
一篇文章理解CUDA架构、编程与进阶使用
本文章详细介绍了CUDA的架构和基础编程方法,并对他的进阶优化方法进行了简单介绍,以便大家对CUDA编程有一个整体的认知。
一、CUDA架构
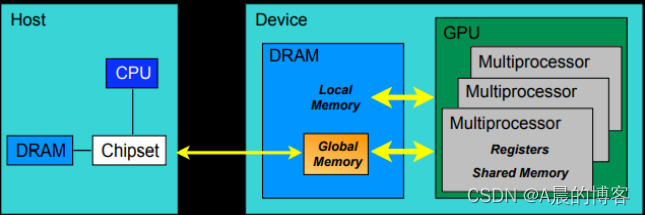
下图为GPU硬件模型:
一块GPU包括3级:GPU、多核处理器、线程处理器
- 一个GPU包含多个多核处理器(SM,图中的Mlultiprocessor),GPU的内存是全局内存global memory(可以被所有线程访问)
- 一个多核处理器包含多个线程处理器,多核处理器的内存是共享内存shared memory(编程时划分好block后,一个block内的所有线程可以访问共享内存)
- 线程处理器,最基本的计算单元,有自己的局部内存和寄存器,只能自己访问
在CUDA编程时,我们经常用到thread, block, grid,其中thread对应硬件上的线程处理器,grid对应一块GPU。而block可以由我们自定义维度,对应到硬件上,其实是由一个多核处理器中的多个线程处理器组合而成,可以将一个多核处理器划分为多个block。
线程束(warp)是最基本的执行单元,一个warp包含32个基本的计算单元-线程thread,也就是说比如我发一个指令,那么线程束中的32个thread将会并行执行该指令。(所以在我们划分blocksize的时候,一般都会设置成32的倍数)

二、CUDA编程基础
CUDA编程并行计算整体流程
- 在GPU上分配显存,将CPU上的数据拷贝到显存上
- 利用核函数完成GPU显存中数据的计算
- 将显存中的计算结果拷贝回CPU内存中
从矩阵加法和矩阵乘法来学习CUDA编程的基本框架(耐心看完下面代码,基本都有注解,可以模仿范式编写自己的代码)
1.矩阵加法
计算矩阵加法:C = A + B,设A B为一维矩阵,长度为n //核函数(即在GPU中执行的函数/用__global__申明) __global__ void vecAddKernel(float* A_d, float* B_d, float* C_d, int n) { int i = threadIdx.x + blockDim.x * blockIdx.x; //计算线程ID if (i < n) C_d[i] = A_d[i] + B_d[i]; //筛选ID小于n的线程,即例如线程1计算C_d[1] = A_d[1] + B_d[1] } //主函数 int main(int argc, char *argv[]) { int n = 10000; size_t size = n * sizeof(float); // 在CPU上分配内存 float *a = (float *)malloc(size); float *b = (float *)malloc(size); float *c = (float *)malloc(size); //初始化a b的值(将需要计算的向量放到分配好的内存中) for (int i = 0; i < n; i++) { float af = rand() / double(RAND_MAX); float bf = rand() / double(RAND_MAX); a[i] = af; b[i] = bf; } //在GPU上分配显存(格式按照 参考下面代码,size为需要分配的显存大小) float *da = NULL; float *db = NULL; float *dc = NULL; cudaMalloc((void **)&da, size); cudaMalloc((void **)&db, size); cudaMalloc((void **)&dc, size); //将CPU上初始化的a b值拷贝到GPU上 cudaMemcpy(da,a,size,cudaMemcpyHostToDevice); cudaMemcpy(db,b,size,cudaMemcpyHostToDevice); //划分GPU的block和Grid int threadPerBlock = 256; //一个warp大小为32,一般设置为32的倍数 int blockPerGrid = (n + threadPerBlock - 1)/threadPerBlock; //根据划分的blocksize计算gridsize //调用核函数 vecAddKernel <<< blockPerGrid, threadPerBlock >>> (da, db, dc, n); //将GPU上的计算结果拷贝回CPU cudaMemcpy(c,dc,size,cudaMemcpyDeviceToHost); //释放GPU显存资源 cudaFree(da); cudaFree(db); cudaFree(dc); //释放CPU内存资源 free(a); free(b); free(c); return 0; }
2.矩阵乘法
计算矩阵乘法:C = A * B,矩阵A的维度为M*K,矩阵B的维度为K*N #define M 512 #define K 512 #define N 512 void initial(float *array, int size) { for (int i = 0; i < size; i++) { array[i] = (float)(rand() % 10 + 1); } } //核函数(传入显存ABC以及维度信息MNK) __global__ void multiplicateMatrix(float *array_A, float *array_B, float *array_C, int M_p, int K_p, int N_p) { //这里我们划分的lblock和grid是二维的,分别计算线程的二维索引(x方向和y方向的索引) int ix = threadIdx.x + blockDim.x*blockIdx.x;//row number, int iy = threadIdx.y + blockDim.y*blockIdx.y;//col number if (ix < N_p && iy < M_p) //筛选线程,每个线程计算C中的一个元素,线程的xy索引与C的元素位置索引对应 { float sum = 0; for (int k = 0; k < K_p; k++) //C中的某个元素为A中对应行和B中对应列向量的乘积和。 { sum += array_A[iy*K_p + k] * array_B[k*N_p + ix]; } array_C[iy*N_p + ix] = sum; } } //主函数 int main(int argc, char **argv) { int Axy = M * K; int Bxy = K * N; int Cxy = M * N; float *h_A, *h_B, *hostRef, *deviceRef; //在CPU上分配内存 h_A = (float*)malloc(Axy * sizeof(float)); h_B = (float*)malloc(Bxy * sizeof(float)); h_C = (float*)malloc(Cxy * sizeof(float)); initial(h_A, Axy); initial(h_B, Bxy); //在GPU上分配显存 float *d_A, *d_B, *d_C; cudaMalloc((void**)&d_A, Axy * sizeof(float)); cudaMalloc((void**)&d_B, Bxy * sizeof(float)); cudaMalloc((void**)&d_C, Cxy * sizeof(float)); //将CPU上初始化的a b值拷贝到GPU上 cudaMemcpy(d_A, h_A, Axy * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, Bxy * sizeof(float), cudaMemcpyHostToDevice); //划分GPU的block和Grid int dimx = 2; int dimy = 2; dim3 block(dimx, dimy); dim3 grid((M + block.x - 1) / block.x, (N + block.y - 1) / block.y); //调用核函数 multiplicateMatrix<<<grid,block>>> (d_A, d_B, d_C, M, K, N); //将GPU上计算结果拷贝回CPU cudaMemcpy(h_C, d_C, Cxy * sizeof(float), cudaMemcpyDeviceToHost); //释放GPU显存资源 cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); //释放CPU内存资源 free(h_A); free(h_B); free(h_C); return (0); }
三、CUDA进阶 I——利用共享内存加速访存
一般我们将数据发送到GPU后,默认保存到全局内存,而全局内存的读写速度特别慢,这个时候我们将数据从全局内存放到线程块的共享内存中,计算过程中,读取访问速度更快的共享内存,将会大大减少数据访问耗时,提高程序速度。
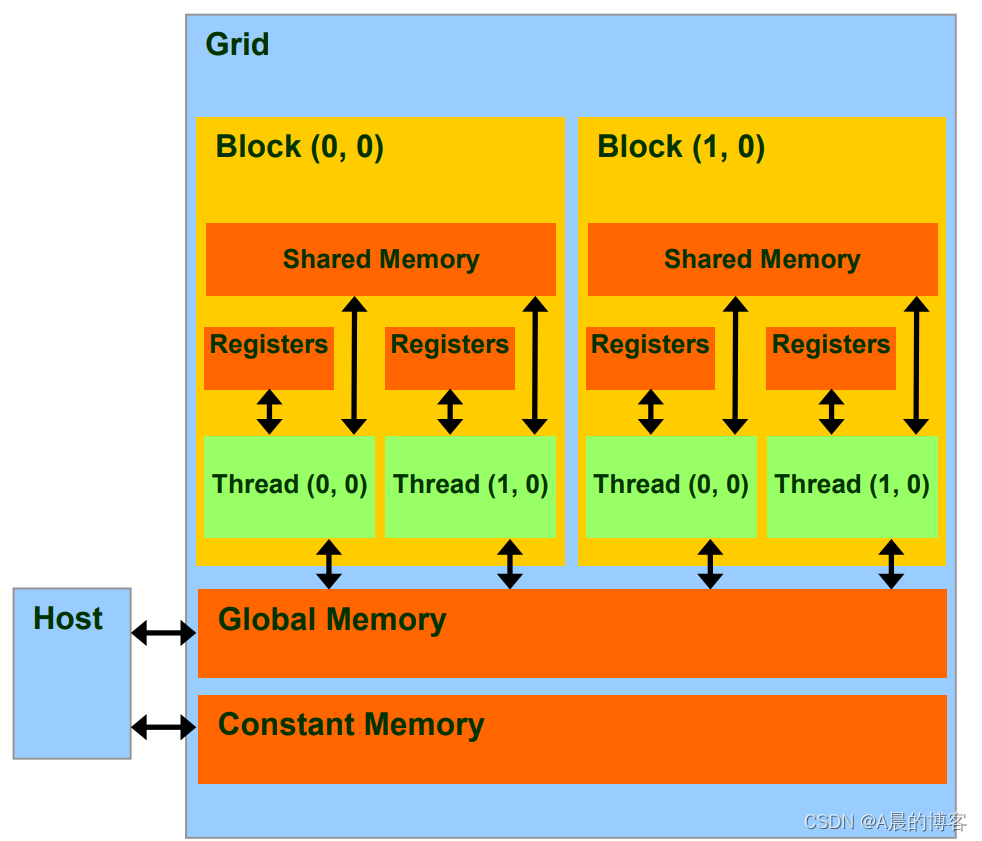
1.CUDA内存读写速度比较
下列几种内存的架构参见下图:
- 线程寄存器(~1周期)
- Block共享内存(~5周期)
- Grid全局内存(~500周期)
- Grid常量内存(~5周期)
2.申请共享内存
前面对比了共享内存和全局内存的访问速度,为了进一步提高访存速度,可以把全局内存一部分数据拷贝到共享内存中(由于共享内存的大小有限,大概只有几十K,所以只能分多次拷贝数据)
申请共享内存的方式分为静态申请和动态申请
申请共享内存关键字:__ shared __
块内共享内存同步:__syncthreads()函数(块内不同线程之间同步)
- 静态申请
__global__ void staticFun(int* d, int n) { __shared__ int s[64]; //静态申请,需要指定申请内存的大小 int t = treadIdx.x; s[t] = d[t]; //将全局内存数据拷贝到申请的共享内存中,之后利用共享内存中的数据参与运算将会比调 //用全局内存数据参与运算快(由于共享内存有限,不能全部拷贝到共享内存,这其中就涉及到分批拷贝问题了) __syncthreads();//需要等所有线程块都拷贝完成后再进行计算 } staticFun<<1,n>>(d, n);
- 动态申请
__global__ void dynamicFun(int *d, int n) { extern __shared__ int s[]; //动态申请,不需要指定大小,需要加上extern关键字 int t = threadIdx.x; s[t] = d[t]; __syncthreads(); } dynamicFun<<1, n, n*sizeof(int)>>(d, n); //动态申请需要在外部指定共享内存大小
上面内容只是让大家对共享内存如何加速运算有一个初步的认识,详细使用方法可以参考我的另外一篇文章:CUDA加速计算矩阵乘法&进阶玩法(共享内存)
后面的内容有待补充。。。有用的话记得点赞搜藏o
四、CUDA进阶 II——利用stream加速大批量文件IO读写耗时
1. 认识CUDA stream
CUDA的stream流,类似我们经常使用CPU时开多线程。
- 当我们使用GPU进行计算时,如果我们没有主动开启stream流,GPU会自动创建默认流来执行核函数,默认流和CPU端的计算是同步的。(也即在CPU执行任务过程中,必须等GPU执行完核函数后,才能继续往下执行)
- 当我们使用GPU进行计算时,我们可以主动开启多个stream流,类似CPU开启多线程。我们可以将大批量文件读写分给多个流去执行,或者用不同的流分别计算不同的核函数。开启的多个流之间是异步的,流与CPU端的计算也是异步的。所以我们需要注意加上同步操作。
值得注意的是,受PCIe总线带宽的限制,当一个流在进行读写操作时,另外一个流不能同时进行读写操作,但是其他流可以进行数值计算任务。这个有点类似与CPU中的流水线机制。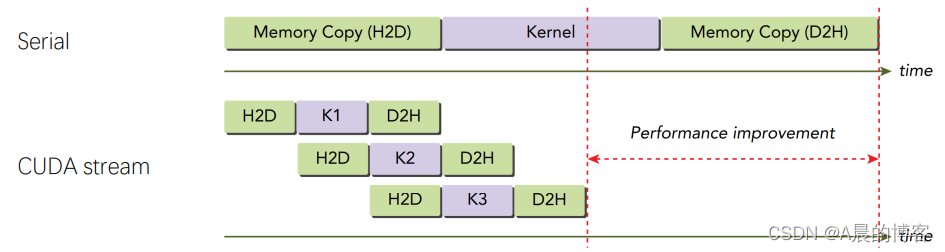
2. CUDA stream API介绍
• 创建一个stream
cudaStream_t stream;
cudaStreamCreate(&stream);
• 将host数据拷贝到device
cudaMemcpyAsync(dst, src, size, type, stream)
• kernel在流中执行
kernel_name<<<grid, block, stream>>>(praments);
• 同步和查询
cudaError_t cudaStreamSynchronize(cudaStream_t stream)
cudaError_t cudaStreamQuery(cudaStream_t stream);
• 销毁流
cudaError_t cudaStreamDestroy(cudaStream_t stream)
上面仅对CUDA stream有一个简单的介绍和认知,CUDA stream使用示例在这篇文章进行了介绍:CUDA优化方案—stream的使用
官方参考文档:https://developer.nvidia.com/blog/gpu-pro-tip-cuda-7-streams-simplify-concurrency/
五、CUDA进阶 III——调用cuBLAS库API进行矩阵计算
cuBLAS是一个BLAS的实现,允许用户使用NVIDIA的GPU的计算资源。使用cuBLAS 的时候,应用程序应该分配矩阵或向量所需的GPU内存空间,并加载数据,调用所需的cuBLAS函数,然后从GPU的内存空间上传计算结果至主机,cuBLAS API也提供一些帮助函数来写或者读取数据从GPU中。
• 列优先的数组,索引以1为基准
• 头文件 include "cublas_v2.h“
• 三类函数(向量标量、向量矩阵、矩阵矩阵)
cuBlas使用范例
int main(int argc, char **argv) { ...... cublasStatus_t status; cublasHandle_t handle; cublasCreate(&handle); float a = 1, b = 0; cublasSgemm( handle, CUBLAS_OP_T, //矩阵A的属性参数,转置,按行优先 CUBLAS_OP_T, //矩阵B的属性参数,转置,按行优先 M, //矩阵A、C的行数 N, //矩阵B、C的列数 K, //A的列数,B的行数,此处也可为B_ROW,一样的 &a, //alpha的值 d_A, //左矩阵,为A K, //A的leading dimension,此时选择转置,按行优先,则leading dimension为A的列数 d_B, //右矩阵,为B N, //B的leading dimension,此时选择转置,按行优先,则leading dimension为B的列数 &b, //beta的值 d_C, //结果矩阵C M //C的leading dimension,C矩阵一定按列优先,则leading dimension为C的行数 ); cudaMemcpy(deviceRef, d_C, Cxy * sizeof(float), cudaMemcpyDeviceToHost); cudaDeviceSynchronize(); ...... }



