文章目录:
1.序列化和反序列化的概念
把对象转换为字节序列的过程称为对象的序列化。
把字节序列恢复为对象的过程称为对象的反序列化。
对象的序列化主要有两种用途:
1)把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
2)在网络上传送对象的字节序列。在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
2.JDK类库中有关序列化和反序列化的API
java.io.ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
只有实现了Serializable和Externalizable接口的类的对象才能被序列化。Externalizable接口继承自 Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以采用默认的序列化方式。
对象序列化包括如下步骤:
1)创建一个对象输出流,它可以包装一个其他类型的目标输出流,如文件输出流;
2)通过对象输出流的writeObject()方法写对象。
对象反序列化的步骤如下:
1)创建一个对象输入流,它可以包装一个其他类型的源输入流,如文件输入流;
2)通过对象输入流的readObject()方法读取对象。
3.实例一:序列化单个对象
首先写一个Student实体类
package com.songzihao.bean; import java.io.Serial; import java.io.Serializable; /** * */ public class Student implements Serializable { @Serial private static final long serialVersionUID = 3766644755010787032L; private Integer id; private String name; public Student() { } public Student(Integer id, String name) { this.id = id; this.name = name; } //getter and setter //toString }
执行序列化操作。
package com.songzihao.bean; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; /** * 1.参与序列化和反序列化的对象,必须实现 java.io.Serializable 接口 * public interface Serializable { * } * 这是一个标志性接口,其中什么方法也没有,起到了标识标志的作用 * Serializable接口是给Java虚拟机参考的,Java虚拟机看到这个接口之后,会为这个类自动生成一个序列化版本号 */ public class ObjectOutputStreamTest { public static void main(String[] args) throws IOException { Student student=new Student(666,"张起灵"); //序列化 ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("student")); //序列化对象 oos.writeObject(student); //刷新 oos.flush(); //关闭 oos.close(); } }

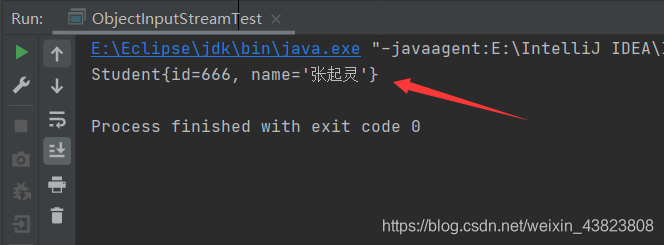
执行反序列化操作。
package com.songzihao.bean; import java.io.FileInputStream; import java.io.IOException; import java.io.ObjectInputStream; /** * */ public class ObjectInputStreamTest { public static void main(String[] args) throws IOException, ClassNotFoundException { //反序列化 ObjectInputStream ois=new ObjectInputStream(new FileInputStream("student")); Student student= (Student) ois.readObject(); //反序列化回来的是一个Java对象,所以这里调用了对象的toString方法 System.out.println(student); //关闭 ois.close(); } }
4.实例二:序列化多个对象(一个List集合)
首先写一个User实体类。
package com.songzihao.entity; import java.io.Serial; import java.io.Serializable; /** * */ public class User implements Serializable { @Serial private static final long serialVersionUID = -3558401670195225456L; private Integer id; //transient关键字表示游离的,不参与序列化 private transient String name; public User() { } public User(Integer id, String name) { this.id = id; this.name = name; } //getter and setter //toString }
执行序列化操作。
package com.songzihao.entity; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; import java.util.ArrayList; import java.util.List; /** * */ public class ObjectOutputStreamTest { public static void main(String[] args) throws IOException { //创建一个List集合 List<User> userList=new ArrayList<>(); userList.add(new User(1,"张起灵")); userList.add(new User(2,"小哥")); userList.add(new User(3,"闷油瓶")); //序列化多个对象 ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("userList")); oos.writeObject(userList); oos.flush(); oos.close(); } }

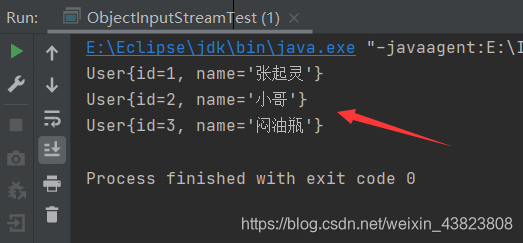
执行反序列化操作。
package com.songzihao.entity; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.ObjectInputStream; import java.util.List; /** * */ public class ObjectInputStreamTest { public static void main(String[] args) throws IOException, ClassNotFoundException { ObjectInputStream ois=new ObjectInputStream(new FileInputStream("userList")); List<User> userList= (List<User>) ois.readObject(); for (User user : userList) { System.out.println(user); } ois.close(); } }
5.实例三:关于序列化版本号
在上面两个实例中,我们会看到实体类中总会出现这样一行代码:
private static final long serialVersionUID = -3558401670195225456L;
这个东西其实就是序列化版本号,那么为什么实现 Serializable 接口的类都需要有一个这样的序列化版本号呢?
下面我们先来看一下如果不添加序列化版本号会出现什么问题。
5.1 不添加序列化版本号
package com.songzihao.domain; import java.io.Serial; import java.io.Serializable; public class Person implements Serializable { //Java虚拟机看到实现Serializable接口之后,会自动生成一个序列化版本号 //假设这两个属性是十年前写好的 private String name; private String sex; private Integer age; public Person() { } public Person(String name, String sex) { this.name = name; this.sex = sex; } //getter and setter //toString }
依次执行序列化和反序列化操作。
package com.songzihao.domain; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; /** * */ public class ObjectOutputStreamTest { public static void main(String[] args) throws IOException { Person person=new Person("张起灵","男"); ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("person")); oos.writeObject(person); oos.flush(); oos.close(); } }
package com.songzihao.domain; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.ObjectInputStream; public class ObjectInputStreamTest { public static void main(String[] args) throws IOException, ClassNotFoundException { ObjectInputStream ois=new ObjectInputStream(new FileInputStream("person")); Person person= (Person) ois.readObject(); System.out.println("person = " + person); ois.close(); } }


可以在上面的输出结果中,看到正确无误的实现了序列化和反序列化操作。
那么假如说,这个Person实体类是我昨天编写的,其中只有 name、age、sex三个属性,到今天,我突然想给这个类添加一个 hobby 属性,然后再次执行反序列化操作行不行呢?(因为我们已经执行过序列化操作了,所以这里只需要执行反序列化操作,看看能不能从硬盘中拿到最新的类文件中的内容就行了)
下面是修改之后的Person实体类。
package com.songzihao.domain; import java.io.Serial; import java.io.Serializable; public class Person implements Serializable { //Java虚拟机看到实现Serializable接口之后,会自动生成一个序列化版本号 //假设这两个属性是昨天写好的 private String name; private String sex; private Integer age; //今天,又添加一个hobby属性 //源代码改动之后,需要重新编译,进而生成全新的字节码文件 //并且Java虚拟机会再次生成一个新的序列化版本号 //此时,回到反序列化代码中,运行就会报错!!! private String hobby; public Person() { } public Person(String name, String sex) { this.name = name; this.sex = sex; } //getter and setter //toString }
序列化和反序列化操作的代码和上面的是一样的,这里不再给出代码,直接给出执行反序列化之后的运行结果。可以看到,代码运行报错了!!!
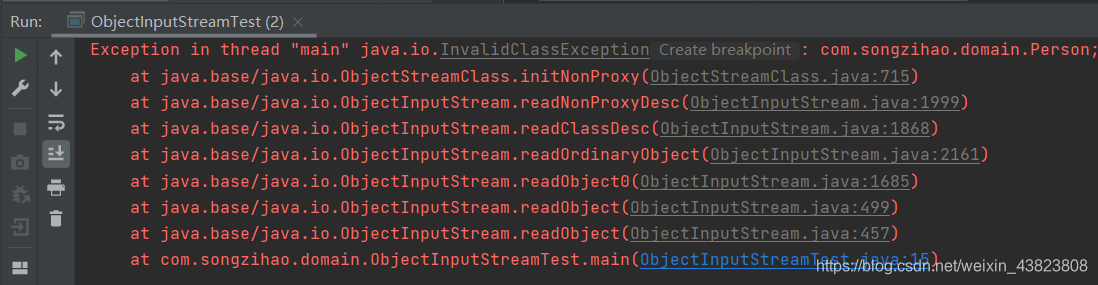
/** * java.io.InvalidClassException: * com.songzihao.domain.Person; * local class incompatible: * stream classdesc serialVersionUID = -2636134556316626889, (昨天的序列化版本号) * local class serialVersionUID = -5103901396738868535 (今天的序列化版本号) * 两次生成的序列化版本号不一致 */
在这里,就要聊一聊Java中是通过什么来区分类的?
1. 首先通过类名进行比对,如果类名不一样,肯定就不是同一个类。
2. 如果类名一样,怎么办呢?这就需要用到——序列化版本号来区分!!!
也就是说,我昨天写的那个Person类,Java虚拟机给我生成了一个序列化版本号,此时我执行序列化和反序列化操作,完全可以将类文件内容通过对象输出流写入到硬盘中,也完全可以通过对象输入流从硬盘中读取到之前写入的内容。然而我今天修改Person类添加了一个属性,Java虚拟机又给我生成了一个序列化版本号,这两个序列化版本号是不一样的,也就是说这两个类虽然同名(但序列化版本号不一样,所以就不是同一个类),这个时候我再去执行反序列化操作,读取到的是今天新生成的这个序列化版本号,肯定就报错了啊,因为这并不是昨天的那个序列化版本号,内容一改变,自然就不一样了呗!!!
说白了,这种自动生成序列化版本号的方法有一个缺陷就是:代码不能修改!!!
下面,我们来聊聊关于手动指定序列化版本号serialVersionUID:👇👇👇
serialVersionUID的取值是Java运行时环境根据类的内部细节自动生成的。如果对类的源代码作了修改,再重新编译,新生成的类文件的serialVersionUID的取值有可能也会发生变化。
每个类的serialVersionUID的默认值完全依赖于Java编译器的实现,对于同一个类,用不同的Java编译器编译,有可能会导致不同的 serialVersionUID,也有可能相同。
为了提高serialVersionUID的独立性和确定性,强烈建议在一个可序列化类中显示的定义serialVersionUID,为它赋予明确的值。
在下面的代码中,我们再次执行反序列化操作。
package com.songzihao.domain; import java.io.Serial; import java.io.Serializable; /** * 凡是一个类实现了Serializable接口,建议给该类提供一个固定不变的序列化版本号 * 这样,以后这个类即使代码修改了,但是序列化版本号不变,Java虚拟机会认为这是同一个类 */ public class Person implements Serializable { @Serial private static final long serialVersionUID = -6374292363662261865L; private String name; private String sex; private Integer age; // private String hobby; public Person() { } public Person(String name, String sex) { this.name = name; this.sex = sex; } //getter and setter //toString }
依次执行序列化和反序列化。可以看到代码正常执行。
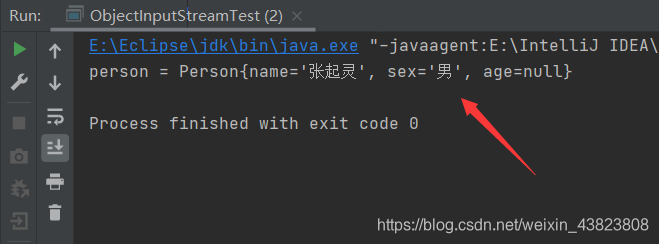
在Person类中,添加一个hobby属性,再次执行反序列化操作。(因为上一步已经执行过序列化了)
package com.songzihao.domain; import java.io.Serial; import java.io.Serializable; /** * 凡是一个类实现了Serializable接口,建议给该类提供一个固定不变的序列化版本号 * 这样,以后这个类即使代码修改了,但是序列化版本号不变,Java虚拟机会认为这是同一个类 */ public class Person implements Serializable { @Serial private static final long serialVersionUID = -6374292363662261865L; private String name; private String sex; private Integer age; private String hobby; public Person() { } public Person(String name, String sex) { this.name = name; this.sex = sex; } //getter and setter //toString }
可以看到,代码仍然正确无误的执行。这就是手动指定序列化版本号的好处!!!即使代码修改也没任何问题,因为序列化版本号固定在此,类就是唯一的,无论何时我从硬盘中读取数据均可!!!
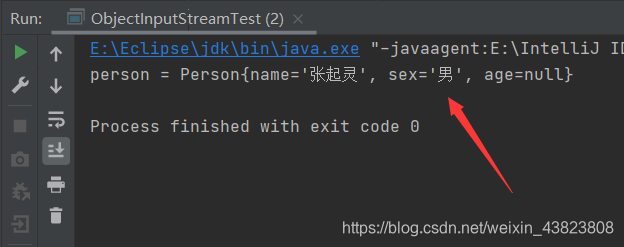
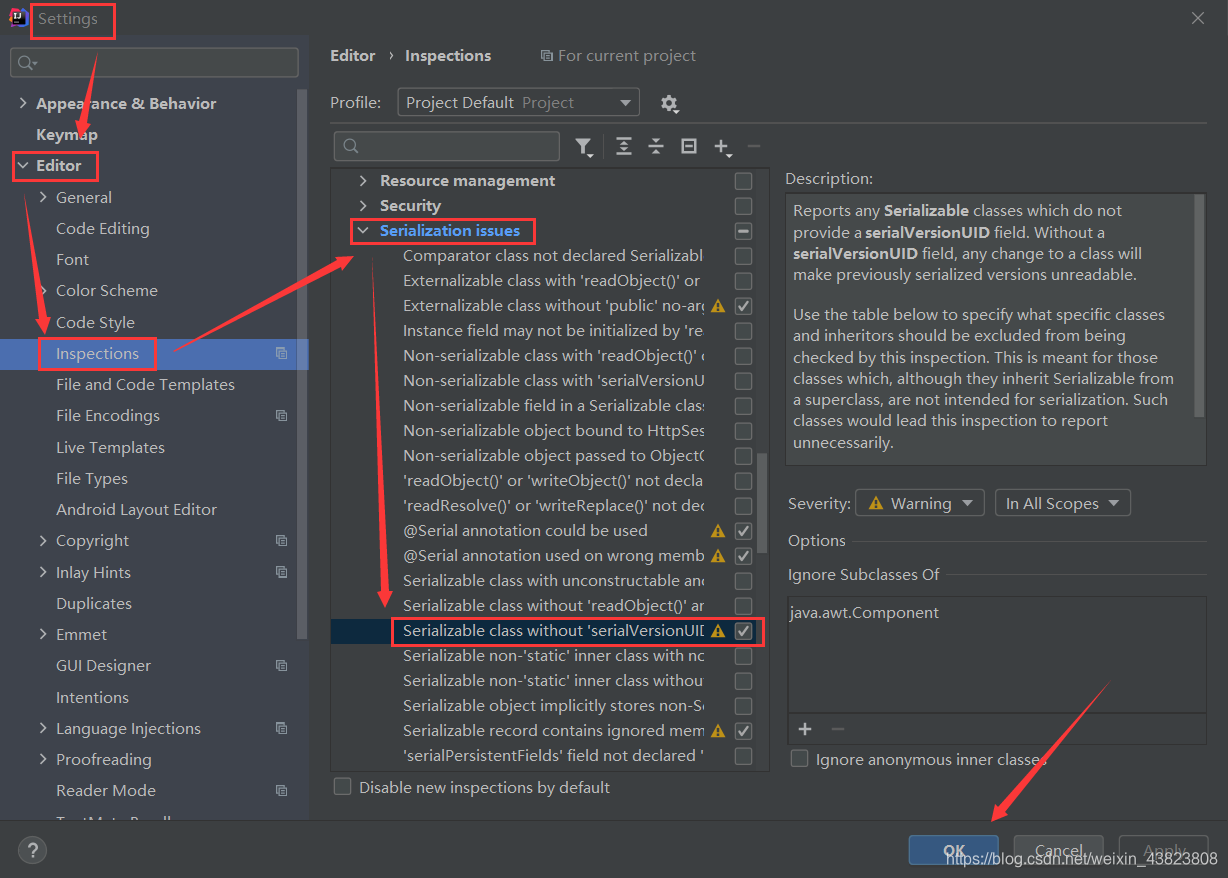
6.关于IDEA中设置手动添加序列化版本号的方法