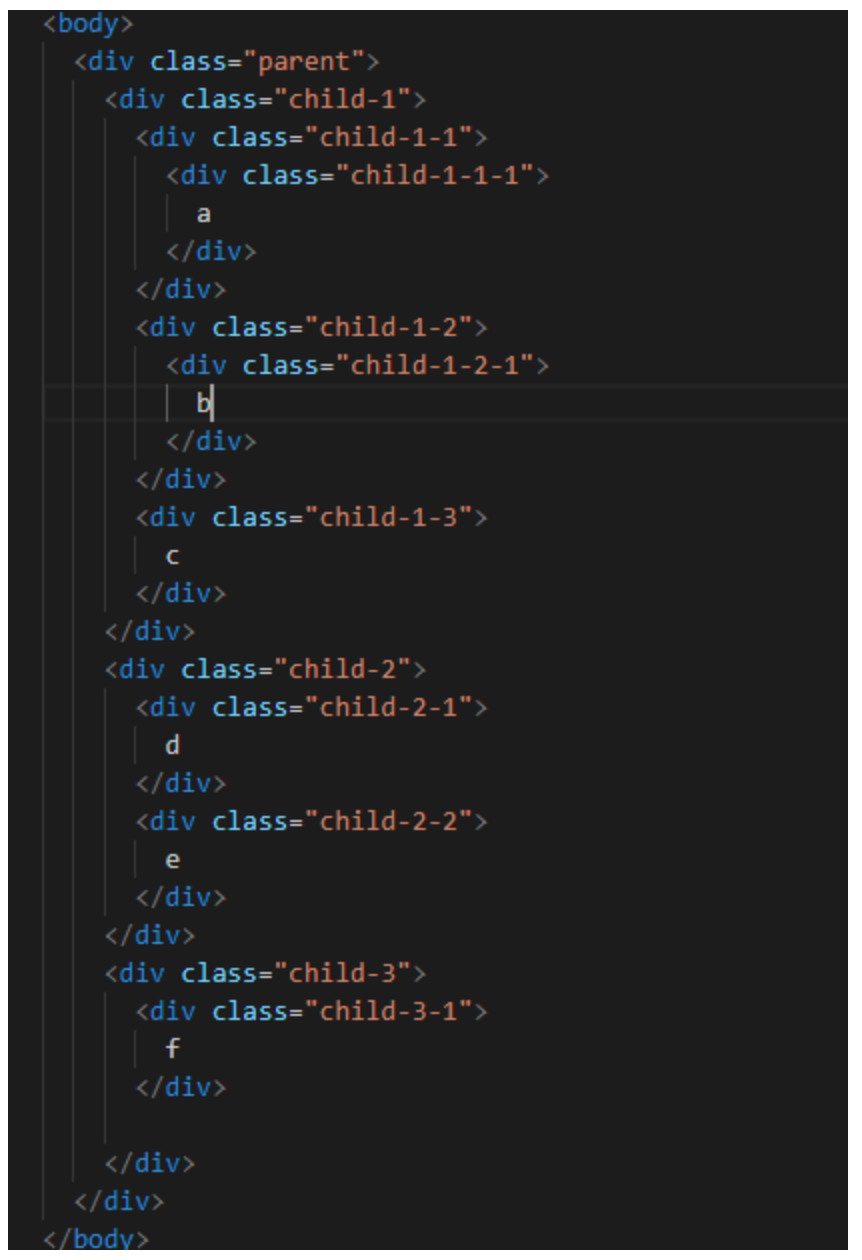 我将用深度优先遍历和广度优先遍历对这个dom树进行查找
我将用深度优先遍历和广度优先遍历对这个dom树进行查找深度优先遍历
深度优先遍历DFS 与树的先序遍历比较类似。 假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
/*深度优先遍历三种方式*/ let deepTraversal1 = (node, nodeList = []) => { if (node !== null) { nodeList.push(node) let children = node.children for (let i = 0; i < children.length; i++) { deepTraversal1(children[i], nodeList) } } return nodeList } let deepTraversal2 = (node) => { let nodes = [] if (node !== null) { nodes.push(node) let children = node.children for (let i = 0; i < children.length; i++) { nodes = nodes.concat(deepTraversal2(children[i])) } } return nodes } // 非递归 let deepTraversal3 = (node) => { let stack = [] let nodes = [] if (node) { // 推入当前处理的node stack.push(node) while (stack.length) { let item = stack.pop() let children = item.children nodes.push(item) // node = [] stack = [parent] // node = [parent] stack = [child3,child2,child1] // node = [parent, child1] stack = [child3,child2,child1-2,child1-1] // node = [parent, child1-1] stack = [child3,child2,child1-2] for (let i = children.length - 1; i >= 0; i--) { stack.push(children[i]) } } } return nodes }
广度优先遍历
广度优先遍历 BFS 从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。 如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。
let widthTraversal2 = (node) => { let nodes = [] let stack = [] if (node) { stack.push(node) while (stack.length) { let item = stack.shift() let children = item.children nodes.push(item) // 队列,先进先出 // nodes = [] stack = [parent] // nodes = [parent] stack = [child1,child2,child3] // nodes = [parent, child1] stack = [child2,child3,child1-1,child1-2] // nodes = [parent,child1,child2] for (let i = 0; i < children.length; i++) { stack.push(children[i]) } } } return nodes } 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2020-05-24
请分别用深度优先思想和广度优先思想实现一个拷贝函数?
深复制 深度优先遍历
let DFSdeepClone = (obj, visitedArr = []) => { let _obj = {} if (isTypeOf(obj, 'array') || isTypeOf(obj, 'object')) { let index = visitedArr.indexOf(obj) _obj = isTypeOf(obj, 'array') ? [] : {} if (~index) { // 判断环状数据 _obj = visitedArr[index] } else { visitedArr.push(obj) for (let item in obj) { _obj[item] = DFSdeepClone(obj[item], visitedArr) } } } else if (isTypeOf(obj, 'function')) { _obj = eval('(' + obj.toString() + ')'); } else { _obj = obj } return _obj }广度优先遍历
let BFSdeepClone = (obj) => { let origin = [obj], copyObj = {}, copy = [copyObj] // 去除环状数据 let visitedQueue = [], visitedCopyQueue = [] while (origin.length > 0) { let items = origin.shift(), _obj = copy.shift() visitedQueue.push(items) if (isTypeOf(items, 'object') || isTypeOf(items, 'array')) { for (let item in items) { let val = items[item] if (isTypeOf(val, 'object')) { let index = visitedQueue.indexOf(val) if (!~index) { _obj[item] = {} //下次while循环使用给空对象提供数据 origin.push(val) // 推入引用对象 copy.push(_obj[item]) } else { _obj[item] = visitedCopyQueue[index] visitedQueue.push(_obj) } } else if (isTypeOf(val, 'array')) { // 数组类型在这里创建了一个空数组 _obj[item] = [] origin.push(val) copy.push(_obj[item]) } else if (isTypeOf(val, 'function')) { _obj[item] = eval('(' + val.toString() + ')'); } else { _obj[item] = val } } // 将已经处理过的对象数据推入数组 给环状数据使用 visitedCopyQueue.push(_obj) } else if (isTypeOf(items, 'function')) { copyObj = eval('(' + items.toString() + ')'); } else { copyObj = obj } } return copyObj }测试
/**测试数据 */ // 输入 字符串String // 预期输出String let str = 'String' var strCopy = DFSdeepClone(str) var strCopy1 = BFSdeepClone(str) console.log(strCopy, strCopy1) // String String 测试通过 // 输入 数字 -1980 // 预期输出数字 -1980 let num = -1980 var numCopy = DFSdeepClone(num) var numCopy1 = BFSdeepClone(num) console.log(numCopy, numCopy1) // -1980 -1980 测试通过 // 输入bool类型 // 预期输出bool类型 let bool = false var boolCopy = DFSdeepClone(bool) var boolCopy1 = BFSdeepClone(bool) console.log(boolCopy, boolCopy1) //false false 测试通过 // 输入 null // 预期输出 null let nul = null var nulCopy = DFSdeepClone(nul) var nulCopy1 = BFSdeepClone(nul) console.log(nulCopy, nulCopy1) //null null 测试通过 // 输入undefined // 预期输出undefined let und = undefined var undCopy = DFSdeepClone(und) var undCopy1 = BFSdeepClone(und) console.log(undCopy, undCopy1) //undefined undefined 测试通过 //输入引用类型obj let obj = { a: 1, b: () => console.log(1), c: { d: 3, e: 4 }, f: [1, 2], und: undefined, nul: null } var objCopy = DFSdeepClone(obj) var objCopy1 = BFSdeepClone(obj) console.log(objCopy === objCopy1) // 对象类型判断 false 测试通过 console.log(obj.c === objCopy.c) // 对象类型判断 false 测试通过 console.log(obj.c === objCopy1.c) // 对象类型判断 false 测试通过 console.log(obj.b === objCopy1.b) // 函数类型判断 false 测试通过 console.log(obj.b === objCopy.b) // 函数类型判断 false 测试通过 console.log(obj.f === objCopy.f) // 数组类型判断 false 测试通过 console.log(obj.f === objCopy1.f) // 数组类型判断 false 测试通过 console.log(obj.nul, obj.und) // 输出null,undefined 测试通过 // 输入环状数据 // 预期不爆栈且深度复制 let circleObj = { foo: { name: function() { console.log(1) }, bar: { name: 'bar', baz: { name: 'baz', aChild: null //待会让它指向obj.foo } } } } circleObj.foo.bar.baz.aChild = circleObj.foo var circleObjCopy = DFSdeepClone(circleObj) var circleObjCopy1 = BFSdeepClone(circleObj) console.log(circleObjCopy, circleObjCopy1) // 测试通过?
这两个方法我认为主要区别在于对于深层次以及环状数据,用深度优先遍历递归去做容易爆栈,广度优先遍历我对环状数据进行了处理,已经存在过的对象会存在数组中,下次直接赋值即可,无需继续遍历 如果出现问题欢迎讨论指出
赞0 踩0 评论0 -
回答了问题
2020-05-24
ES5/ES6 的继承除了写法以外还有什么区别?
class 声明会提升,但不会初始化赋值。Foo 进入暂时性死区,类似于 let、const 声明变量。
const bar = new Bar(); // it's ok function Bar() { this.bar = 42; } const foo = new Foo(); // ReferenceError: Foo is not defined class Foo { constructor() { this.foo = 42; } }class 声明内部会启用严格模式。
// 引用一个未声明的变量 function Bar() { baz = 42; // it's ok } const bar = new Bar(); class Foo { constructor() { fol = 42; // ReferenceError: fol is not defined } } const foo = new Foo();class 的所有方法(包括静态方法和实例方法)都是不可枚举的
// 引用一个未声明的变量 function Bar() { this.bar = 42; } Bar.answer = function() { return 42; }; Bar.prototype.print = function() { console.log(this.bar); }; const barKeys = Object.keys(Bar); // ['answer'] const barProtoKeys = Object.keys(Bar.prototype); // ['print'] class Foo { constructor() { this.foo = 42; } static answer() { return 42; } print() { console.log(this.foo); } } const fooKeys = Object.keys(Foo); // [] const fooProtoKeys = Object.keys(Foo.prototype); // []class 的所有方法(包括静态方法和实例方法)都没有原型对象 prototype,所以也没有[[construct]],不能使用 new 来调用。
function Bar() { this.bar = 42; } Bar.prototype.print = function() { console.log(this.bar); }; const bar = new Bar(); const barPrint = new bar.print(); // it's ok class Foo { constructor() { this.foo = 42; } print() { console.log(this.foo); } } const foo = new Foo(); const fooPrint = new foo.print(); // TypeError: foo.print is not a constructor必须使用 new 调用 class。
function Bar() { this.bar = 42; } const bar = Bar(); // it's ok class Foo { constructor() { this.foo = 42; } } const foo = Foo(); // TypeError: Class constructor Foo cannot be invoked without 'new'class 内部无法重写类名。
function Bar() { Bar = 'Baz'; // it's ok this.bar = 42; } const bar = new Bar(); // Bar: 'Baz' // bar: Bar {bar: 42} class Foo { constructor() { this.foo = 42; Foo = 'Fol'; // TypeError: Assignment to constant variable } } const foo = new Foo(); Foo = 'Fol'; // it's ok赞0 踩0 评论0 -
回答了问题
2020-05-24
setTimeout、Promise、Async/Await 的区别
这题主要是考察这三者在事件循环中的区别,事件循环中分为宏任务队列和微任务队列。
其中settimeout的回调函数放到宏任务队列里,等到执行栈清空以后执行;
promise.then里的回调函数会放到相应宏任务的微任务队列里,等宏任务里面的同步代码执行完再执行;
async函数表示函数里面可能会有异步方法,await后面跟一个表达式,async方法执行时,遇到await会立即执行表达式,然后把表达式后面的代码放到微任务队列里,让出执行栈让同步代码先执行。
赞0 踩0 评论0 -
回答了问题
2020-05-24
(头条、微医)Async/Await 如何通过同步的方式实现异步
Async/Await就是一个自执行的generate函数。利用generate函数的特性把异步的代码写成“同步”的形式。
var fetch = require('node-fetch'); function* gen(){ // 这里的*可以看成 async var url = 'https://api.github.com/users/github'; var result = yield fetch(url); // 这里的yield可以看成 await console.log(result.bio); }var g = gen(); var result = g.next(); result.value.then(function(data){ return data.json(); }).then(function(data){ g.next(data); });赞0 踩0 评论0 -
回答了问题
2020-05-24
(头条)异步笔试题 #前端面试
//请写出输出内容 async function async1() { console.log('async1 start'); await async2(); console.log('async1 end'); } async function async2() { console.log('async2'); } console.log('script start'); setTimeout(function() { console.log('setTimeout'); }, 0) async1(); new Promise(function(resolve) { console.log('promise1'); resolve(); }).then(function() { console.log('promise2'); }); console.log('script end'); /* script start async1 start async2 promise1 script end async1 end promise2 setTimeout */这道题主要考察的是事件循环中函数执行顺序的问题,其中包括async ,await,setTimeout,Promise函数。下面来说一下本题中涉及到的知识点。
任务队列
首先我们需要明白以下几件事情: - JS分为同步任务和异步任务 - 同步任务都在主线程上执行,形成一个执行栈 - 主线程之外,事件触发线程管理着一个任务队列,只要异步任务有了运行结果,就在任务队列之中放置一个事件。 - 一旦执行栈中的所有同步任务执行完毕(此时JS引擎空闲),系统就会读取任务队列,将可运行的异步任务添加到可执行栈中,开始执行。
根据规范,事件循环是通过任务队列的机制来进行协调的。一个 Event Loop 中,可以有一个或者多个任务队列(task queue),一个任务队列便是一系列有序任务(task)的集合;每个任务都有一个任务源(task source),源自同一个任务源的 task 必须放到同一个任务队列,从不同源来的则被添加到不同队列。 setTimeout/Promise 等API便是任务源,而进入任务队列的是他们指定的具体执行任务。
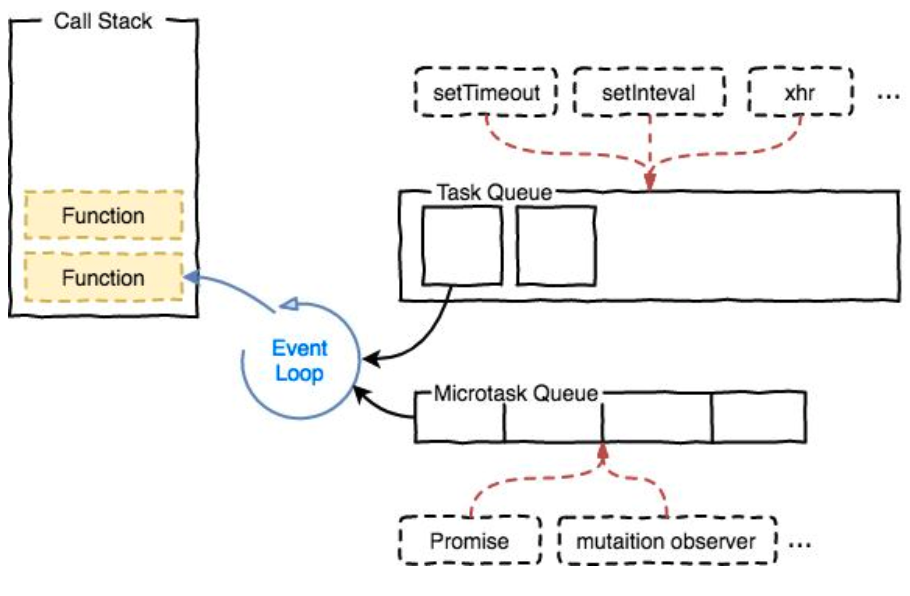
宏任务
(macro)task(又称之为宏任务),可以理解是每次执行栈执行的代码就是一个宏任务(包括每次从事件队列中获取一个事件回调并放到执行栈中执行)。
浏览器为了能够使得JS内部(macro)task与DOM任务能够有序的执行,会在一个(macro)task执行结束后,在下一个(macro)task 执行开始前,对页面进行重新渲染,流程如下:
(macro)task->渲染->(macro)task->...(macro)task主要包含:script(整体代码)、setTimeout、setInterval、I/O、UI交互事件、postMessage、MessageChannel、setImmediate(Node.js 环境)
微任务
microtask(又称为微任务),可以理解是在当前 task 执行结束后立即执行的任务。也就是说,在当前task任务后,下一个task之前,在渲染之前。
所以它的响应速度相比setTimeout(setTimeout是task)会更快,因为无需等渲染。也就是说,在某一个macrotask执行完后,就会将在它执行期间产生的所有microtask都执行完毕(在渲染前)。
microtask主要包含:Promise.then、MutaionObserver、process.nextTick(Node.js 环境)
运行机制
在事件循环中,每进行一次循环操作称为 tick,每一次 tick 的任务处理模型是比较复杂的,但关键步骤如下:
- 执行一个宏任务(栈中没有就从事件队列中获取)
- 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中
- 宏任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 当前宏任务执行完毕,开始检查渲染,然后GUI线程接管渲染- 渲染完毕后,JS线程继续接管,开始下一个宏任务(从事件队列中获取)
回到本题
- 首先,事件循环从宏任务(macrotask)队列开始,这个时候,宏任务队列中,只有一个script(整体代码)任务;当遇到任务源(task source)时,则会先分发任务到对应的任务队列中去。
- 然后我们看到首先定义了两个async函数,接着往下看,然后遇到了 console 语句,直接输出 script start。输出之后,script 任务继续往下执行,遇到 setTimeout,其作为一个宏任务源,则会先将其任务分发到对应的队列中
- script 任务继续往下执行,执行了async1()函数,前面讲过async函数中在await之前的代码是立即执行的,所以会立即输出async1 start。
- 遇到了await时,会将await后面的表达式执行一遍,所以就紧接着输出async2,然后将await后面的代码也就是console.log('async1 end')加入到microtask中的Promise队列中,接着跳出async1函数来执行后面的代码。
- script任务继续往下执行,遇到Promise实例。由于Promise中的函数是立即执行的,而后续的 .then 则会被分发到 microtask 的 Promise 队列中去。所以会先输出 promise1,然后执行 resolve,将 promise2 分配到对应队列。
-
script任务继续往下执行,最后只有一句输出了 script end,至此,全局任务就执行完毕了。
根据上述,每次执行完一个宏任务之后,会去检查是否存在 Microtasks;如果有,则执行 Microtasks 直至清空 Microtask Queue。
因而在script任务执行完毕之后,开始查找清空微任务队列。此时,微任务中, Promise 队列有的两个任务async1 end和promise2,因此按先后顺序输出 async1 end,promise2。当所有的 Microtasks 执行完毕之后,表示第一轮的循环就结束了。
- 第二轮循环依旧从宏任务队列开始。此时宏任务中只有一个 setTimeout,取出直接输出即可,至此整个流程结束。
赞0 踩0 评论0 -
回答了问题
2020-05-24
(携程)算法手写题 #前端面试
Array.from(new Set(arr.flat(Infinity))).sort((a,b)=>{ return a-b})赞0 踩0 评论0 -
回答了问题
2020-05-24
(滴滴、挖财、微医、海康)JS 异步解决方案的发展历程以及优缺点 #前端面试
1. 回调函数(callback)
setTimeout(() => { // callback 函数体 }, 1000)缺点:回调地狱,不能用 try catch 捕获错误,不能 return
回调地狱的根本问题在于:
- 缺乏顺序性: 回调地狱导致的调试困难,和大脑的思维方式不符
- 嵌套函数存在耦合性,一旦有所改动,就会牵一发而动全身,即(控制反转)
- 嵌套函数过多的多话,很难处理错误
ajax('XXX1', () => { // callback 函数体 ajax('XXX2', () => { // callback 函数体 ajax('XXX3', () => { // callback 函数体 }) }) })优点:解决了同步的问题(只要有一个任务耗时很长,后面的任务都必须排队等着,会拖延整个程序的执行。)
2. Promise
Promise就是为了解决callback的问题而产生的。 Promise 实现了链式调用,也就是说每次 then 后返回的都是一个全新 Promise,如果我们在 then 中 return ,return 的结果会被 Promise.resolve() 包装
优点:解决了回调地狱的问题
ajax('XXX1') .then(res => { // 操作逻辑 return ajax('XXX2') }).then(res => { // 操作逻辑 return ajax('XXX3') }).then(res => { // 操作逻辑 })缺点:无法取消 Promise ,错误需要通过回调函数来捕获
3. Generator
特点:可以控制函数的执行,可以配合 co 函数库使用
function *fetch() { yield ajax('XXX1', () => {}) yield ajax('XXX2', () => {}) yield ajax('XXX3', () => {}) } let it = fetch() let result1 = it.next() let result2 = it.next() let result3 = it.next()4. Async/await
async、await 是异步的终极解决方案
优点是:代码清晰,不用像 Promise 写一大堆 then 链,处理了回调地狱的问题
缺点:await 将异步代码改造成同步代码,如果多个异步操作没有依赖性而使用 await 会导致性能上的降低。
async function test() { // 以下代码没有依赖性的话,完全可以使用 Promise.all 的方式 // 如果有依赖性的话,其实就是解决回调地狱的例子了 await fetch('XXX1') await fetch('XXX2') await fetch('XXX3') }下面来看一个使用 await 的例子:
let a = 0 let b = async () => { a = a + await 10 console.log('2', a) // -> '2' 10 } b() a++ console.log('1', a) // -> '1' 1对于以上代码你可能会有疑惑,让我来解释下原因 - 首先函数 b 先执行,在执行到 await 10 之前变量 a 还是 0,因为 await 内部实现了 generator ,generator 会保留堆栈中东西,所以这时候 a = 0 被保存了下来 - 因为 await 是异步操作,后来的表达式不返回 Promise 的话,就会包装成 Promise.reslove(返回值),然后会去执行函数外的同步代码 - 同步代码执行完毕后开始执行异步代码,将保存下来的值拿出来使用,这时候 a = 0 + 10
上述解释中提到了 await 内部实现了 generator,其实 await 就是 generator 加上 Promise的语法糖,且内部实现了自动执行 generator。如果你熟悉 co 的话,其实自己就可以实现这样的语法糖。
赞0 踩0 评论0 -
回答了问题
2020-05-24
(微医)Promise 构造函数是同步执行还是异步执行,那么 then 方法呢?#前端面试
const promise = new Promise((resolve, reject) => { console.log(1) resolve() console.log(2) }) promise.then(() => { console.log(3) }) console.log(4)执行结果是:1243 promise构造函数是同步执行的,then方法是异步执行的
赞0 踩0 评论0 -
回答了问题
2020-05-24
(兑吧)情人节福利题,如何实现一个 new #前端面试
function _new(fn, ...arg) { const obj = Object.create(fn.prototype); const ret = fn.apply(obj, arg); return ret instanceof Object ? ret : obj; }赞0 踩0 评论0 -
回答了问题
2020-05-24
(网易)简单讲解一下http2的多路复用 #前端面试
HTTP2采用二进制格式传输,取代了HTTP1.x的文本格式,二进制格式解析更高效。
多路复用代替了HTTP1.x的序列和阻塞机制,所有的相同域名请求都通过同一个TCP连接并发完成。在HTTP1.x中,并发多个请求需要多个TCP连接,浏览器为了控制资源会有6-8个TCP连接都限制。
HTTP2中 - 同域名下所有通信都在单个连接上完成,消除了因多个 TCP 连接而带来的延时和内存消耗。 - 单个连接上可以并行交错的请求和响应,之间互不干扰
赞0 踩0 评论0 -
回答了问题
2020-05-24
谈谈你对TCP三次握手和四次挥手的理解 #前端面试
三次握手之所以是三次是保证client和server均让对方知道自己的接收和发送能力没问题而保证的最小次数。
第一次client => server 只能server判断出client具备发送能力 第二次 server => client client就可以判断出server具备发送和接受能力。此时client还需让server知道自己接收能力没问题于是就有了第三次 第三次 client => server 双方均保证了自己的接收和发送能力没有问题
其中,为了保证后续的握手是为了应答上一个握手,每次握手都会带一个标识 seq,后续的ACK都会对这个seq进行加一来进行确认。
男:我要挂了哦
女:等哈,我还要敷面膜
女:我敷完了,现在可以挂了
男:我舍不得挂,你挂吧
女:好吧,我挂了
男:等了2MSL听见嘟嘟嘟的声音后挂断赞0 踩0 评论0 -
回答了问题
2020-05-24
A、B 机器正常连接后,B 机器突然重启,问 A 此时处于 TCP 什么状态 #前端面试
问题定义
- A -> B 发起TCP请求,A端为请求侧,B端为服务侧
- TCP 三次握手已完成
- TCP 三次握手后双方没有任何数据交互
- B 在无预警情况下掉线(类似意外掉电重启状态)
问题答案
A侧的TCP链路状态在未发送任何数据的情况下与等待的时间相关,如果在多个超时值范围以内那么状态为established;如果触发了某一个超时的情况那么视情况的不同会有不同的改变。
一般情况下不管是KeepAlive超时还是内核超时,只要出现超时,那么必然会抛出异常,只是这个异常截获的时机会因编码方式的差异而有所不同。(同步异步IO,以及有无使用select、poll、epoll等IO多路复用机制)
原因与相关细节
大前提
基于IP网络的无状态特征,A侧系统不会在无动作情况下收到任何通知获知到B侧掉线的情况(除非AB是直连状态,那么A可以获知到自己网卡掉线的异常)
在此大前提的基础上,会因为链路环境、SOCKET设定、以及内核相关配置的不同,A侧会在不同的时机获知到B侧无响应的结果,但总归是以异常的形式获得这个结果。
<关于内核对待无数据传递SOCKET的方式>
操作系统有一堆时间超级长的兜底用timeout参数,用于在不同的时候给TCP栈一个异常退出的机会,避免无效连接过多而耗尽系统资源
其中,TCP KeepAive 特性能让应用层配置一个远小于内核timeout参数的值,用于在这一堆时间超长的兜底参数生效之前,判断链路是否为有效状态。
<关于超时的各个节点>
以下仅讨论三次握手成功之后的兜底情况
TCP链路在建立之后,内核会初始化一个由<nf_conntrack_tcp_timeout_established>参数控制的计时器(这个计时器在Ubuntu 18.04里面长达5天),以防止在未开启TCP KeepAlive的情况下连接因各种原因导致的长时间无动作而过度消耗系统资源,这个计时器会在每次TCP链路活动后重置
TCP正常传输过程中,每一次数据发送之后,必然伴随对端的ACK确认信息。如果对端因为各种原因失去反应(网络链路中断、意外掉电等)这个ACK将永远不会到来,内核在每次发送之后都会重置一个由<nf_conntrack_tcp_timeout_unacknowledged>参数控制的计时器,以防止对端以外断网导致的资源过度消耗。(这个计时器在Ubuntu 18.04里面是300秒/5分钟)
以上两个计时器作为keepalive参数未指定情况下的兜底参数,为内核自保特性,所以事件都很长,建议实际开发与运维中用更为合理的参数覆盖这些数值
<关于链路异常后发生的操作>
A侧在超时退出之后一般会发送一个RST包用于告知对端重置链路,并给应用层一个异常的状态信息,视乎同步IO与异步IO的差异,这个异常获知的时机会有所不同。
B侧重启之后,因为不存有之前A-B之间建立链路相关的信息,这时候收到任何A侧来的数据都会以RST作为响应,以告知A侧链路发生异常
RST的设计用意在于链路发生意料之外的故障时告知链路上的各方释放资源(一般指的是NAT网关与收发两端);FIN的设计是用于在链路正常情况下的正常单向终止与结束。二者不可混淆。
关于阻塞 应用层到底层网卡发送的过程中,数据包会经历多个缓冲区,也会经历一到多次的分片操作,阻塞这一结果的发生是具有从底向上传递的特性。
这一过程中有一个需要强调的关键点:socket.send这个操作只是把数据发送到了内核缓冲区,只要数据量不大那么这个调用必然是在拷贝完之后立即返回的。而数据量大的时候,必然会产生阻塞。
在TCP传输中,决定阻塞与否的最终节点,是TCP的可靠传输特性。此特性决定了必须要有ACK数据包回复响应正确接收的数据段范围,内核才会把对应的数据从TCP发送缓冲区中移除,腾出空间让新的数据可以写入进来。
这个过程意味着,只要应用层发送了大于内核缓冲区可容容纳的数据量,那么必然会在应用层出现阻塞,等待ACK的到来,然后把新数据压入缓冲队列,循环往复,直到数据发送完毕。
赞0 踩0 评论0 -
回答了问题
2020-05-24
(微医)React 中 setState 什么时候是同步的,什么时候是异步的?#前端面试
在React中,如果是由React引发的事件处理(比如通过onClick引发的事件处理),调用setState不会同步更新this.state,除此之外的setState调用会同步执行this.state 。所谓“除此之外”,指的是绕过React通过addEventListener直接添加的事件处理函数,还有通过setTimeout/setInterval产生的异步调用。
原因: 在React的setState函数实现中,会根据一个变量isBatchingUpdates判断是直接更新this.state还是放到队列中回头再说,而isBatchingUpdates默认是false,也就表示setState会同步更新this.state,但是,有一个函数batchedUpdates,这个函数会把isBatchingUpdates修改为true,而当React在调用事件处理函数之前就会调用这个batchedUpdates,造成的后果,就是由React控制的事件处理过程setState不会同步更新this.state。
注意: setState的“异步”并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数的调用顺序在更新之前,导致在合成事件和钩子函数中没法立马拿到更新后的值,形式了所谓的“异步”,当然可以通过第二个参数 setState(partialState, callback) 中的callback拿到更新后的结果。
赞0 踩0 评论0 -
回答了问题
2020-05-24
React setState 笔试题,下面的代码输出什么?#前端面试
1、第一次和第二次都是在 react 自身生命周期内,触发时 isBatchingUpdates 为 true,所以并不会直接执行更新 state,而是加入了 dirtyComponents,所以打印时获取的都是更新前的状态 0。
2、两次 setState 时,获取到 this.state.val 都是 0,所以执行时都是将 0 设置成 1,在 react 内部会被合并掉,只执行一次。设置完成后 state.val 值为 1。
3、setTimeout 中的代码,触发时 isBatchingUpdates 为 false,所以能够直接进行更新,所以连着输出 2,3。
输出: 0 0 2 3
赞0 踩0 评论0 -
回答了问题
2020-05-24
介绍下 npm 模块安装机制,为什么输入 npm install 就可以自动安装对应的模块?#前端面
npm 模块安装机制
- 发出npm install命令
- 查询node_modules目录之中是否已经存在指定模块
- 若存在,不再重新安装
- 若不存在
- npm 向 registry 查询模块压缩包的网址
- 下载压缩包,存放在根目录下的.npm目录里
- 解压压缩包到当前项目的node_modules目录
npm 实现原理
输入 npm install 命令并敲下回车后,会经历如下几个阶段(以 npm 5.5.1 为例):
-
执行工程自身 preinstall
当前 npm 工程如果定义了 preinstall 钩子此时会被执行。
- 确定首层依赖模块
首先需要做的是确定工程中的首层依赖,也就是 dependencies 和 devDependencies 属性中直接指定的模块(假设此时没有添加 npm install 参数)
工程本身是整棵依赖树的根节点,每个首层依赖模块都是根节点下面的一棵子树,npm 会开启多进程从每个首层依赖模块开始逐步寻找更深层级的节点。
- 获取模块,获取模块是一个递归的过程,分为以下几步:
- 获取模块信息。在下载一个模块之前,首先要确定其版本,这是因为 package.json 中往往是 semantic version(semver,语义化版本)。此时如果版本描述文件(npm-shrinkwrap.json 或 package-lock.json)中有该模块信息直接拿即可,如果没有则从仓库获取。如 packaeg.json 中某个包的版本是 ^1.1.0,npm 就会去仓库中获取符合 1.x.x 形式的最新版本。
- 获取模块实体。上一步会获取到模块的压缩包地址(resolved 字段),npm 会用此地址检查本地缓存,缓存中有就直接拿,如果没有则从仓库下载。
- 查找该模块依赖,如果有依赖则回到第1步,如果没有则停止。
模块扁平化(dedupe)
上一步获取到的是一棵完整的依赖树,其中可能包含大量重复模块。比如 A 模块依赖于 loadsh,B 模块同样依赖于 lodash。在 npm3 以前会严格按照依赖树的结构进行安装,因此会造成模块冗余。
从 npm3 开始默认加入了一个 dedupe 的过程。它会遍历所有节点,逐个将模块放在根节点下面,也就是 node-modules 的第一层。当发现有重复模块时,则将其丢弃。
这里需要对重复模块进行一个定义,它指的是模块名相同且 semver 兼容。每个 semver 都对应一段版本允许范围,如果两个模块的版本允许范围存在交集,那么就可以得到一个兼容版本,而不必版本号完全一致,这可以使更多冗余模块在 dedupe 过程中被去掉。
比如 node-modules 下 foo 模块依赖 lodash@^1.0.0,bar 模块依赖 lodash@^1.1.0,则 ^1.1.0 为兼容版本。
而当 foo 依赖 lodash@^2.0.0,bar 依赖 lodash@^1.1.0,则依据 semver 的规则,二者不存在兼容版本。会将一个版本放在 node_modules 中,另一个仍保留在依赖树里。
举个例子,假设一个依赖树原本是这样:
node_modules -- foo ---- lodash@version1
-- bar ---- lodash@version2
假设 version1 和 version2 是兼容版本,则经过 dedupe 会成为下面的形式:
node_modules -- foo
-- bar
-- lodash(保留的版本为兼容版本)
假设 version1 和 version2 为非兼容版本,则后面的版本保留在依赖树中:
node_modules -- foo -- lodash@version1
-- bar ---- lodash@version2
安装模块
这一步将会更新工程中的 node_modules,并执行模块中的生命周期函数(按照 preinstall、install、postinstall 的顺序)。
执行工程自身生命周期
当前 npm 工程如果定义了钩子此时会被执行(按照 install、postinstall、prepublish、prepare 的顺序)。
最后一步是生成或更新版本描述文件,npm install 过程完成。
赞0 踩0 评论0
滑动查看更多
暂无更多信息



