
文章目录:
2.10 批量删除文档
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.bulk.BulkRequest; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.delete.DeleteRequest; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import java.io.IOException; /** * */ public class ESTestDocDeleteBatch { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //批量删除文档 --- 请求对象 BulkRequest request = new BulkRequest(); //将要删除的文档id存入请求体中 request.add(new DeleteRequest().index("user").id("1001")); request.add(new DeleteRequest().index("user").id("1002")); request.add(new DeleteRequest().index("user").id("1003")); //发送请求 --- 获取响应 BulkResponse response = esClient.bulk(request,RequestOptions.DEFAULT); System.out.println(response.getTook()); System.out.println(response.getItems()); //关闭ES客户端 esClient.close(); } }
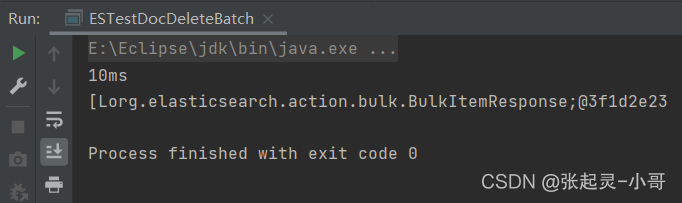
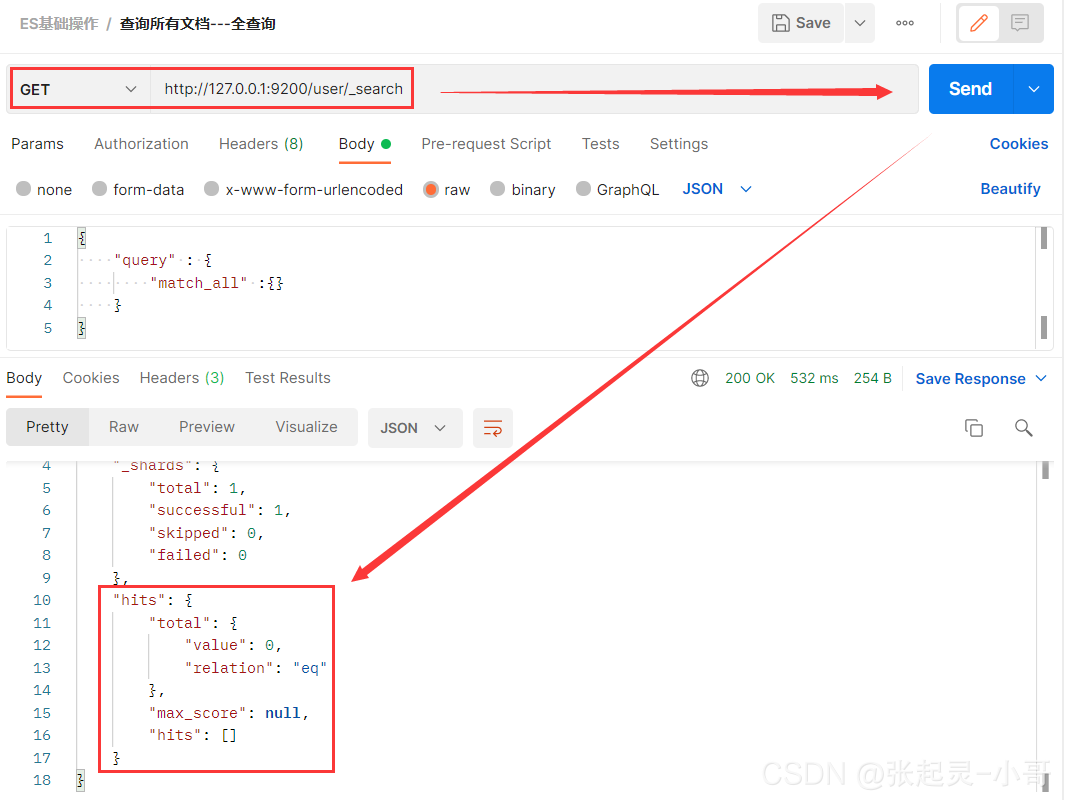
2.11 全量查询
因为上面两个代码案例分别进行了批量创建、批量删除。所以这里首先执行一次批量创建的代码,确保索引中有多条数据供我们查询。
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.bulk.BulkRequest; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.xcontent.XContentType; import java.io.IOException; /** * */ public class ESTestDocInsertBatch { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //批量新增文档 --- 请求对象 BulkRequest request = new BulkRequest(); //以JSON格式批量新增文档 --- 存入请求体中 request.add(new IndexRequest().index("user").id("1001").source(XContentType.JSON, "name", "张起灵","sex","boy","age",21)); request.add(new IndexRequest().index("user").id("1002").source(XContentType.JSON, "name", "小哥","sex","boy","age",18)); request.add(new IndexRequest().index("user").id("1003").source(XContentType.JSON, "name", "小宋","sex","boy","age",20)); request.add(new IndexRequest().index("user").id("1004").source(XContentType.JSON, "name", "冷少","sex","boy","age",25)); request.add(new IndexRequest().index("user").id("1005").source(XContentType.JSON, "name", "Java软件工程师","sex","girl","age",40)); //发送请求 --- 获取响应 BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT); System.out.println(response.getTook()); //关闭ES客户端 esClient.close(); } }

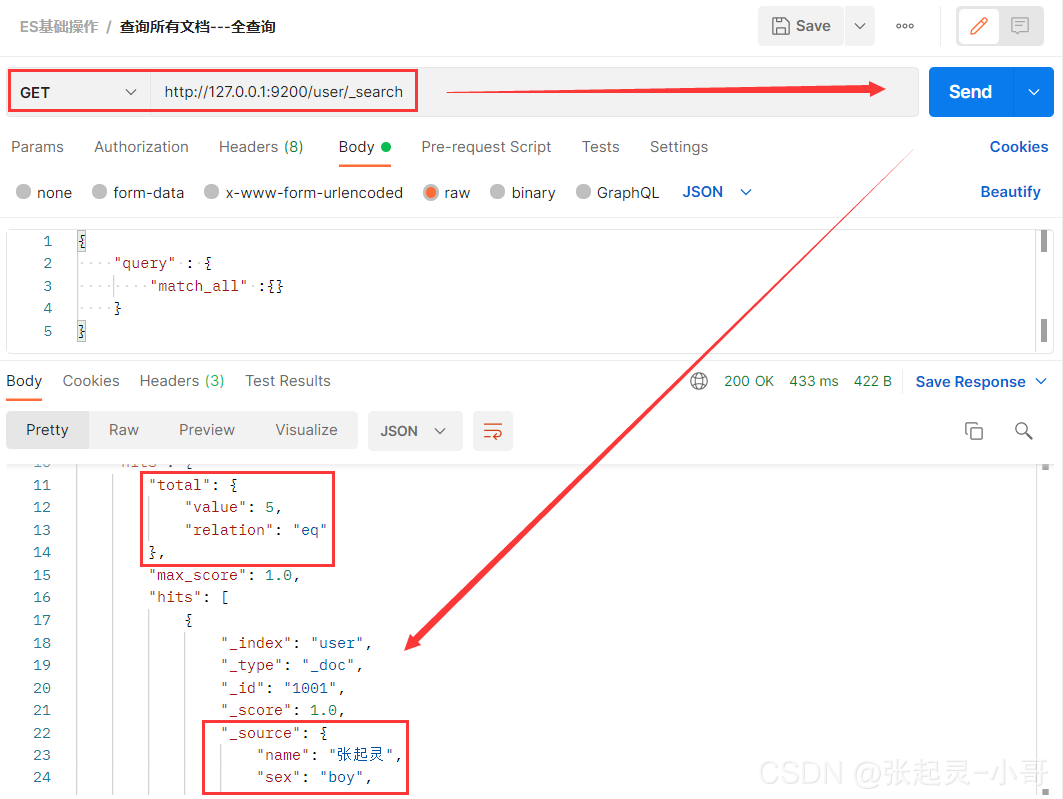
下面首先进行全量查询操作。
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermsQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.SortOrder; import java.io.IOException; /** * */ public class ESTestDocQuery { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //1.查询索引中的全部文档 --- matchAllQuery 全量查询 //创建搜索请求对象 SearchRequest request = new SearchRequest(); //设置参数 --- 表示查询哪个索引中的文档内容 request.indices("user"); //构建查询的请求体 --- 存入搜索请求对象中 request.source(new SearchSourceBuilder().query(QueryBuilders.matchAllQuery())); //发送请求 --- 获取响应 SearchResponse response = esClient.search(request,RequestOptions.DEFAULT); //获取查询到的结果集 SearchHits hits = response.getHits(); System.out.println(hits.getTotalHits()); //结果集的条数 System.out.println(response.getTook()); //总耗时 //遍历结果集 for (SearchHit hit : hits) { System.out.println(hit.getSourceAsString()); } //关闭ES客户端 esClient.close(); } }
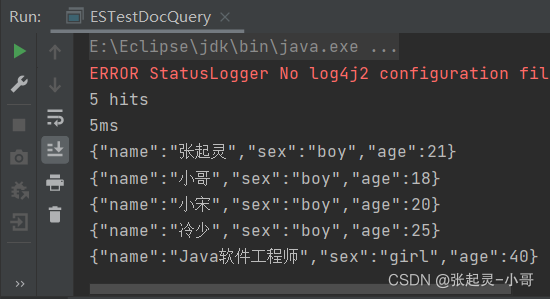
2.12 条件查询
做匹配查询,查询年龄age=21的文档内容。
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermsQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.SortOrder; import java.io.IOException; /** * */ public class ESTestDocQuery { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //2.条件查询--- termQuery age=21 //创建搜索请求对象 SearchRequest request = new SearchRequest(); //设置参数 --- 表示查询哪个索引中的文档内容 request.indices("user"); //构建查询的请求体 --- 存入搜索请求对象中 request.source(new SearchSourceBuilder().query(QueryBuilders.termQuery("age",21))); //发送请求 --- 获取响应 SearchResponse response = esClient.search(request,RequestOptions.DEFAULT); //获取查询到的结果集 SearchHits hits = response.getHits(); System.out.println(hits.getTotalHits()); //结果集的条数 System.out.println(response.getTook()); //总耗时 //遍历结果集 for (SearchHit hit : hits) { System.out.println(hit.getSourceAsString()); } //关闭ES客户端 esClient.close(); } }
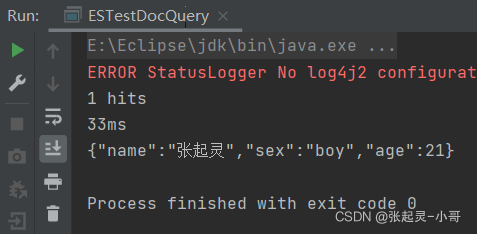
2.13 分页查询
做全量查询,对查询结果进行分页显示,每页2条数据,查询第1页。
查看第几页:(页码 - 1)*每页条数
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermsQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.SortOrder; import java.io.IOException; /** * */ public class ESTestDocQuery { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //3.分页查询 //创建搜索请求对象 SearchRequest request = new SearchRequest(); //设置参数 --- 表示查询哪个索引中的文档内容 request.indices("user"); //构建查询的请求体 SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()); builder.from(0); builder.size(2); //将构建好的查询请求体存入搜索请求对象中 request.source(builder); //发送请求 --- 获取响应 SearchResponse response = esClient.search(request,RequestOptions.DEFAULT); //获取查询到的结果集 SearchHits hits = response.getHits(); System.out.println(hits.getTotalHits()); //结果集的条数 System.out.println(response.getTook()); //总耗时 //遍历结果集 for (SearchHit hit : hits) { System.out.println(hit.getSourceAsString()); } //关闭ES客户端 esClient.close(); } }
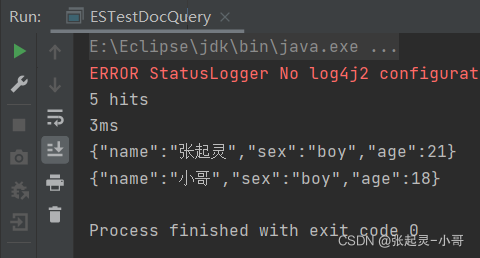
2.14 排序查询
做全量查询,对查询结果中的年龄age字段做降序排序。
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermsQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.SortOrder; import java.io.IOException; /** * */ public class ESTestDocQuery { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //4.对查询结果进行排序 //创建搜索请求对象 SearchRequest request = new SearchRequest(); //设置参数 --- 表示查询哪个索引中的文档内容 request.indices("user"); //构建查询的请求体 SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()); builder.sort("age", SortOrder.DESC); //将构建好的查询请求体存入搜索请求对象中 request.source(builder); //发送请求 --- 获取响应 SearchResponse response = esClient.search(request,RequestOptions.DEFAULT); //获取查询到的结果集 SearchHits hits = response.getHits(); System.out.println(hits.getTotalHits()); //结果集的条数 System.out.println(response.getTook()); //总耗时 //遍历结果集 for (SearchHit hit : hits) { System.out.println(hit.getSourceAsString()); } //关闭ES客户端 esClient.close(); } }
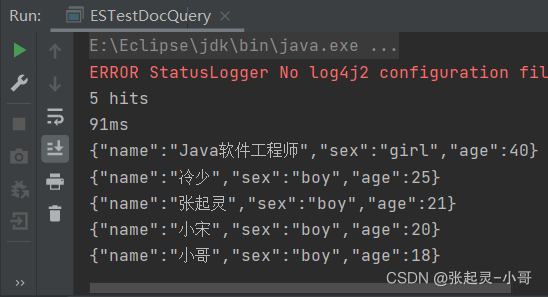
2.15 过滤字段查询
做全量查询,同时排除性别sex字段。
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermsQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.SortOrder; import java.io.IOException; /** * */ public class ESTestDocQuery { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //5.过滤字段 //创建搜索请求对象 SearchRequest request = new SearchRequest(); //设置参数 --- 表示查询哪个索引中的文档内容 request.indices("user"); //构建查询的请求体 SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()); String[] excludes = {"sex"}; String[] includes = {}; builder.fetchSource(includes,excludes); //将构建好的查询请求体存入搜索请求对象中 request.source(builder); //发送请求 --- 获取响应 SearchResponse response = esClient.search(request,RequestOptions.DEFAULT); //获取查询到的结果集 SearchHits hits = response.getHits(); System.out.println(hits.getTotalHits()); //结果集的条数 System.out.println(response.getTook()); //总耗时 //遍历结果集 for (SearchHit hit : hits) { System.out.println(hit.getSourceAsString()); } //关闭ES客户端 esClient.close(); } }
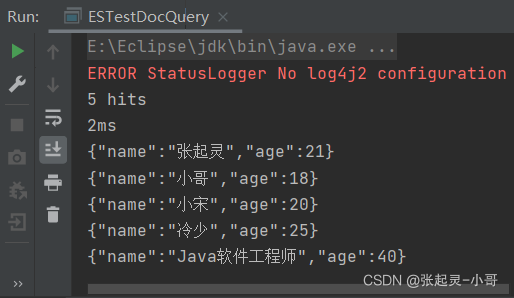
2.16 组合条件查询
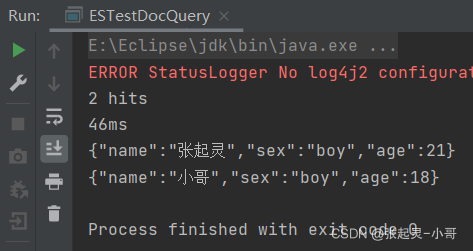
查询年龄 age=18 或者 name=张起灵的文档内容。
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermsQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.SortOrder; import java.io.IOException; /** * */ public class ESTestDocQuery { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //6.组合查询 //创建搜索请求对象 SearchRequest request = new SearchRequest(); //设置参数 --- 表示查询哪个索引中的文档内容 request.indices("user"); //构建查询的请求体 SearchSourceBuilder builder = new SearchSourceBuilder(); BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); boolQueryBuilder.should(QueryBuilders.matchQuery("age",18)); boolQueryBuilder.should(QueryBuilders.matchQuery("name","张起灵")); builder.query(boolQueryBuilder); //将构建好的查询请求体存入搜索请求对象中 request.source(builder); //发送请求 --- 获取响应 SearchResponse response = esClient.search(request,RequestOptions.DEFAULT); //获取查询到的结果集 SearchHits hits = response.getHits(); System.out.println(hits.getTotalHits()); //结果集的条数 System.out.println(response.getTook()); //总耗时 //遍历结果集 for (SearchHit hit : hits) { System.out.println(hit.getSourceAsString()); } //关闭ES客户端 esClient.close(); } }
2.17 范围查询
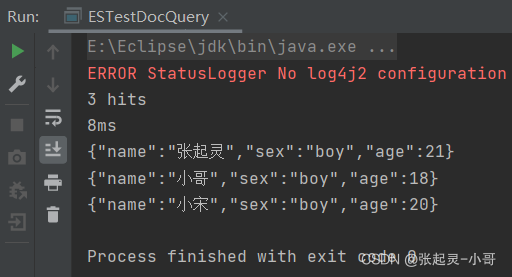
查询年龄age字段大于等于18、小于25的文档内容。
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermsQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.SortOrder; import java.io.IOException; /** * */ public class ESTestDocQuery { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //7.范围查询 //创建搜索请求对象 SearchRequest request = new SearchRequest(); //设置参数 --- 表示查询哪个索引中的文档内容 request.indices("user"); //构建查询的请求体 SearchSourceBuilder builder = new SearchSourceBuilder(); RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("age"); rangeQueryBuilder.gte(18); rangeQueryBuilder.lt(25); builder.query(rangeQueryBuilder); //将构建好的查询请求体存入搜索请求对象中 request.source(builder); //发送请求 --- 获取响应 SearchResponse response = esClient.search(request,RequestOptions.DEFAULT); //获取查询到的结果集 SearchHits hits = response.getHits(); System.out.println(hits.getTotalHits()); //结果集的条数 System.out.println(response.getTook()); //总耗时 //遍历结果集 for (SearchHit hit : hits) { System.out.println(hit.getSourceAsString()); } //关闭ES客户端 esClient.close(); } }
2.18 模糊查询
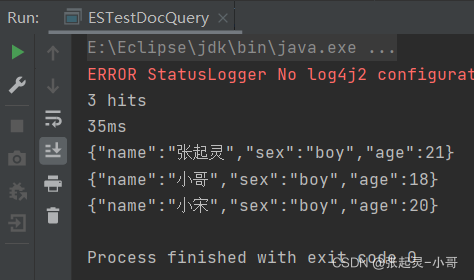
builder.query(QueryBuilders.fuzzyQuery("name","小张").fuzziness(Fuzziness.ONE));最后的这个枚举类型 ONE,表示查询结果中允许与我定义的name字段为小张相差1个字符,也就是说,查询出的结果要么包含小、要么包含张、或者就是小张。
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermsQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.SortOrder; import java.io.IOException; /** * */ public class ESTestDocQuery { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //8.模糊查询 //创建搜索请求对象 SearchRequest request = new SearchRequest(); //设置参数 --- 表示查询哪个索引中的文档内容 request.indices("user"); //构建查询的请求体 SearchSourceBuilder builder = new SearchSourceBuilder(); //FuzzyQueryBuilder fuzzyQueryBuilder = QueryBuilders.fuzzyQuery("name","小张"); //fuzzyQueryBuilder.fuzziness(Fuzziness.ONE); //builder.query(fuzzyQueryBuilder); //上面三行代码 等价于 下面这行代码 builder.query(QueryBuilders.fuzzyQuery("name","小张").fuzziness(Fuzziness.ONE)); //将构建好的查询请求体存入搜索请求对象中 request.source(builder); //发送请求 --- 获取响应 SearchResponse response = esClient.search(request,RequestOptions.DEFAULT); //获取查询到的结果集 SearchHits hits = response.getHits(); System.out.println(hits.getTotalHits()); //结果集的条数 System.out.println(response.getTook()); //总耗时 //遍历结果集 for (SearchHit hit : hits) { System.out.println(hit.getSourceAsString()); } //关闭ES客户端 esClient.close(); } }
2.19 聚合查询
查询age字段,年龄最大的文档内容。
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermsQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.SortOrder; import java.io.IOException; /** * */ public class ESTestDocQuery { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //9.聚合查询 //创建搜索请求对象 SearchRequest request = new SearchRequest(); //设置参数 --- 表示查询哪个索引中的文档内容 request.indices("user"); //构建查询的请求体 SearchSourceBuilder builder = new SearchSourceBuilder(); AggregationBuilder aggregationBuilder = AggregationBuilders.max("maxAge").field("age"); builder.aggregation(aggregationBuilder); //将构建好的查询请求体存入搜索请求对象中 request.source(builder); //发送请求 --- 获取响应 SearchResponse response = esClient.search(request,RequestOptions.DEFAULT); //获取查询到的结果集 SearchHits hits = response.getHits(); System.out.println(hits.getTotalHits()); //结果集的条数 System.out.println(response.getTook()); //总耗时 //遍历结果集 for (SearchHit hit : hits) { System.out.println(hit.getSourceAsString()); } //关闭ES客户端 esClient.close(); } }
2.20 分组查询
根据age年龄字段进行group分组查询。
package com.szh.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermsQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.aggregations.AggregationBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.SortOrder; import java.io.IOException; /** * */ public class ESTestDocQuery { public static void main(String[] args) throws IOException { //创建ES客户端 RestHighLevelClient esClient = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost",9200,"http")) ); //10.分组查询 //创建搜索请求对象 SearchRequest request = new SearchRequest(); //设置参数 --- 表示查询哪个索引中的文档内容 request.indices("user"); //构建查询的请求体 SearchSourceBuilder builder = new SearchSourceBuilder(); AggregationBuilder aggregationBuilder = AggregationBuilders.terms("ageGroup").field("age"); builder.aggregation(aggregationBuilder); //将构建好的查询请求体存入搜索请求对象中 request.source(builder); //发送请求 --- 获取响应 SearchResponse response = esClient.search(request,RequestOptions.DEFAULT); //获取查询到的结果集 SearchHits hits = response.getHits(); System.out.println(hits.getTotalHits()); //结果集的条数 System.out.println(response.getTook()); //总耗时 //遍历结果集 for (SearchHit hit : hits) { System.out.println(hit.getSourceAsString()); } //关闭ES客户端 esClient.close(); } }

